ML | Масштабирование функций - Часть 1
Масштабирование функций - это метод стандартизации независимых функций, представленных в данных в фиксированном диапазоне. Выполняется во время предварительной обработки данных.
За работой:
Учитывая набор данных с функциями - возраст, зарплата, квартира BHK с размером данных 5000 человек, каждый из которых имеет эти независимые функции данных.
Каждая точка данных помечена как:
- Class1 - ДА (означает, что с указанным возрастом, зарплатой и значением функции квартиры BHK можно купить недвижимость)
- Class2- НЕТ (означает, что с указанным возрастом, зарплатой и значением функции BHK Apartment невозможно купить недвижимость).
Используя набор данных для обучения модели, каждый стремится построить модель, которая может предсказать, можно ли купить недвижимость с заданными значениями характеристик.
После обучения модели можно создать N-мерный (где N - количество функций, присутствующих в наборе данных) с точками данных из данного набора данных. Приведенный ниже рисунок является идеальным представлением модели.
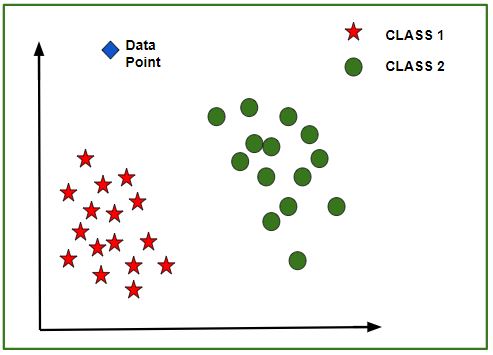
Как показано на рисунке, звездообразные точки данных относятся к классу Class1 - Yes, а кружки представляют метки Class2 - No, и модель обучается с использованием этих точек данных. Теперь дается новая точка данных (ромб, как показано на рисунке), и она имеет разные независимые значения для трех характеристик (возраст, зарплата, квартира BHK), упомянутых выше. Модель должна предсказать, принадлежит ли эта точка данных Да или Нет.
Прогнозирование класса новой точки данных:
Модель вычисляет расстояние от этой точки данных до центроида каждой группы классов. Наконец, эта точка данных будет принадлежать к тому классу, который будет иметь минимальное центроидное расстояние от нее.
Расстояние между центроидом и точкой данных можно рассчитать с помощью следующих методов:
- Евклидово расстояние: это квадратный корень из суммы квадратов разностей между координатами (значения характеристик - возраст, зарплата, квартира BHK) точки данных и центроид каждого класса. Эта формула дается теоремой Пифагора.
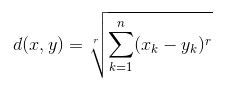
где x - значение точки данных, y - значение центроида, а k - нет. значений характеристик, Пример: данный набор данных имеет k = 3 - Манхэттенское расстояние: рассчитывается как сумма абсолютных разностей между координатами (значениями характеристик) точки данных и центроидом каждого класса.
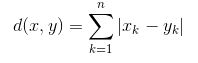
- Расстояние Минковского: это обобщение двух вышеупомянутых методов. Как показано на рисунке, для нахождения r можно использовать разные значения.
Необходимость масштабирования функций:
Данный набор данных содержит 3 характеристики - Возраст, Зарплата, Квартира BHK. Рассмотрим диапазон от 10 до 60 для возраста, 1 Lac- 40 Lac для зарплаты, 1-5 для BHK of Flat. Все эти функции не зависят друг от друга.
Предположим, что центроид класса 1 равен [40, 22 Lacs, 3], а прогнозируемая точка данных - [57, 33 Lacs, 2].
Используя манхэттенский метод,
Расстояние = (| (40 - 57) | + | (2200000 - 3300000) | + | (3 - 2) |)
Можно видеть, что характеристика заработной платы будет доминировать над всеми другими характеристиками при прогнозировании класса данной точки данных, и поскольку все характеристики независимы друг от друга, то есть заработная плата человека не связана с его / ее возрастом или с тем, какие требования к квартире он / у нее есть. Это означает, что модель всегда будет предсказывать неверно.
Итак, простое решение этой проблемы - масштабирование функций. Алгоритмы масштабирования функций будут масштабировать возраст, зарплату, BHK в фиксированном диапазоне, например [-1, 1] или [0, 1]. И тогда ни одно свойство не может доминировать над другим.