Обнаружение мультиколлинеарности с помощью VIF - Python
Мультиколлинеарность возникает, когда в модели множественной регрессии есть две или более независимых переменных, которые имеют между собой высокую корреляцию. Когда некоторые характеристики сильно коррелированы, у нас могут возникнуть трудности с различением их индивидуальных эффектов на зависимую переменную. Мультиколлинеарность может быть обнаружена с помощью различных методов, одним из которых является фактор инфляции дисперсии ( VIF ).
В методе VIF мы выбираем каждую функцию и сравниваем ее со всеми другими функциями. Для каждой регрессии коэффициент рассчитывается как:
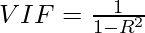
Где R-квадрат - коэффициент детерминации линейной регрессии. Его значение находится в диапазоне от 0 до 1.
Как видно из формулы, чем больше значение R-квадрат, тем больше VIF. Следовательно, больший VIF означает большую корреляцию. Это согласуется с тем фактом, что более высокое значение R-квадрата означает более сильную коллинеарность. Как правило, VIF выше 5 указывает на высокую мультиколлинеарность.
Реализация VIF с использованием статистических моделей:
statsmodels предоставляет функцию с именем variance_inflation_factor () для вычисления VIF.
Syntax : statsmodels.stats.outliers_influence.variance_inflation_factor(exog, exog_idx)
Parameters :
- exog : an array containing features on which linear regression is performed.
- exog_idx : index of the additional feature whose influence on the other features is to be measured.
Давайте посмотрим на пример реализации метода в этом наборе данных.
Набор данных:
Набор данных, используемый в примере ниже, содержит рост, вес, пол и индекс массы тела для 500 человек. Здесь зависимой переменной является индекс .
Python3
import pandas as pd # the datasetdata = pd.read_csv( 'BMI.csv' ) # printing first few rowsprint (data.head()) |
Выход :
Пол Рост Индекс веса 0 Мужской 174 96 4 1 Мужской 189 87 2 2 Женский 185 110 4 3 Женский 195104 3 4 Мужской 149 61 3
Подход :
- Каждый из индексов характеристик передается в variance_inflation_factor (), чтобы найти соответствующий VIF.
- Эти значения хранятся в форме фрейма данных Pandas.
Python3
from statsmodels.stats.outliers_influence import variance_inflation_factor # creating dummies for genderdata[ 'Gender' ] = data[ 'Gender' ]. map ({ 'Male' : 0 , 'Female' : 1 }) # the independent variables setX = data[[ 'Gender' , 'Height' , 'Weight' ]] # VIF dataframevif_data = pd.DataFrame()vif_data[ "feature" ] = X.columns # calculating VIF for each featurevif_data[ "VIF" ] = [variance_inflation_factor(X.values, i) for i in range ( len (X.columns))] print (vif_data) |
Выход :
особенность VIF 0 Пол 2.028864 1 Высота 11.623103 2 Вес 10.688377
Как мы видим, рост и вес имеют очень высокие значения VIF, что указывает на высокую корреляцию между этими двумя переменными. Это ожидается, поскольку рост человека действительно влияет на его вес. Следовательно, рассмотрение этих двух функций вместе приводит к модели с высокой мультиколлинеарностью.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.