Обработка сбоев в распределенной системе
Распределенная система — это группа независимых компьютеров, которые кажутся клиентам единой целостной системой. В любой распределенной системе есть несколько компонентов, которые работают вместе для выполнения задачи. По мере того, как система становится более сложной и содержит больше компонентов, возрастает вероятность отказа, что приводит к снижению надежности. Другими словами, мы можем сказать, что в распределенной системе всегда будут системы, которые не работают, в то время как другие функционируют нормально. Это известно как частичный отказ. Частичные сбои непредсказуемы, поскольку время, необходимое сообщению для прохождения по сети, не является детерминированным, и у нас нет возможности узнать, удалось что-либо или нет. В результате мы понятия не имеем, какие системы вышли из строя в промежутке времени, и мы не знаем, отказала система или нет. Из-за этого работать с распределенными системами сложно. В распределенных системах возможны частичные сбои, такие как сбои узлов или сбои коммуникационных соединений. В результате такие ошибки во время межпроцессного взаимодействия могут привести к следующим проблемам:
- Запросить потерю сообщения
- Потеря ответного сообщения
- Неудачное выполнение запроса
- Возможно, ваш запрос был отложен.
- Удаленный узел взял перерыв (для сборки мусора).
- Запрос был обработан удаленным узлом, но ответ был потерян в сети.
- Поскольку наша сеть перегружена, ответы задерживаются.
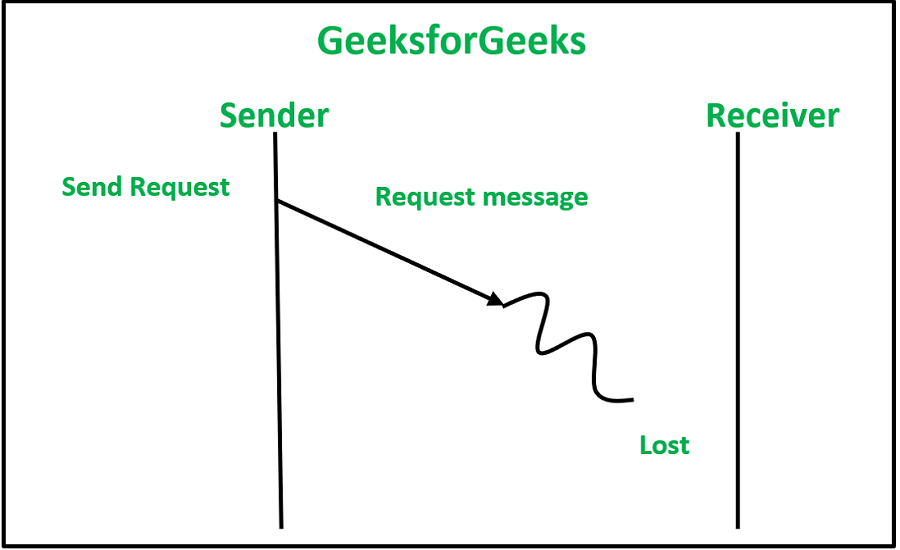
1. Потеря сообщения запроса: эта потеря может произойти, когда канал связи отправитель-получатель выходит из строя, или другой причиной может быть то, что узел на стороне получателя не включен в то время, когда сообщение запроса достигает его.
