ML | Найти S-алгоритм
Вступление :
Алгоритм Find-S - это базовый алгоритм обучения концепции в машинном обучении. Алгоритм Find-S находит наиболее конкретную гипотезу, подходящую для всех положительных примеров. Здесь следует отметить, что алгоритм учитывает только положительные обучающие примеры. Алгоритм Find-S начинается с наиболее конкретной гипотезы и обобщает эту гипотезу каждый раз, когда ему не удается классифицировать наблюдаемые положительные данные обучения. Следовательно, алгоритм Find-S переходит от наиболее конкретной гипотезы к наиболее общей.
Важное представление:
- ? указывает, что для атрибута допустимо любое значение.
- укажите единственное обязательное значение (например, Холодное) для атрибута.
- ϕ указывает, что значение неприемлемо.
- Самая общая гипотеза представлена: {?,?,?,?,?,?}
- Наиболее конкретная гипотеза представлена следующим образом: {ϕ, ϕ, ϕ, ϕ, ϕ, ϕ}
Шаги, связанные с Find-S:
- Начнем с самой конкретной гипотезы.
h = {ϕ, ϕ, ϕ, ϕ, ϕ, ϕ} - Возьмем следующий пример, и если он отрицательный, то гипотеза не изменится.
- Если пример положительный и мы обнаруживаем, что наша первоначальная гипотеза слишком конкретна, мы обновляем нашу текущую гипотезу до общего состояния.
- Продолжайте повторять вышеуказанные шаги, пока не будут завершены все обучающие примеры.
- После того, как мы завершим все обучающие примеры, у нас будет окончательная гипотеза, когда ее можно будет использовать для классификации новых примеров.
Пример :
Рассмотрим следующий набор данных, содержащий данные о том, какие именно семена ядовиты. 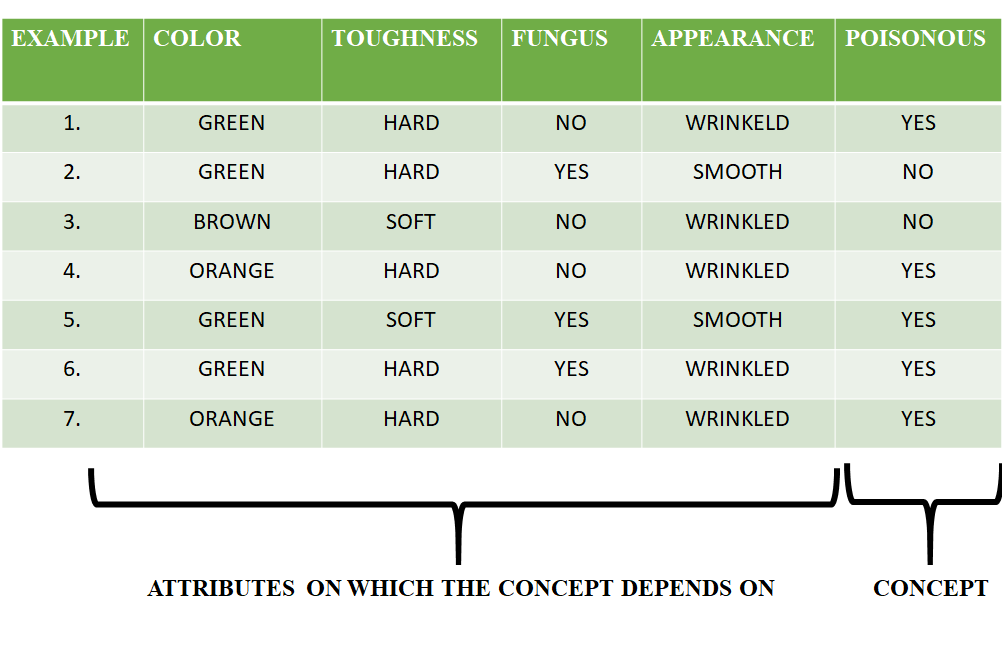
Сначала мы рассматриваем гипотезу как более конкретную гипотезу. Следовательно, наша гипотеза была бы такой:
h = {ϕ, ϕ, ϕ, ϕ, ϕ, ϕ}
Рассмотрим пример 1:
Данные в примере 1: {ЗЕЛЕНЫЙ, ЖЕСТКИЙ, НЕТ, МОРЩАННЫЙ}. Мы видим, что наша исходная гипотеза более конкретна, и мы должны обобщить ее для этого примера. Следовательно, гипотеза принимает следующий вид:
h = {ЗЕЛЕНЫЙ, ЖЕСТКИЙ, НЕТ, МОРЩАННЫЙ}
Рассмотрим пример 2:
Здесь мы видим, что этот пример имеет отрицательный результат. Поэтому мы пренебрегаем этим примером, и наша гипотеза остается прежней.
h = {ЗЕЛЕНЫЙ, ЖЕСТКИЙ, НЕТ, МОРЩАННЫЙ}
Рассмотрим пример 3:
Здесь мы видим, что этот пример имеет отрицательный результат. Поэтому мы пренебрегаем этим примером, и наша гипотеза остается прежней.
h = {ЗЕЛЕНЫЙ, ЖЕСТКИЙ, НЕТ, МОРЩАННЫЙ}
Рассмотрим пример 4:
В примере 4 представлены следующие данные: {ОРАНЖЕВЫЙ, ЖЕСТКИЙ, НЕТ, МОРЩАННЫЙ}. Мы сравниваем каждый атрибут с исходными данными, и если обнаруживается какое-либо несоответствие, мы заменяем этот конкретный атрибут общим регистром («?»). После выполнения процесса гипотеза принимает следующий вид:
h = {?, ЖЕСТКИЙ, НЕТ, МОРЩАННЫЙ}
Рассмотрим пример 5:
В примере 5 представлены следующие данные: {ЗЕЛЕНЫЙ, МЯГКИЙ, ДА, ГЛАДКИЙ}. Мы сравниваем каждый атрибут с исходными данными, и если обнаруживается какое-либо несоответствие, мы заменяем этот конкретный атрибут общим регистром («?»). После выполнения процесса гипотеза принимает следующий вид:
h = {?,?,?,? }
Поскольку мы достигли точки, когда все атрибуты в нашей гипотезе имеют общее состояние, пример 6 и пример 7 приведут к одинаковым гипотезам со всеми общими атрибутами.
h = {?,?,?,? }
Следовательно, для данных данных окончательной гипотезой будет:
Заключительная гипотеза: h = {?,?,?,? }
Алгоритм:
1. Инициализируйте h для наиболее конкретной гипотезы в H
2. Для каждого положительного обучающего примера x
Для каждого ограничения атрибута a, в h
Если ограничению a, удовлетворяет x
Тогда ничего не делай
В противном случае замените a в h следующим более общим ограничением, которому удовлетворяет x
3. Выходная гипотеза h