ML | Классификатор обучающих изображений с использованием API обнаружения объектов Tensorflow
Эта статья нацелена на то, чтобы узнать, как создать детектор объектов с помощью API обнаружения объектов Tensorflow.
Требование:
- Программирование на Python
- Основы машинного обучения
- Основы нейронных сетей (не обязательно)
- Энтузиазм при создании крутого проекта (обязательно): p
Даже если у вас нет первых трех предметов первой необходимости, добро пожаловать в приключение. Не бойтесь заблудиться, я проведу вас через все путешествие!
Что такое обнаружение объектов?
Обнаружение объектов - это процесс поиска экземпляров реальных объектов, таких как лица, здания и велосипед, на изображениях или видео. Алгоритмы обнаружения объектов обычно используют извлеченные функции и алгоритмы обучения для распознавания экземпляров категории объектов. Он обычно используется в таких приложениях, как поиск изображений, безопасность, наблюдение и современные системы помощи водителю (беспилотные автомобили). Я лично использовал обнаружение объектов для создания прототипа поисковой системы на основе изображений.
Что такое API обнаружения объектов Tensorflow?
Tensorflow - это платформа глубокого обучения с открытым исходным кодом, созданная Google Brain. API обнаружения объектов Tensorflow - это мощный инструмент, который позволяет каждому создавать свои собственные мощные классификаторы изображений. Для использования API обнаружения объектов Tensorflow не требуется никаких знаний в области кодирования или программирования. Но чтобы понять, что это работает, полезно знать программирование на Python и основы машинного обучения.
Прежде чем начать приключение, давайте убедимся, что Python 3 установлен в вашей системе.
Для установки python и pip см. Этот сайт
Перво-наперво! Убедитесь, что в вашей системе установлены указанные ниже пакеты. Они необходимы в вашем приключении.
pip install protobuf
pip install подушка
pip install lxml
pip установить Cython
pip install jupyter
pip install matplotlib
pip install pandas
pip установить opencv-python
pip install tensorflow
Чтобы начать приключение, мы должны получить автомобиль и внести в него необходимые изменения.
API обнаружения объектов Tensorflow
- Мы можем получить API обнаружения объектов Tensorflow из github
- Перейдите по предоставленной ссылке: Скачать здесь
После загрузки папки моделей распакуйте ее в каталог проекта. Мы можем найти каталог object_detection внутри
модели-мастер / исследования /
- Создание переменной PYTHONPATH:
Необходимо создать переменную PYTHONPATH, которая указывает на каталоги models, models research и models research slim. Выполните команду из любого каталога следующим образом. В моем случае,установите PYTHONPATH = F: Programming geeksforgeeks_project models-master; F: Programming geeksforgeeks_project models-master research; F: Programming geeksforgeeks_project models-master research slim
Компиляция файлов protobuf и запуск setup.py:
Необходимость компилировать файлы Protobuf, которые используются TensorFlow для настройки модели и параметров обучения.
Для компиляции файлов протоколов нам сначала нужно получить компилятор protobuf. Вы можете скачать это здесь. Загрузите файл protoc-3.8-win64.zip для ОС Windows, а для других операционных систем загрузите соответствующий zip-файл. Распакуйте папку bin в каталог исследований.
Скопируйте приведенный ниже код и сохраните его как use_protobuf.py в своем каталоге исследований.импорт ОС import sys args = sys.argv directory = args [1] protoc_path = аргументы [2] для файла в os.listdir (каталог): если file.endswith (". proto"): os.system (protoc_path + "" + каталог + "/" + файл + "--python_out =.")Перейдите в каталог исследований в командной строке и используйте команду, указанную ниже.
python use_protobuf.py. object_detection protos . bin protoc
Это компилирует все файлы protobuf и создает файл name_pb2.py из каждого файла name.proto в папке object_detection protos.
Наконец, выполните следующие команды из каталога models-master research:сборка python setup.py установка python setup.py
На этом установка завершена и установлен пакет с именем object-detection .
- Тестирование API:
Для тестирования API обнаружения объектов перейдите в каталог object_detection и введите следующую команду:блокнот jupyter object_detection_tutorial.ipynb
В браузере откроется блокнот jupyter.
Примечание. Если у вас есть строка sys.path.append («..») в первой ячейке записной книжки, удалите эту строку.Запустите все ячейки записной книжки и проверьте, получаете ли вы результат, похожий на изображение ниже:

Таким образом, мы успешно настроили наш автомобиль.
Начнем наше путешествие!
Чтобы добраться до места назначения, нам нужно пересечь 6 контрольных точек:
- Подготовка набора данных
- Маркировка набора данных
- Создание записей для обучения
- Настройка обучения
- Обучение модели
- Экспорт графа вывода
Спланируйте, какие объекты вы хотите обнаруживать с помощью классификатора.
