Парсер StAX XML в Java
В этой статье основное внимание уделяется синтаксическому анализу XML-файла в Java.
XML: XML означает расширяемый язык разметки. Он был разработан для хранения и передачи данных. Он был разработан, чтобы быть читаемым как человеком, так и машиной. Вот почему цели разработки XML делают упор на простоту, универсальность и удобство использования в Интернете.
Почему StAX вместо SAX?
- SAX : SAX - это API модели push, что означает, что именно API вызывает ваш обработчик, а не ваш обработчик вызывает API. Таким образом, синтаксический анализатор SAX «проталкивает» события в ваш обработчик. С этой push-моделью API у вас нет контроля над тем, как и когда анализатор выполняет итерацию по файлу. Как только вы запускаете синтаксический анализатор, он выполняет итерацию до конца, вызывая ваш обработчик для каждого без исключения XML-события во входном XML-документе.
SAX Parser -> Обработчик
- StAX : Модель вытягивания StAX означает, что именно ваш класс «обработчика» вызывает API парсера, а не наоборот. Таким образом, ваш класс обработчика контролирует, когда парсер должен перейти к следующему событию во входных данных. Другими словами, ваш обработчик «вытягивает» XML-события из анализатора. Кроме того, вы можете остановить синтаксический анализ в любой момент. Синтаксический анализатор StAX обычно используется вместо читателя файлов, когда ввод или база данных задаются в виде автономного или онлайн-файла xml. Модель вытягивания резюмируется следующим образом:
Обработчик -> Парсер StAX
Также синтаксический анализатор StAX может читать и писать в XML-документы, а SAX может только читать. SAX обеспечивает проверку схемы, т.е. если теги правильно вложены или правильно написан XML, но StAX не предоставляет такого метода проверки схемы.
Выполнение
Идея работы парсера StAX: 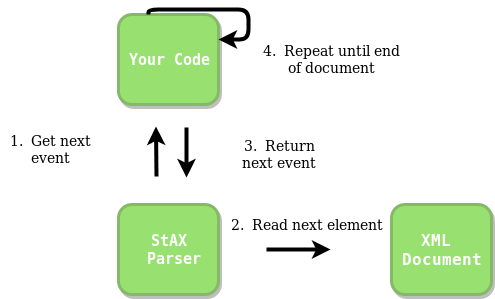
Входной файл: это образец входного файла, созданный автором в качестве примера, чтобы показать, как используется синтаксический анализатор StAX. Сохраните его как data.xml и запустите код. Файлы базы данных XML обычно имеют большой размер и содержат множество тегов, вложенных друг в друга.
<company class="geeksforgeeks.org"> <name>Kunal Sharma</name> <title>Student</title> <email>kunal@example.com</email> <phone>(202) 456-1414</phone> </company> // Java Code to implement StAX parserimport java.io.File;import java.io.FileNotFoundException;import java.io.FileReader;import java.util.Iterator;import javax.xml.namespace.QName;import javax.xml.stream.XMLEventReader;import javax.xml.stream.XMLInputFactory;import javax.xml.stream.XMLStreamException;import javax.xml.stream.events.*; public class Main{ private static boolean bcompany,btitle,bname,bemail,bphone; public static void main(String[] args) throws FileNotFoundException, XMLStreamException { // Create a File object with appropriate xml file name File file = new File( "data.xml" ); // Function for accessing the data parser(file); } public static void parser(File file) throws FileNotFoundException, XMLStreamException { // Variables to make sure whether a element // in the xml is being accessed or not // if false that means elements is // not been used currently , if true the element or the // tag is being used currently bcompany = btitle = bname = bemail = bphone = false ; // Instance of the class which helps on reading tags XMLInputFactory factory = XMLInputFactory.newInstance(); // Initializing the handler to access the tags in the XML file XMLEventReader eventReader = factory.createXMLEventReader( new FileReader(file)); // Checking the availabilty of the next tag while (eventReader.hasNext()) { // Event is actually the tag . It is of 3 types // <name> = StartEvent // </name> = EndEvent // data between the StartEvent and the EndEvent // which is Characters Event XMLEvent event = eventReader.nextEvent(); // This will trigger when the tag is of type <...