NLP Gensim Tutorial - Полное руководство для начинающих
В этом руководстве вы познакомитесь с библиотекой Gensim .
Gensim : это библиотека с открытым исходным кодом на python, написанная Радимом Рехуреком, которая используется для неконтролируемого моделирования тем и обработки естественного языка. Она предназначена для извлечения семантических тем из документов. Она может обрабатывать большие текстовые коллекции. Таким образом, она отличается от других. Пакеты программного обеспечения для машинного обучения, ориентированные на обработку памяти. GenSim также предоставляет эффективные многоядерные реализации для различных алгоритмов для увеличения скорости обработки. Он предоставляет более удобные средства для обработки текста, чем другие пакеты, такие как Scikit-learn, R и т. д.
В этом руководстве будут рассмотрены следующие концепции:
- Создать корпус из заданного набора данных
- Создайте матрицу TFIDF в Gensim
- Создавайте биграммы и триграммы с помощью Gensim
- Создайте модель Word2Vec с помощью Gensim
- Создайте модель Doc2Vec с помощью Gensim
- Создание тематической модели с LDA
- Создание тематической модели с LSI
- Вычислить матрицы подобия
- Обобщать текстовые документы
Прежде чем двигаться дальше, давайте разберемся, что означают некоторые из нижеприведенных терминов.
- Корпус: собрание текстовых документов.
- Вектор: форма представления текста.
- Модель: алгоритм, используемый для создания представления данных.
- Тематическое моделирование: это инструмент интеллектуального анализа информации, который используется для извлечения семантических тем из документов.
- Тема: повторяющаяся группа слов, часто встречающихся вместе.
Например:
У вас есть документ, состоящий из таких слов, как -
летучая мышь, машина, ракетка, счет, стекло, привод, чашка, ключи, вода, игра, руль, жидкость
Их можно сгруппировать по разным темам:
| Тема 1 | Тема 2 | Тема 3 |
|---|---|---|
| стакан | летучая мышь | автомобиль |
| чашка | ракетка | водить машину |
| воды | счет | ключи |
| жидкость | игра | стерринг |
Некоторые из методов тематического моделирования :
- Скрытое семантическое индексирование (LSI)
- Скрытое распределение Дирихле (LDA)
Теперь, когда у нас есть основная идея терминологии, давайте начнем с использования пакета Gensim.
Сначала установите библиотеку с помощью команд:
# для linuxpip install gensim# для подсказки анакондыconda install gensim
Шаг 1. Создайте корпус из заданного набора данных
Вам необходимо выполнить следующие шаги, чтобы создать свой корпус:
- Загрузите свой набор данных
- Предварительная обработка набора данных
- Создать словарь
- Создать Мешок со Словами
1.1 Загрузите свой набор данных:
У вас может быть файл .txt в качестве набора данных или вы также можете загружать наборы данных с помощью API Gensim Downloader .
Код:
import os # open the text file as an objectdoc = open ( 'sample_data.txt' , encoding = 'utf-8' ) |
- Gensim Downloader API: это модуль, доступный в библиотеке Gensim, который представляет собой API для загрузки, получения информации и загрузки наборов данных / моделей.
Код:
import gensim.downloader as api # check available models and datasetsinfo_datasets = api.info()print (info_datasets)#>{'corpora':#> {'semeval-2016-2017-task3-subtaskBC':#> {'num_records': -1, 'record_format': 'dict', 'file_size': 6344358, ....} # information of a particular datasetdataset_info = api.info( "text8" ) # load the "text8" datasetdataset = api.load( "text8" ) # load a pre-trained modelword2vec_model = api.load( 'word2vec-google-news-300' ) |
Здесь мы собираемся рассматривать текстовый файл как необработанный набор данных, который состоит из данных со страницы Википедии.
1.2 Предварительная обработка набора данных
Предварительная обработка текста: в предварительной обработке естественного языка предварительная обработка текста - это практика очистки и подготовки текстовых данных. Для этого воспользуемся simple_preprocess( ) которая возвращает список токенов после их токенизации и нормализации.
Код:
import gensimimport osfrom gensim.utils import simple_preprocess # open the text file as an objectdoc = open ( 'sample_data.txt' , encoding = 'utf-8' ) # preprocess the file to get a list of tokenstokenized = []for sentence in doc.read().split( '.' ): # the simple_preprocess function returns a list of each sentence tokenized.append(simple_preprocess(sentence, deacc = True )) print (tokenized) |
Выход:
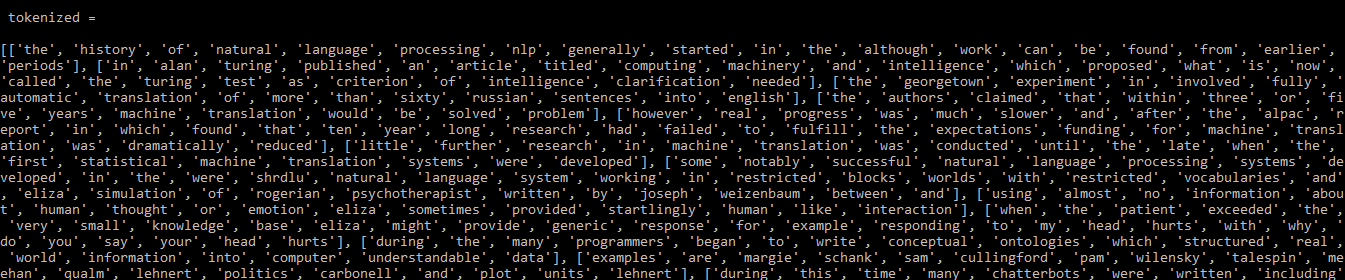
Выход: токенизированный
1.3 Создать словарь
Теперь у нас есть предварительно обработанные данные, которые можно преобразовать в словарь с помощью функции corpora.Dictionary( ) . Этот словарь представляет собой карту уникальных токенов.
Код:
from gensim import corpora# storing the extracted tokens into the dictionarymy_dictionary = corpora.Dictionary(tokenized)print (my_dictionary) |
Выход:

my_dictionary
1.3.1 Сохранение словаря на диск или в виде текстового файла
Вы можете сохранить / загрузить свой словарь на диск, а также текстовый файл, как указано ниже:
Код:
# save your dictionary to diskmy_dictionary.save( 'my_dictionary.dict' ) # load backload_dict = corpora.Dictionary.load(my_dictionary. dict ') # save your dictionary as text filefrom gensim.test.utils import get_tmpfiletmp_fname = get_tmpfile( "dictionary" )my_dictionary.save_as_text(tmp_fname) # load your dictionary text fileload_dict = corpora.Dictionary.load_from_text(tmp_fname) |
1.4 Создание корпуса пакета слов
Когда у нас есть словарь, мы можем создать корпус Bag of Word с помощью функции doc2bow( ) . Эта функция подсчитывает количество вхождений каждого отдельного слова, преобразует слово в его целочисленный идентификатор слова, а затем результат возвращается в виде разреженного вектора.
Код:
# convertig to a bag of word corpusBoW_corpus = [my_dictionary.doc2bow(doc, allow_update = True ) for doc in tokenized]print (BoW_corpus) |
Выход:
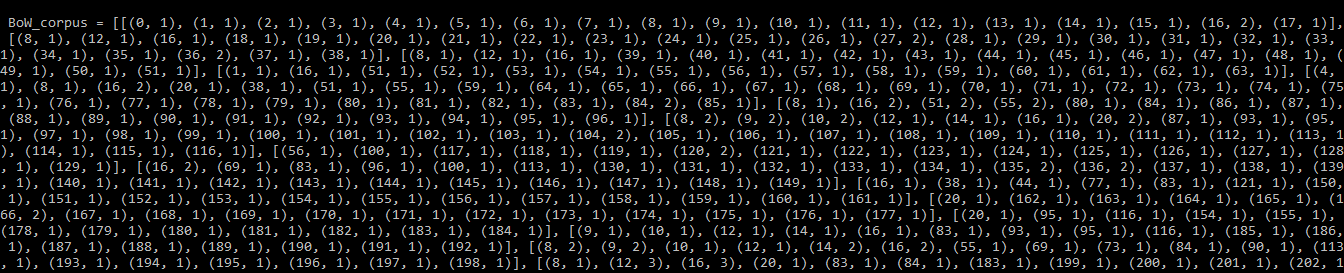
BoW_corpus
1.4.1 Сохранение корпуса на диск:
Код: для сохранения / загрузки вашего корпуса
from gensim.corpora import MmCorpusfrom gensim.test.utils import get_tmpfile output_fname = get_tmpfile( "BoW_corpus.mm" ) # save corpus to diskMmCorpus.serialize(output_fname, BoW_corpus) # load corpusload_corpus = MmCorpus(output_fname) |
Шаг 2: Создайте матрицу TFIDF в Gensim
TFIDF: сокращение от Term Frequency - Inverse Document Frequency . Это широко используемая модель обработки естественного языка, которая помогает вам определять самые важные слова в каждом документе в корпусе. Это было разработано для корпуса скромного размера.
Некоторые слова могут не использоваться в качестве игнорируемых слов, но могут чаще встречаться в документах и иметь меньшее значение. Следовательно, эти слова необходимо удалить или снизить их важность. Модель TFIDF берет текст, использующий общий язык, и гарантирует, что наиболее распространенные слова во всем корпусе не будут отображаться в качестве ключевых слов. Вы можете построить модель TFIDF, используя Gensim и корпус, который вы разработали ранее, как:
Код:
from import models gensimimport numpy as np # Word weight in Bag of Words corpusword_weight = []for doc in BoW_corpus: for id , freq in doc: word_weight.append([my_dictionary[ id ], freq])print (word_weight) |
Выход:

Вес слова перед применением модели TFIDF
Код: применение модели TFIDF
# create TF-IDF modeltfIdf = models.TfidfModel(BoW_corpus, smartirs = 'ntc' ) # TF-IDF Word Weightweight_tfidf = []for doc in tfIdf[BoW_corpus]: for id , freq in doc: weight_tfidf.append([my_dictionary[ id ], np.around(freq, decimals = 3 )])print (weight_tfidf) |
Выход:

веса слов после применения модели TFIDF
Вы можете видеть, что словам, часто встречающимся в документах, теперь присвоены более низкие веса.
Шаг 3. Создание биграмм и триграмм с помощью генизма
Многие слова часто встречаются в содержании вместе. Слова, встречающиеся вместе, имеют другое значение, чем по отдельности.
Например:
Битбоксинг -> слова бит и бокс по отдельности имеют собственное значение
но вместе они имеют разное значение.
Биграммы: группа из двух слов.
Триграммы: группа из трех слов.
Здесь мы будем использовать набор данных text8, который можно загрузить с помощью API загрузчика Gensim.
Код: построение биграмм и триграмм
import gensim.downloader as apifrom gensim.models.phrases import Phrases # load the text8 datasetdataset = api.load( "text8" ) # extract a list of words from the datasetdata = []for word in dataset: data.append(word) # Bigram using Phraser Modelbigram_model = Phrases(data, min_count = 3 , threshold = 10 ) print (bigram_model[data[ 0 ]]) |

Биграммная модель
Чтобы создать триграмму, мы просто передаем полученную выше модель биграммы той же функции.
Код:
# Trigram using Phraser Modeltrigram_model = Phrases(bigram_model[data], threshold = 10 ) # trigramprint (trigram_model[bigram_model[data[ 0 ]]]) |
Выход:

