ML | Мини-пакетный градиентный спуск с Python
В машинном обучении градиентный спуск - это метод оптимизации, используемый для вычисления параметров модели (коэффициентов и смещения) для таких алгоритмов, как линейная регрессия, логистическая регрессия, нейронные сети и т. Д. В этом методе мы многократно перебираем обучающий набор и обновляем модель. параметры в соответствии с градиентом ошибки относительно обучающей выборки.
В зависимости от количества обучающих примеров, учитываемых при обновлении параметров модели, у нас есть 3 типа градиентных спусков:
- Пакетный градиентный спуск: параметры обновляются после вычисления градиента ошибки по отношению ко всему обучающему набору.
- Стохастический градиентный спуск: параметры обновляются после вычисления градиента ошибки относительно одного обучающего примера.
- Мини-пакетный градиентный спуск: параметры обновляются после вычисления градиента ошибки по отношению к подмножеству обучающего набора.
| Пакетный градиентный спуск | Стохастический градиентный спуск | Мини-пакетный градиентный спуск |
| Поскольку все данные обучения рассматриваются перед тем, как сделать шаг в направлении градиента, поэтому требуется много времени для выполнения одного обновления. | Поскольку перед шагом в направлении градиента рассматривается только один обучающий пример, мы вынуждены перебирать обучающий набор и, таким образом, не можем использовать скорость, связанную с векторизацией кода. | Поскольку рассматривается подмножество обучающих примеров, он может быстро обновлять параметры модели, а также может использовать скорость, связанную с векторизацией кода. |
| Плавно обновляются параметры модели. | Очень шумно обновляет параметры. | В зависимости от размера пакета обновления можно сделать менее шумными - чем больше размер пакета, тем менее шумным будет обновление. |
Таким образом, мини-пакетный градиентный спуск представляет собой компромисс между быстрой сходимостью и шумом, связанным с обновлением градиента, что делает его более гибким и надежным алгоритмом.
Мини-пакетный градиентный спуск:
Алгоритм-
Let theta = model parameters and max_iters = number of epochs.
for itr = 1, 2, 3, …, max_iters:
for mini_batch (X_mini, y_mini):
- Forward Pass on the batch X_mini:
- Make predictions on the mini-batch
- Compute error in predictions (J(theta)) with the current values of the parameters
- Backward Pass:
- Compute gradient(theta) = partial derivative of J(theta) w.r.t. theta
- Update parameters:
- theta = theta – learning_rate*gradient(theta)
Ниже представлена реализация Python:
Шаг №1: Первый шаг - импортировать зависимости, сгенерировать данные для линейной регрессии и визуализировать сгенерированные данные. Мы создали 8000 примеров данных, каждый из которых имеет 2 атрибута / функции. Эти примеры данных дополнительно разделены на обучающий набор (X_train, y_train) и набор для тестирования (X_test, y_test), имеющий 7200 и 800 примеров соответственно.
# importing dependenciesimport numpy as npimport matplotlib.pyplot as plt # creating datamean = np.array([ 5.0 , 6.0 ])cov = np.array([[ 1.0 , 0.95 ], [ 0.95 , 1.2 ]])data = np.random.multivariate_normal(mean, cov, 8000 ) # visualising dataplt.scatter(data[: 500 , 0 ], data[: 500 , 1 ], marker = '.' )plt.show() # train-test-splitdata = np.hstack((np.ones((data.shape[ 0 ], 1 )), data)) split_factor = 0.90split = int (split_factor * data.shape[ 0 ]) X_train = data[:split, : - 1 ]y_train = data[:split, - 1 ].reshape(( - 1 , 1 ))X_test = data[split:, : - 1 ]y_test = data[split:, - 1 ].reshape(( - 1 , 1 )) print ( "Number of examples in training set = % d" % (X_train.shape[ 0 ]))print ( "Number of examples in testing set = % d" % (X_test.shape[ 0 ])) |
Выход:
Количество примеров в обучающей выборке = 7200
Количество примеров в наборе для тестирования = 800
Шаг № 2: Затем мы пишем код для реализации линейной регрессии с использованием мини-пакетного градиентного спуска.
gradientDescent() - это основная функция драйвера, а другие функции - это вспомогательные функции, используемые для прогнозирования - hypothesis() , вычисления градиентов - gradient() , ошибки вычисления - cost() и создания мини-пакетов - create_mini_batches() . Функция драйвера инициализирует параметры, вычисляет лучший набор параметров для модели и возвращает эти параметры вместе со списком, содержащим историю ошибок, по мере обновления параметров.