> if (event.isStartElement()) { StartElement element = (StartElement)event; // Iterator for accessing the metadeta related // the tag started. // Here, it would name of the company Iterator<Attribute> iterator = element.getAttributes(); while (iterator.hasNext()) { Attribute attribute = iterator.next(); QName name = attribute.getName(); String value = attribute.getValue(); System.out.println(name+ " = " + value); } // Checking which tag needs to be opened for reading. // If the tag matches then the boolean of that tag // is set to be true. if (element.getName().toString().equalsIgnoreCase( "comapany" )) { bcompany = true ; } if (element.getName().toString().equalsIgnoreCase( "title" )) { btitle = true ; } if (element.getName().toString().equalsIgnoreCase( "name" )) { bname = true ; } if (element.getName().toString().equalsIgnoreCase( "email" )) { bemail = true ; } if (element.getName().toString().equalsIgnoreCase( "phone" )) { bphone = true ; } } // This will be triggered when the tag is of type </...> if (event.isEndElement()) { EndElement element = (EndElement) event; // Checking which tag needs to be closed after reading. // If the tag matches then the boolean of that tag is // set to be false. if (element.getName().toString().equalsIgnoreCase( "comapany" )) { bcompany = false ; } if (element.getName().toString().equalsIgnoreCase( "title" )) { btitle = false ; } if (element.getName().toString().equalsIgnoreCase( "name" )) { bname = false ; } if (element.getName().toString().equalsIgnoreCase( "email" )) { bemail = false ; } if (element.getName().toString().equalsIgnoreCase( "phone" )) { bphone = false ; } } // Triggered when there is data after the tag which is // currently opened. if (event.isCharacters()) { // Depending upon the tag opened the data is retrieved . Characters element = (Characters) event; if (bcompany) { System.out.println(element.getData()); } if (btitle) { System.out.println(element.getData()); } if (bname) { System.out.println(element.getData()); } if (bemail) { System.out.println(element.getData()); } if (bphone) { System.out.println(element.getData()); } } } }} |
Выход :
name = geeksforgeeks.org Кунал Шарма Ученик kunal@example.com (202) 456-1414
Как работает StAX в приведенном выше коде?
После создания eventReader в приведенном выше коде с помощью фабричного шаблона для создания читателя XML-файлов он в основном начинает с чтения тега <…>. Как только появляется тег <…>, для логической переменной устанавливается значение true, указывающее, что тег был открыт. Это сопоставление тегов выполняется путем определения того, является ли это начальным или конечным тегом. Поскольку тег <…> указывает начало, поэтому ему соответствует StartElement. Далее идет часть чтения данных. На следующем этапе он считывает символ / данные, сопоставляя элемент по isCharacters, это делается только в том случае, если требуемый начальный тег открыт или его логическая переменная установлена в значение true. После этого происходит закрытие элемента, обозначенного тегом </…>. Как только он встречает </ ..>, он проверяет, какой из элементов был открыт или установлен в значение true, и устанавливает для этого логического элемента значение false или закрывает его.
Обычно каждое событие сначала открывает тег, читает его данные, а затем закрывает его.
- Рекомендации :
- https://docs.oracle.com/javase/tutorial/jaxp/sax/parsing.html
- https://docs.oracle.com/cd/E17802_01/webservices/webservices/docs/1.6/tutorial/doc/SJSXP2.html
Эта статья предоставлена Куналом Шармой . Если вам нравится GeeksforGeeks, и вы хотели бы внести свой вклад, вы также можете написать статью с помощью provide.geeksforgeeks.org или отправить ее по электронной почте на deposit@geeksforgeeks.org. Посмотрите, как ваша статья появляется на главной странице GeeksforGeeks, и помогите другим гикам.
Пожалуйста, напишите комментарии, если вы обнаружите что-то неправильное, или вы хотите поделиться дополнительной информацией по теме, обсужденной выше.
Вниманию читателя! Не прекращайте учиться сейчас. Ознакомьтесь со всеми важными концепциями Java Foundation и коллекций с помощью курса "Основы Java и Java Collections" по приемлемой для студентов цене и будьте готовы к работе в отрасли. Чтобы завершить подготовку от изучения языка к DS Algo и многому другому, см. Полный курс подготовки к собеседованию .