Триграмма
Шаг 4: Создайте модель Word2Vec с помощью Gensim
Алгоритмы ML / DL не могут получить доступ к тексту напрямую, поэтому нам нужно некоторое числовое представление, чтобы эти алгоритмы могли обрабатывать данные. В простых приложениях машинного обучения используются
CountVectorizer и TFIDF , которые не сохраняют связь между словами.Word2Vec: метод представления текста для создания вложений Word, которые отображают все слова, присутствующие на языке, в векторное пространство заданного измерения. Мы можем выполнять математические операции с этими векторами, которые помогают сохранить связь между словами.
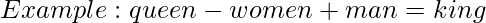
Предварительно созданные модели встраивания слов, такие как word2vec, GloVe, fasttext и т. Д., Можно загрузить с помощью API загрузчика Gensim. Иногда вы можете не найти встраивания слов для определенных слов в своем документе. Так вы можете тренировать свою модель.
4.1) Обучите модель
Код:
import gensim.downloader as apifrom multiprocessing import cpu_countfrom gensim.models.word2vec import Word2Vec # load the text8 datasetdataset = api.load( "text8" ) # extract a list of words from the datasetdata = []for word in dataset: data.append(word) # We will split the data into two partsdata_1 = data[: 1200 ] # this is used to train the modeldata_2 = data[ 1200 :] # this part will be used to update the model # Training the Word2Vec modelw2v_model = Word2Vec(data_1, min_count = 0 , workers = cpu_count()) # word vector for the word "time"print (w2v_model[ 'time' ]) |
Выход:
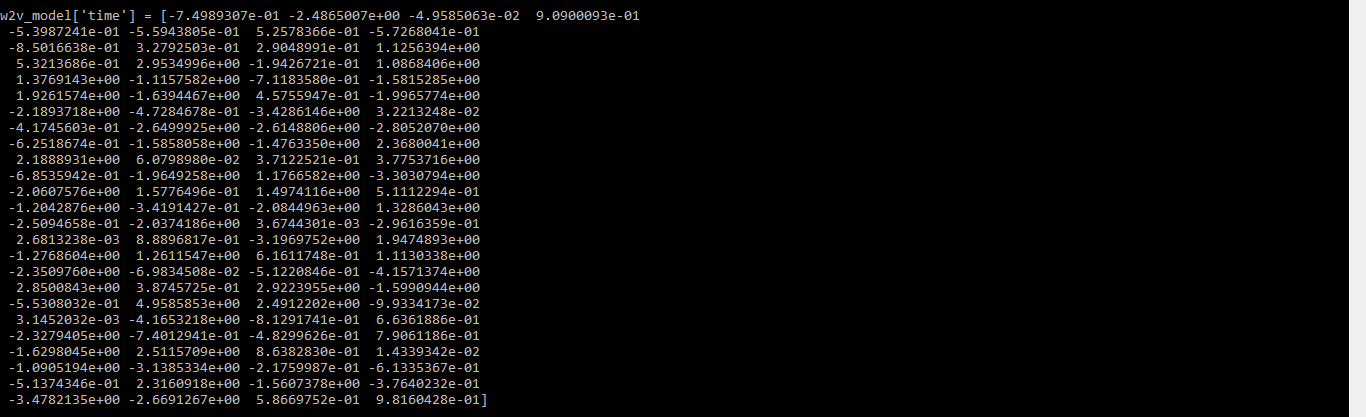
вектор слова для слова время
Вы также можете использовать
most_similar( ) чтобы найти слова, похожие на данное слово.Код:
# similar words to the word "time"print (w2v_model.most_similar( 'time' )) # save your modelw2v_model.save( 'Word2VecModel' ) # load your modelmodel = Word2Vec.load( 'Word2VecModel' ) |
Выход:

слова, наиболее похожие на "время"
4.2) Обновляем модель
Код:
# build model vocabulary from a sequence of sentencesw2v_model.build_vocab(data_2, update = True ) # train word vectorsw2v_model.train(data_2, total_examples = w2v_model.corpus_count, epochs = w2v_model. iter ) print (w2v_model[ 'time' ]) |
Выход: 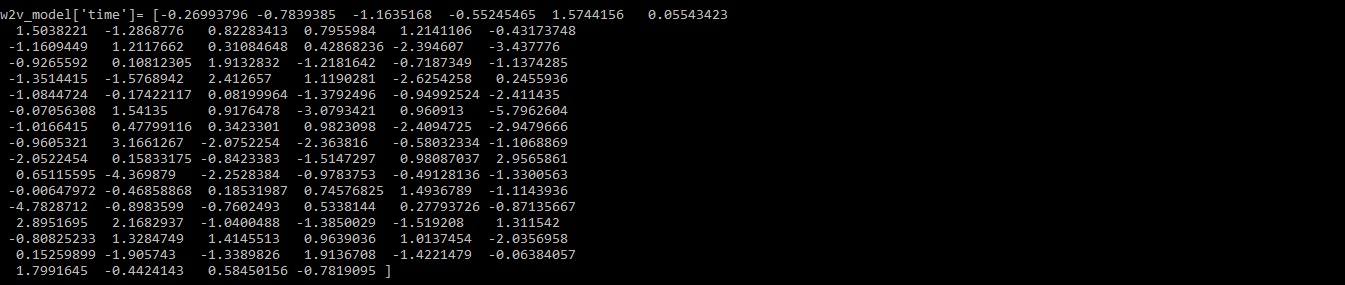
Шаг 5: Создайте модель Doc2Vec с помощью Gensim
В отличие от модели Word2Vec, модель Doc2Vec дает векторное представление для всего документа или группы слов. С помощью этой модели мы можем найти взаимосвязь между различными документами, такими как:
Если натренировать модель для литературы типа «Зазеркалье». Мы можем сказать, что -

5.1) Обучите модель
Код:
import gensimimport gensim.downloader as apifrom gensim.models import doc2vec # get datasetdataset = api.load( "text8" )data = []for w in dataset: data.append(w) # To train the model we need a list of tagged documentsdef tagged_document(list_of_ListOfWords): for x, ListOfWords in enumerate (list_of_ListOfWords): yield doc2vec.TaggedDocument(ListOfWords, [x]) # training datadata_train = list (tagged_document(data)) # print trained datasetprint (data_train[: 1 ]) |
Выход:

ВЫХОД - обученный набор данных
# Initialize the modeld2v_model = doc2vec.Doc2Vec(vector_size = 40 , min_count = 2 , epochs = 30 ) # build the vocabularyd2v_model.build_vocab(data_train) # Train Doc2Vec modeld2v_model.train(data_train, total_examples = d2v_model.corpus_count, epochs = d2v_model.epochs) # Analyzing the outputAnalyze = d2v_model.infer_vector([ 'violent' , 'means' , 'to' , 'destroy' ])print (Analyze) |
Выход:

Вывод обновленной модели
Шаг 6. Создайте модель темы с помощью LDA
LDA - популярный метод тематического моделирования, при котором каждый документ рассматривается как набор тем в определенной пропорции. Нам нужно исключить хорошее качество тем, например, насколько они разделены и значимы. Темы хорошего качества зависят от:
- качество обработки текста
- поиск оптимального количества тем
- Параметры настройки алгоритма
ПРИМЕЧАНИЕ. Если вы запустите этот код в версии python3.7, вы можете получить ошибку StopIteration.
Для этого желательно использовать версию python3.6.
Выполните следующие шаги, чтобы создать модель:
6.1 Подготовьте данные
Это делается путем удаления игнорируемых слов и последующего их лемматизации. Чтобы выполнить лемматизацию с помощью Gensim, нам нужно сначала загрузить пакет шаблонов и стоп-слова.
# загрузить пакет шаблонов
шаблон установки pip
# запустить в консоли Python
>> импорт nltk
>> nltk.download ('игнорируемые слова')
Код:
import gensimfrom gensim import corporafrom gensim.models import LdaModel, LdaMulticoreimport gensim.downloader as apifrom gensim.utils import simple_preprocess, lemmatize# from pattern.en import lemmaimport nltk# nltk.download('stopwords')from nltk.corpus import stopwordsimport reimport logging logging.basicConfig( format = '%(asctime)s : %(levelname)s : %(message)s' )logging.root.setLevel(level = logging.INFO) # import stopwordsstop_words = stopwords.words( 'english' )# add stopwordsstop_words = stop_words + [ 'subject' , 'com' , 'are' , 'edu' , 'would' , 'could' ] # import the datasetdataset = api.load( "text8" )data = [w for w in dataset] # Preparing the dataprocessed_data = [] for x, doc in enumerate (data[: 100 ]): doc_out = [] for word in doc: if word not in stop_words: # to remove stopwords Lemmatized_Word = lemmatize(word, allowed_tags = re. compile ( '(NN|JJ|RB)' )) # lemmatize if Lemmatized_Word: doc_out.append(Lemmatized_Word[ 0 ].split(b '/' )[ 0 ].decode( 'utf-8' )) else : continue processed_data.append(doc_out) # processed_data is a list of list of words # Print sampleprint (processed_data[ 0 ][: 10 ]) |
Выход:

ВЫХОД - обработанные_данные
Обработанные данные теперь будут использоваться для создания словаря и корпуса.
Код:
# create dictionary and corpusdict = corpora.Dictionary(processed_data)Corpus = [ dict .doc2bow(l) for l in processed_data] |
6.3 Модель поезда LDA
Мы будем обучать модель LDA с 5 темами, используя словарь и корпус, созданные ранее. Здесь используется функция LdaModel (), но вы также можете использовать функцию LdaMulticore (), поскольку она позволяет выполнять параллельную обработку.
Код:
# TrainingLDA_model = LdaModel(corpus = LDA_corpus, num_topics = 5 )# save modelLDA_model.save( 'LDA_model.model' ) # show topicsprint (LDA_model.print_topics( - 1 )) |
Выход:

ВЫХОД - темы
Слова, которые встречаются в более чем одной теме и имеют меньшее значение, могут быть добавлены в список запрещенных слов.
6.4 Интерпретация вывода
Модель LDA в основном дает нам информацию по трем вещам:
- Темы в документе
- К какой теме принадлежит каждое слово
- Значение фи
Значение фи: это вероятность того, что слово относится к определенной теме. Для данного слова сумма значений фи дает количество раз, когда это слово встречается в документе.
Код:
# probability of a word belonging to a topicLDA_model.get_term_topics( 'fire' ) bow_list = [ 'time' , 'space' , 'car' ]# convert to bag of words format firstbow = LDA_model.id2word.doc2bow(bow_list) # interpreting the datadoc_topics, word_topics, phi_values = LDA_model.get_document_topics(bow, per_word_topics = True ) |
Шаг 7. Создайте тематическую модель с помощью LSI
Чтобы создать модель с LSI, просто выполните те же шаги, что и с LDA. Единственная разница будет во время обучения модели.
Используйте LsiModel( ) вместо LdaMulticore( ) или LdaModel( ) .
Код:
# Training the model with LSILSI_model = LsiModel(corpus = Corpus, id2word = dct, num_topics = 7 , decay = 0.5 ) # Topicsprint (LSI_model.print_topics( - 1 )) |
Шаг 8: вычисление матриц подобия
Косинусное сходство: это мера сходства между двумя ненулевыми векторами внутреннего пространства продукта. Он определяется как равный косинусу угла между ними.
Мягкое косинусное сходство: оно похоже на косинусное сходство, но разница в том, что косинусное сходство рассматривает функции модели векторного пространства (VSM) как независимые, тогда как мягкий косинус предлагает учитывать сходство функций в VSM.
Нам нужно взять модель вложения слов для вычисления мягких косинусов.
Здесь мы используем предварительно обученную модель word2vec.
Примечание. Если вы запустите этот код в версии python3.7, вы можете получить ошибку StopIteration.
Для этого желательно использовать версию python3.6.
Код:
import gensim.downloader as apifrom gensim.matutils import softcossimfrom gensim import corpora s1 = ' Afghanistan is an Asian country and capital is Kabul' .split()s2 = 'India is an Asian country and capital is Delhi' .split()s3 = 'Greece is an European country and capital is Athens' .split() # load pre-trained model
РЕКОМЕНДУЕМЫЕ СТАТЬИ |