ML | Масштабирование функций - Часть 2
Масштабирование функций - это метод стандартизации независимых функций, представленных в данных, в фиксированном диапазоне. Он выполняется во время предварительной обработки данных для обработки сильно различающихся величин, значений или единиц. Если масштабирование функций не выполняется, алгоритм машинного обучения имеет тенденцию взвешивать более высокие значения и рассматривать меньшие значения как более низкие значения, независимо от единицы измерения значений.
Пример: если алгоритм не использует метод масштабирования признаков, он может считать, что значение 3000 метров превышает 5 км, но на самом деле это неверно, и в этом случае алгоритм даст неверные прогнозы. Итак, мы используем масштабирование функций, чтобы привести все значения к одинаковым величинам и, таким образом, решить эту проблему.
Методы масштабирования функций
Рассмотрим два самых важных:
- Минимальная-максимальная нормализация: этот метод масштабирует значение объекта или наблюдения со значением распределения между 0 и 1.
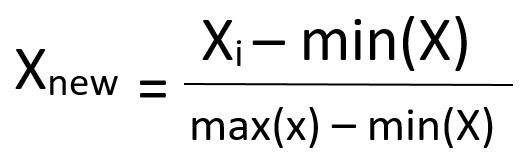
- Стандартизация: это очень эффективный метод, который изменяет масштаб значения характеристики так, чтобы оно имело распределение с нулевым средним значением и дисперсией, равной 1.
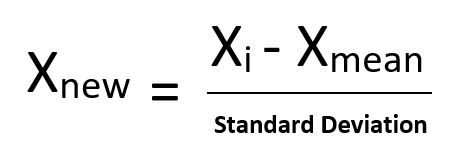
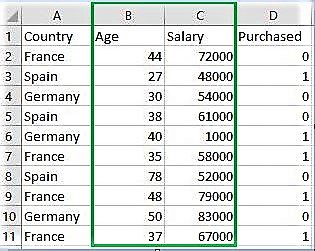
Загрузите набор данных:
Переходим по ссылке и скачиваем Data_for_Feature_Scaling.csv
Ниже приведен код Python:
# Python code explaining How to# perform Feature Scaling """ PART 1 Importing Libraries """ import numpy as npimport matplotlib.pyplot as pltimport pandas as pd # Sklearn libraryfrom preprocessing import sklearn """ PART 2 Importing Data """ data_set = pd.read_csv( 'C:\Users\dell\Desktop\Data_for_Feature_Scaling.csv' )data_set.head() # here Features - Age and Salary columns# are taken using slicing# to handle values with varying magnitudex = data_set.iloc[:, 1 : 3 ].valuesprint ( "
Original data values :
" , x) """ PART 4 Handling the missing values """ from preprocessing import sklearn """ MIN MAX SCALER """ min_max_scaler = preprocessing.MinMaxScaler(feature_range = ( 0 , 1 )) # Scaled featurex_after_min_max_scaler = min_max_scaler.fit_transform(x) print ( "
After min max Scaling :
" , x_after_min_max_scaler) """ Standardisation """ Standardisation = preprocessing.StandardScaler() # Scaled featurex_after_Standardisation = Standardisation.fit_transform(x) print ( "
After Standardisation :
" , x_after_Standardisation) |
Выход :
Страна Возраст Зарплата приобретена 0 Франция 44 72000 0 1 Испания 27 48000 1 2 Германия 30 54000 0 3 Испания 38 61000 0 4 Германия 40 1000 1 Исходные значения данных: [[44 72000] [27 48000] [30 54000] [38 61000] [40 1000] [35 58000] [78 52000] [48 79000] [50 83000] [37 67000]] После минимального максимального масштабирования: [[0,33333333 0,86585366] [0. 0.57317073] [0,05882353 0,64634146] [0,21568627 0,73170732] [0,25490196 0.] [0,15686275 0,69512195] [1. 0.62195122] [0,41176471 0,95121951] [0,45098039 1.] [0,19607843 0,80487805]] После стандартизации: [[0,09536935 0,66527061] [-1,15176827 -0,43586695] [-0,93168516 -0,16058256] [-0,34479687 0,16058256] [-0,1980748 -2,59226136] [-0,56487998 0,02294037] [2,58964459 -0,25234403] [0,38881349 0,98643574] [0,53553557 1,16995867] [-0,41815791 0,43586695]]