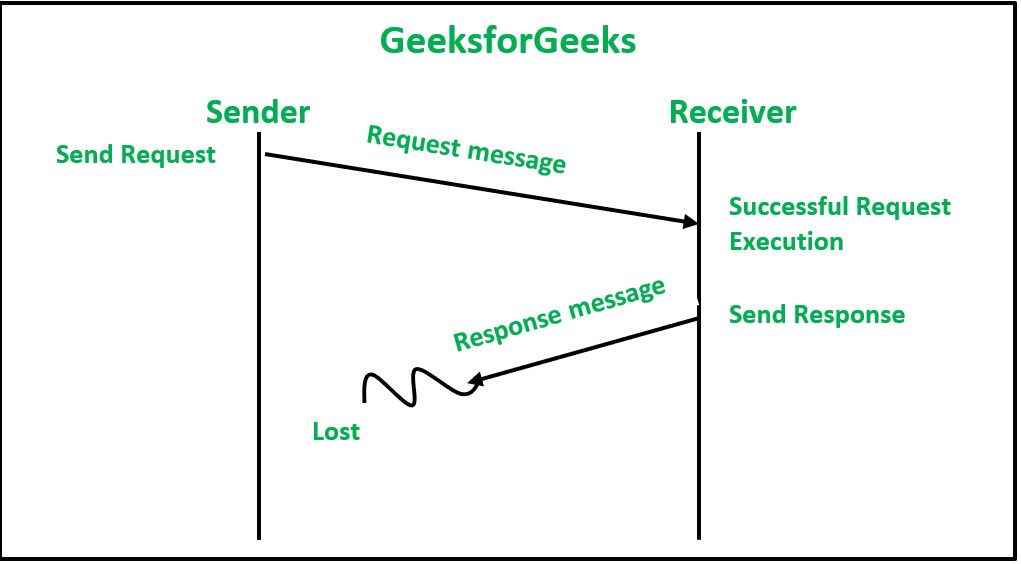
2. Потеря ответного сообщения: эта потеря может произойти, когда канал связи отправитель-получатель выходит из строя, или другая причина может заключаться в том, что узел на стороне отправителя не включен в то время, когда ответное сообщение достигает его.
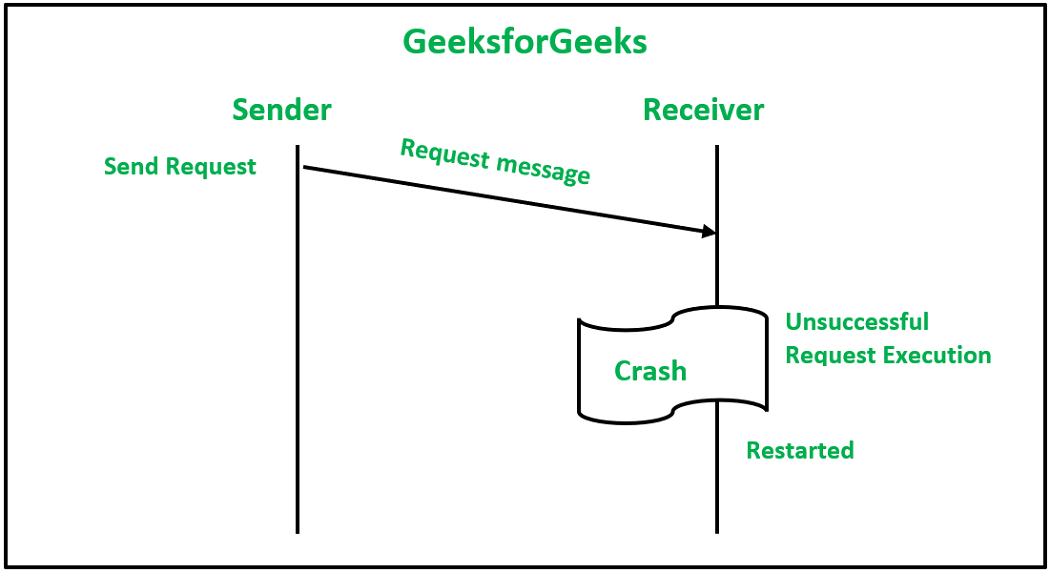
3. Неудачное выполнение запроса: Это происходит, когда узел получателя выходит из строя во время обработки запроса.
Для решения этих проблем надежный протокол IPC используется системой передачи сообщений, которая имеет дело с концепциями повторной передачи сообщений внутри через фиксированный интервал времени, а ядро на принимающей стороне возвращает сообщение подтверждения в ядро на отправляющей машине.