# linear regression using "mini-batch" gradient descent# function to compute hypothesis / predictionsdef hypothesis(X, theta): return np.dot(X, theta) # function to compute gradient of error function wrt thetadef gradient(X, y, theta): h = hypothesis(X, theta) grad = np.dot(X.transpose(), (h - y)) return grad # function to compute the error for current values of thetadef cost(X, y, theta): h = hypothesis(X, theta) J = np.dot((h - y).transpose(), (h - y)) J / = 2 return J[ 0 ] # function to create a list containing mini-batchesdef create_mini_batches(X, y, batch_size): mini_batches = [] data = np.hstack((X, y)) np.random.shuffle(data) n_minibatches = data.shape[ 0 ] / / batch_size i = 0 for i in range (n_minibatches + 1 ): mini_batch = data[i * batch_size:(i + 1 ) * batch_size, :] X_mini = mini_batch[:, : - 1 ] Y_mini = mini_batch[:, - 1 ].reshape(( - 1 , 1 )) mini_batches.append((X_mini, Y_mini)) if data.shape[ 0 ] % batch_size ! = 0 : mini_batch = data[i * batch_size:data.shape[ 0 ]] X_mini = mini_batch[:, : - 1 ] Y_mini = mini_batch[:, - 1 ].reshape(( - 1 , 1 )) mini_batches.append((X_mini, Y_mini)) return mini_batches # function to perform mini-batch gradient descentdef gradientDescent(X, y, learning_rate = 0.001 , batch_size = 32 ): theta = np.zeros((X.shape[ 1 ], 1 )) error_list = [] max_iters = 3 for itr in range (max_iters): mini_batches = create_mini_batches(X, y, batch_size) for mini_batch in mini_batches: X_mini, y_mini = mini_batch theta = theta - learning_rate * gradient(X_mini, y_mini, theta) error_list.append(cost(X_mini, y_mini, theta)) return theta, error_list |
Вызов функции gradientDescent() для вычисления параметров модели (тета) и визуализации изменения функции ошибок.
theta, error_list = gradientDescent(X_train, y_train)print ( "Bias = " , theta[ 0 ])print ( "Coefficients = " , theta[ 1 :]) # visualising gradient descentplt.plot(error_list)plt.xlabel( "Number of iterations" )plt.ylabel( "Cost" )plt.show() |
Выход:
Смещение = [0,81830471]
Коэффициенты = [[1.04586595]]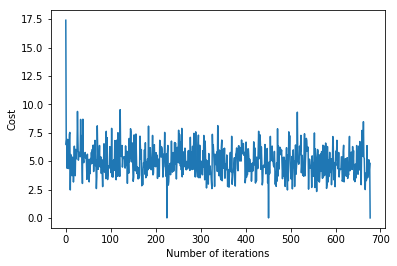
Шаг № 3: Наконец, мы делаем прогнозы на тестовой выборке и вычисляем среднюю абсолютную ошибку прогнозов.
# predicting output for X_testy_pred = hypothesis(X_test, theta)plt.scatter(X_test[:, 1 ], y_test[:, ], marker = '.' )plt.plot(X_test[:, 1 ], y_pred, color = 'orange' )plt.show() # calculating error in predictionserror = np. sum (np. abs (y_test - y_pred) / y_test.shape[ 0 ])print ( "Mean absolute error = " , error) |
Выход: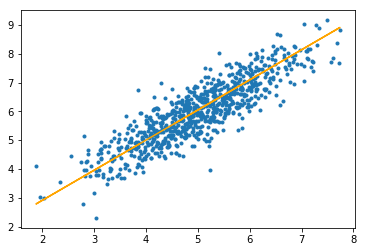
Средняя абсолютная ошибка = 0,4366644295854125
Оранжевая линия представляет окончательную функцию гипотезы: theta [0] + theta [1] * X_test [:, 1] + theta [2] * X_test [:, 2] = 0
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.