ML | Прогнозирование количества осадков с использованием линейной регрессии
Предпосылки: линейная регрессия
Прогнозирование осадков - это применение науки и технологий для прогнозирования количества осадков в регионе. Важно точно определить количество осадков для эффективного использования водных ресурсов, урожайности сельскохозяйственных культур и предварительного планирования водных сооружений.
В этой статье мы будем использовать линейную регрессию для прогнозирования количества осадков. Линейная регрессия сообщает нам, сколько дюймов осадков мы можем ожидать.
Набор данных - это общедоступный набор данных о погоде из Остина, штат Техас, доступный на Kaggle. Набор данных можно найти здесь.
Очистка данных:
Данные поступают во всех формах, большинство из них очень беспорядочные и неструктурированные. Они редко бывают готовыми к использованию. Наборы данных, большие и малые, связаны с множеством проблем - недопустимыми полями, отсутствующими и дополнительными значениями, а также значениями в форме, отличной от той, которая нам нужна. Чтобы привести его в работоспособную или структурированную форму, нам нужно «очистить» наши данные и подготовить их к использованию. Некоторые общие очистки включают в себя синтаксический анализ, преобразование в горячую, удаление ненужных данных и т. Д.
В нашем случае в наших данных есть дни, когда некоторые факторы не записывались. И количество осадков в сантиметрах было отмечено буквой T, если присутствовали следы осадков. Нашему алгоритму требуются числа, поэтому мы не можем работать с алфавитами, появляющимися в наших данных. поэтому нам нужно очистить данные, прежде чем применять их к нашей модели
Очистка данных в Python:
# importing librariesimport pandas as pdimport numpy as np # read the data in a pandas dataframedata = pd.read_csv( "austin_weather.csv" ) # drop or delete the unnecessary columns in the data.data = data.drop([ 'Events' , 'Date' , 'SeaLevelPressureHighInches' , 'SeaLevelPressureLowInches' ], axis = 1 ) # some values have 'T' which denotes trace rainfall# we need to replace all occurrences of T with 0# so that we can use the data in our modeldata = data.replace( 'T' , 0.0 ) # the data also contains '-' which indicates no# or NIL. This means that data is not available# we need to replace these values as well.data = data.replace( '-' , 0.0 ) # save the data in a csv filedata.to_csv( 'austin_final.csv' ) |
После очистки данных их можно использовать в качестве входных данных для нашей модели линейной регрессии. Линейная регрессия - это линейный подход к формированию отношения между зависимой переменной и многими независимыми независимыми переменными. Это делается путем построения линии, которая наилучшим образом соответствует нашему графику разброса, то есть с наименьшими ошибками. Это дает прогнозы значений, т. Е. Сколько, путем подстановки независимых значений в линейное уравнение.
Мы будем использовать модель линейной регрессии Scikit-learn для обучения нашего набора данных. После обучения модели мы можем предоставить собственные входные данные для различных столбцов, таких как температура, точка росы, давление и т. Д., Чтобы прогнозировать погоду на основе этих атрибутов.