Следующий надежный протокол IPC используется для связи клиент-сервер между двумя процессами:
- Надежный протокол IPC с четырьмя сообщениями
- Надежный протокол IPC с тремя сообщениями
- Надежный протокол IPC с двумя сообщениями
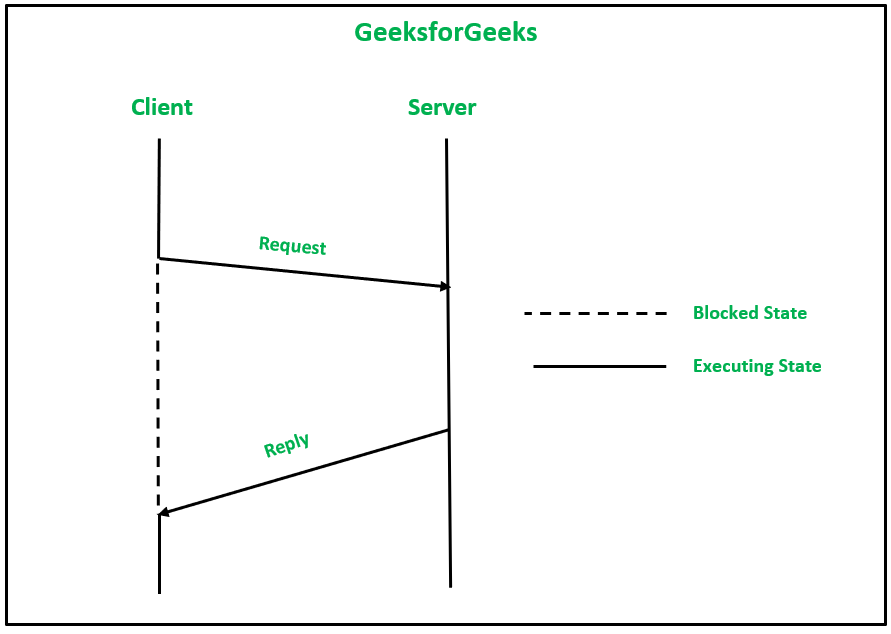
1. Надежный протокол IPC с четырьмя сообщениями: в этом клиент-серверном взаимодействии между двумя процессами происходит следующим образом:
- Сообщение запроса отправляется от клиента к серверу.
- После получения сообщения запроса, сообщение подтверждения отправляется из ядра сервера в ядро клиентской машины. Повторная передача сообщения-запроса также осуществляется ядром клиентской машины в случае, если подтверждение не получено в установленные сроки.
- Ответное сообщение отправляется клиенту, когда сервер обслужил запрос клиента. Сообщение также содержит результат обработки.
- Теперь от ядра клиентской стороны к ядру серверной машины отправляется подтверждающее сообщение, подтверждающее получение ответа. Повторная передача ответного сообщения также осуществляется ядром машины-сервера в случае, если подтверждение не получено в установленные сроки.
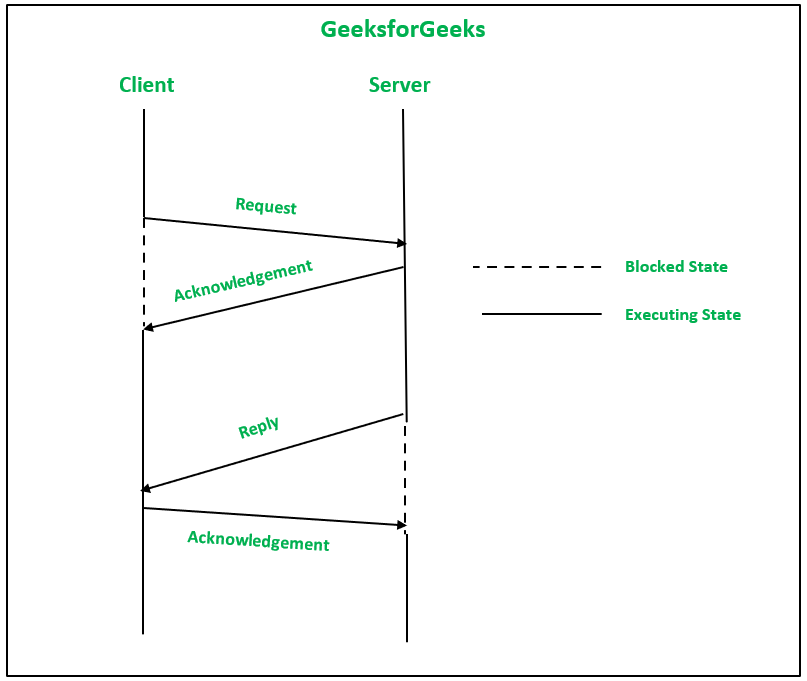
2. Надежный протокол IPC с тремя сообщениями. Когда клиентский процесс получает успешный ответ, он гарантирует, что сообщение запроса было получено сервером при взаимодействии клиент-сервер. Итак, он основан на этой концепции:
- Сообщение запроса отправляется от клиента к серверу
- После получения сообщения-запроса с сервера клиенту отправляется ответное сообщение, содержащее результаты обработки. Повторная передача сообщения-запроса также осуществляется ядром клиентской машины в случае, если ответ не получен в установленные сроки.
- Ответное сообщение отправляется клиенту, когда сервер обслужил запрос клиента. Сообщение также содержит результат обработки. Теперь ядро на стороне клиента отправляет подтверждение ядру на стороне сервера. Повторная передача ответного сообщения осуществляется также ядром серверной машины в случае, если подтверждение не получено в установленные сроки.
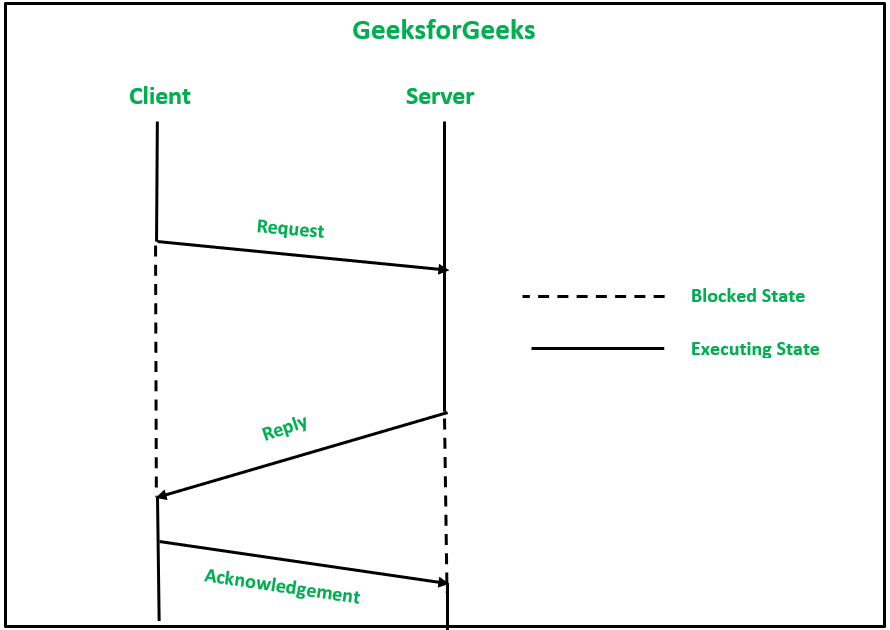
Проблема может возникнуть, если обработка запроса занимает много времени. Поскольку повторная передача сообщения может быть выполнена только после фиксированного набора интервалов, которые обычно устанавливаются на большое количество, чтобы избежать расточительной повторной передачи. С другой стороны, если для обработки запроса не установлено значительное время, это может привести к многократной отправке сообщений запроса. Чтобы решить эту проблему, используйте следующий протокол:
- Клиент отправляет серверу сообщение запроса.
- Ядро запускает таймер, как только сервер получает запрос. Когда клиент получает ответное сообщение со стороны сервера после обработки запроса, это служит подтверждением сообщения запроса. В противном случае сервер отправляет отдельное подтверждение для подтверждения сообщения запроса. Повторная передача также должна быть выполнена, если подтверждение не получено в течение периода ожидания.
- Когда ответное сообщение получено клиентом, ядро клиента отправляет сообщение подтверждения ядру сервера. Повторная передача ответного сообщения будет выполняться ядром сервера только в том случае, если подтверждающее сообщение не получено в течение периода ожидания.
3. Надежный протокол IPC с двумя сообщениями: Надежный протокол IPC с двумя сообщениями используется для связи клиент-сервер между двумя процессами. Для его реализации может быть разработана система передачи сообщений:
- Клиент отправляет запрос на сервер. Когда запрос отправлен, t блокируется до тех пор, пока сервер не ответит.
- Когда сервер завершает обработку запроса клиента, он отправляет клиенту ответное сообщение (включая результат обработки). Ядро клиентской машины повторно передает сообщение запроса, если ответ не получен в течение интервала времени ожидания.
Идемпотентность:
Идемпотентность по существу относится к «повторяемости». Это подразумевает выполнение идемпотентной операции несколько раз с одними и теми же параметрами, генерирует одинаковые результаты без побочных эффектов.