# importing librariesimport pandas as pdimport numpy as npimport sklearn as skfrom sklearn.linear_model import LinearRegressionimport matplotlib.pyplot as plt # read the cleaned datadata = pd.read_csv( "austin_final.csv" ) # the features or the 'x' values of the data# these columns are used to train the model# the last column, ie, precipitation column# will serve as the labelX = data.drop([ 'PrecipitationSumInches' ], axis = 1 ) # the output or the label.Y = data[ 'PrecipitationSumInches' ]# reshaping it into a 2-D vectorY = Y.values.reshape( - 1 , 1 ) # consider a random day in the dataset# we shall plot a graph and observe this# dayday_index = 798days = [i for i in range (Y.size)] # initialize a linear regression classifierclf = LinearRegression()# train the classifier with our# input data.clf.fit(X, Y) # give a sample input to test our model# this is a 2-D vector that contains values# for each column in the dataset.inp = np.array([[ 74 ], [ 60 ], [ 45 ], [ 67 ], [ 49 ], [ 43 ], [ 33 ], [ 45 ], [ 57 ], [ 29.68 ], [ 10 ], [ 7 ], [ 2 ], [ 0 ], [ 20 ], [ 4 ], [ 31 ]])inp = inp.reshape( 1 , - 1 ) # print the output.print ( 'The precipitation in inches for the input is:' , clf.predict(inp)) # plot a graph of the precipitation levels# versus the total number of days.# one day, which is in red, is# tracked here. It has a precipitation# of approx. 2 inches.print ( "the precipitation trend graph: " )plt.scatter(days, Y, color = 'g' )plt.scatter(days[day_index], Y[day_index], color = 'r' )plt.title( "Precipitation level" )plt.xlabel( "Days" )plt.ylabel( "Precipitation in inches" ) plt.show()x_vis = X. filter ([ 'TempAvgF' , 'DewPointAvgF' , 'HumidityAvgPercent' , 'SeaLevelPressureAvgInches' , 'VisibilityAvgMiles' , 'WindAvgMPH' ], axis = 1 ) # plot a graph with a few features (x values)# against the precipitation or rainfall to observe# the trends print ( "Precipitation vs selected attributes graph: " ) for i in range (x_vis.columns.size): plt.subplot( 3 , 2 , i + 1 ) plt.scatter(days, x_vis[x_vis.columns.values[i][: 100 ]], color = 'g' ) plt.scatter(days[day_index], x_vis[x_vis.columns.values[i]][day_index], color = 'r' ) plt.title(x_vis.columns.values[i]) plt.show() |
Выход :
Осадки в дюймах для входных данных: [[1.33868402]] График тренда осадков:
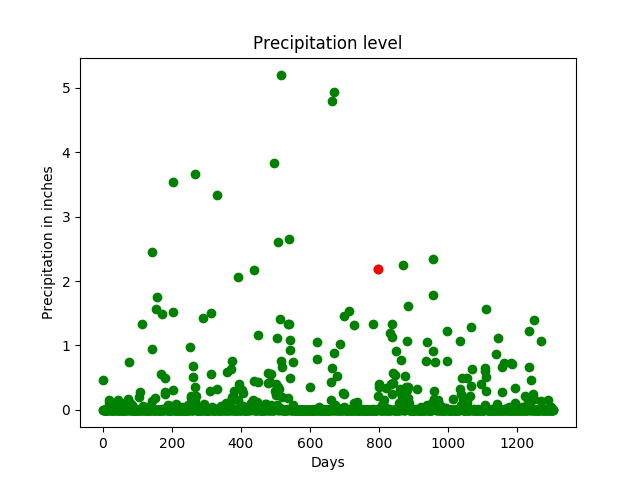
График зависимости осадков от выбранных атрибутов: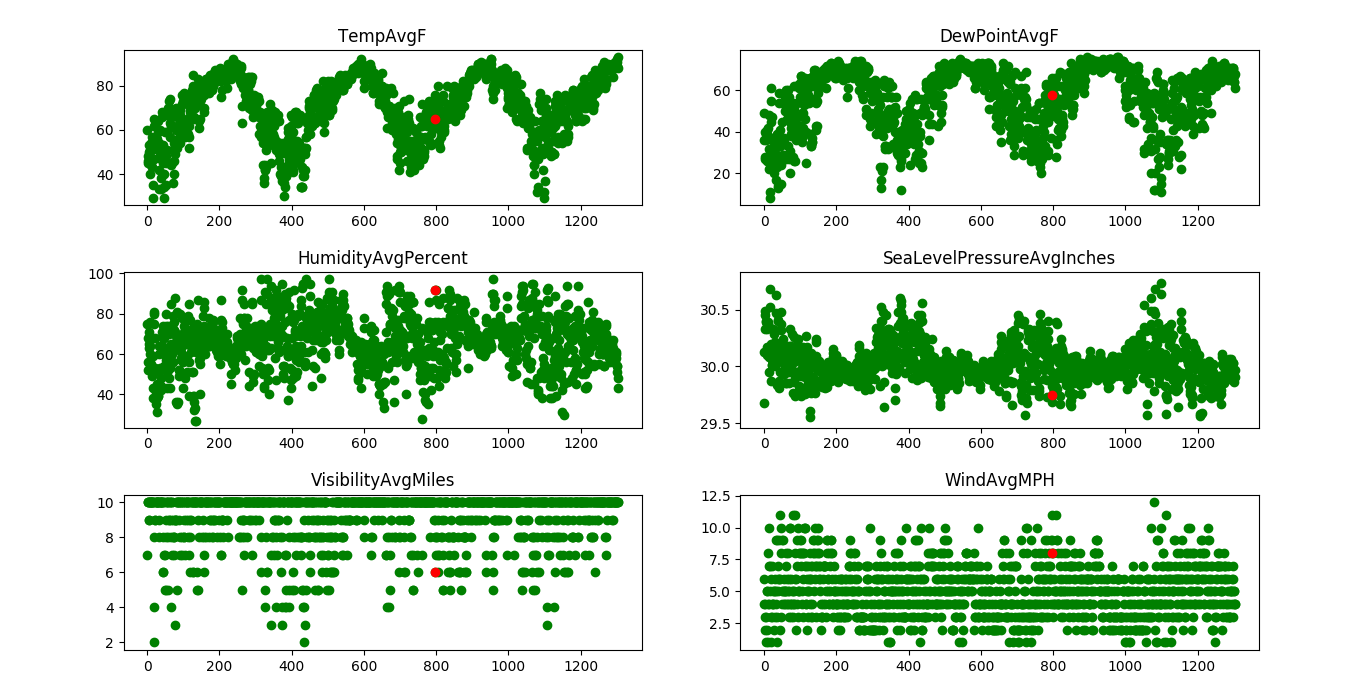
День (выделенный красным) с осадками около 2 дюймов отслеживается по нескольким параметрам (один и тот же день отслеживается по нескольким параметрам, таким как температура, давление и т. Д.). Ось X обозначает дни, а ось Y обозначает величину характеристики, такой как температура, давление и т. Д. Из графика можно заметить, что можно ожидать сильных осадков при высокой температуре и высокой влажности. высокая.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.

- наука о данных
- Машинное обучение
- Python
- Машинное обучение