Отслеживание потерянных и вышедших из строя пакетов требуется в сообщениях мультидатаграмм:
Полная передача подразумевает, что все пакеты сообщения были получены процессом, которому оно было отправлено, поскольку каждый пакет имеет решающее значение для эффективного завершения передачи мультидатаграммного сообщения. Таким образом, простой подход состоит в том, чтобы распознавать каждый пакет независимо (это называется протоколом остановки и ожидания). Второй подход в сообщении с несколькими дейтаграммами (называемый протоколом blast) заключается в использовании одного пакета подтверждения для всех пакетов. Однако при использовании этого метода сбой узла или сбой канала связи могут привести к следующим проблемам:
- Во время связи один или несколько пакетов мультидатаграммного сообщения теряются.
- Неупорядоченный прием пакетов.
Чтобы справиться с этими проблемами, для идентификации пакетов сообщений используется подход с битовой картой.
Существуют и другие виды сбоев, которые могут возникнуть в распределенной системе:
- Серверы приложений могут выходить из строя по разным причинам, включая перебои в работе центра обработки данных, чрезмерную загрузку ЦП/памяти, дефекты кода приложений, перебои в подаче электроэнергии, стихийные бедствия и т. д.
- Службы в распределенных системах могут обмениваться данными напрямую по сети с использованием HTTP/TCP. Неудачная связь между двумя службами может произойти по разным причинам, включая недоступность службы, проблемы с сетью, сбой зависимости и т. д. В результате каскадного эффекта одна из служб может не выполнить свои обязательства, что может привести к сбою всей системы.
- Это также может случиться, когда приложение не может читать или писать в базу данных, тогда оно считается неудачным, и это может произойти по разным причинам, включая проблемы с сетью, которые делают базу данных недоступной, засорение базы данных из-за интенсивного использования ЦП/памяти и серверы баз данных выходят из строя. Поскольку данные являются наиболее важным компонентом любой системы, устранение сбоев базы данных имеет решающее значение.
- Сообщения и события доставляются с использованием очередей и потоков, которые являются важными компонентами. Проблемы с инфраструктурой, недоступность нескольких узлов, несоблюдение минимального количества синхронизированных реплик и т. д. могут вызывать эти сбои.
Вышеупомянутые другие проблемы сбоя в распределенных системах можно решить следующим образом:
- Если узел в сервере приложений выходит из строя, то его необходимо заменить новым узлом в ротации, которая осуществляется с помощью автоматизированных скриптов или ручного взаимодействия. Резервные кластеры можно использовать, если весь кластер или сервер приложений выйдет из строя. Это делается путем направления трафика на резервный кластер, расположенный в отдельном центре обработки данных в том же или другом регионе.
- Если что-то пойдет не так, повторите попытку в зависимости от политики повторных попыток. Повторные попытки сокращают время восстановления при периодических сбоях, но они могут усугубить проблему, поскольку для восстановления сокращенной системы может потребоваться некоторое время.
- Кэши также можно использовать в качестве запасных вариантов для хранения данных для многочисленных повторяющихся запросов, гарантируя, что в случае сбоя нисходящего потока согласованные данные из кеша в конечном итоге будут предоставлены. Однако, поскольку кэши могут быть полезны не во всех сценариях использования, сбои следует обрабатывать осторожно, т. е. вместо отправки ошибки следует возвращать правильный ухудшенный ответ.
- Реакция на сбои базы данных зависит от критичности обрабатываемых данных: наличие резервной базы данных со всеми данными, реплицированными из основной базы данных, снижает риск единой точки отказа, и эта избыточная база данных может использоваться для обслуживания требований к данным. пока основная база данных не будет восстановлена. Пока база данных не будет готова снова взять на себя нагрузку, приложение может использовать резервные методы для предстоящих запросов. Чтения могут быть предоставлены либо из кэша, либо из избыточной базы данных.
- Поместите сообщение в повторяющийся поток или очередь, чтобы увеличить избыточность. Даже транзакционные коммуникации не будут потеряны в результате этого. Создание ресурсов в отдельных центрах обработки данных и зонах доступности — лучший способ добиться избыточности. Если сообщение относится к уровню 3, его можно ненадолго сохранить в журнале транзакций. Приложение может периодически повторять попытки поместить сообщения в журналы транзакций, пока поток не восстановится.