- Контрольный пункт 1: Подготовка набора данных:
В этом приключении я собираюсь создать классификатор, который обнаруживает обувь и бутылки с водой. Помните, что набор данных - это самая важная вещь при построении классификатора. Это будет основой вашего классификатора, на котором будет выполняться обнаружение объектов. Собирайте как можно больше разных и разнообразных изображений, состоящих из предметов. Создайте каталог с именем images внутри каталога исследований. Сохраните 80% изображений в каталоге поездов и 20% изображений в тестовом каталоге внутри каталога изображений. Я собрал 50 изображений в каталоге поездов и 10 изображений в каталоге тестов. Чем больше количество изображений, тем выше точность вашего классификатора.
Изображения в каталоге поездов

Изображения в тестовом каталоге

- Контрольный пункт 2: маркировка набора данных:
Чтобы пересечь эту контрольную точку, нам нужен инструмент под названием labelimg . Вы можете скачать его здесь: labelimg downloadОткройте приложение labelimg и начните рисовать прямоугольники на изображении везде, где присутствует объект. И присвойте им подходящее имя, как показано на рисунке:
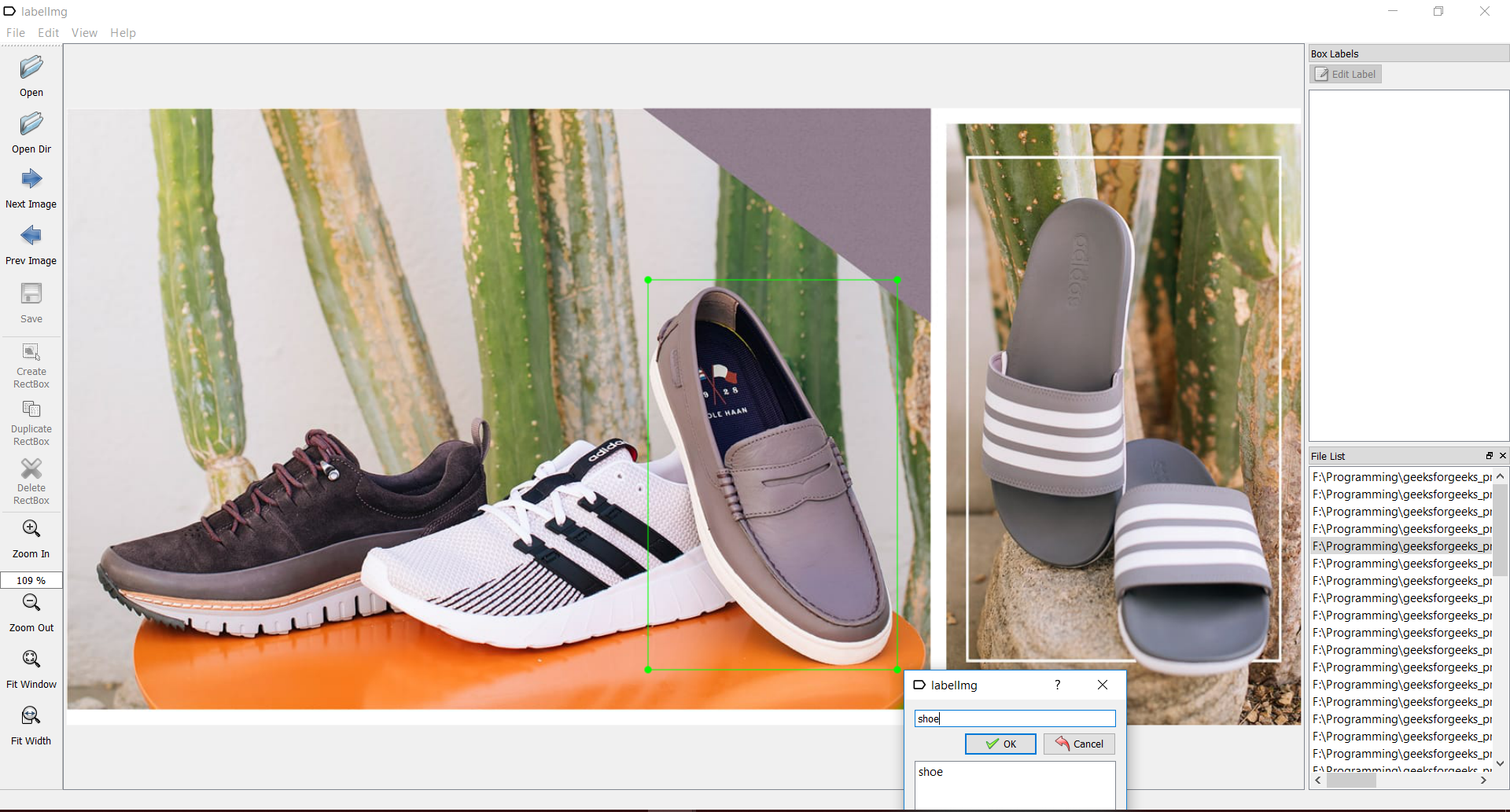
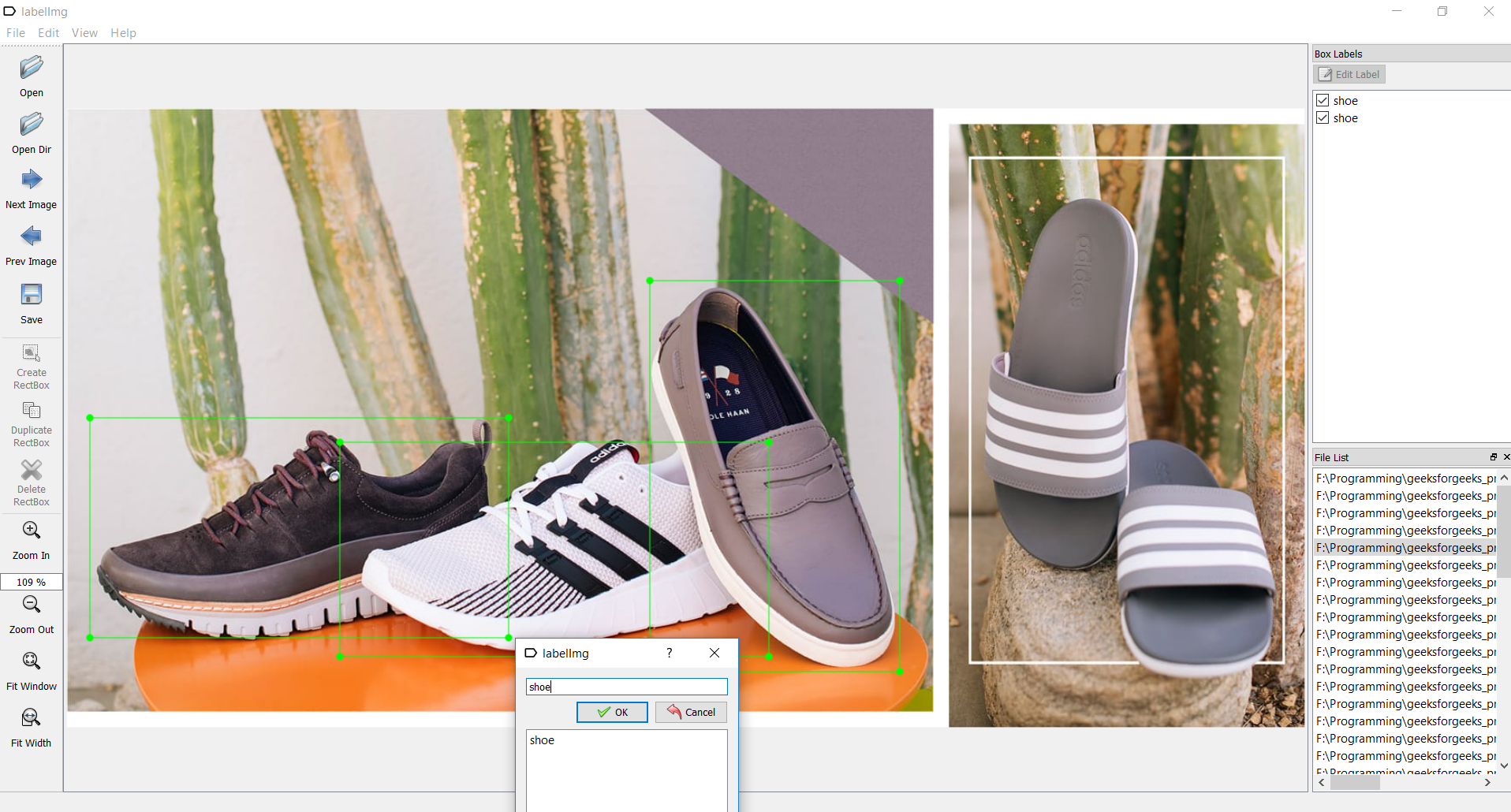
Сохраните каждое изображение после маркировки, которая создает XML-файл с соответствующим именем изображения, как показано на изображении ниже.

- Контрольный пункт 3: Создание записей для обучения:
Чтобы пересечь эту контрольную точку, нам нужно создать TFRecords, которые могут служить входными данными для обучения детектора объектов. Для создания TFRecords мы будем использовать два скрипта из Racoon Detector от Dat Tran. А именно файлы xml_to_csv.py и generate_tfrecord.py. Загрузите их и сохраните в папке object_detection.замените метод main () файла xml_to_csv.py следующим кодом:
def main (): для папки в ['train', 'test']: image_path = os.path.join (os.getcwd (), ('изображения /' + папка)) xml_df = xml_to_csv (путь_к изображению) xml_df.to_csv (('images /' + folder + '_ labels.csv'), index = None) print ('Успешно преобразован xml в csv.')А также добавьте следующие строки кода в метод xml_to_csv () перед оператором возврата, как показано на рисунке ниже.
имена = [] для i в xml_df ['filename']: names.append (я + '. jpg') xml_df ['filename'] = имена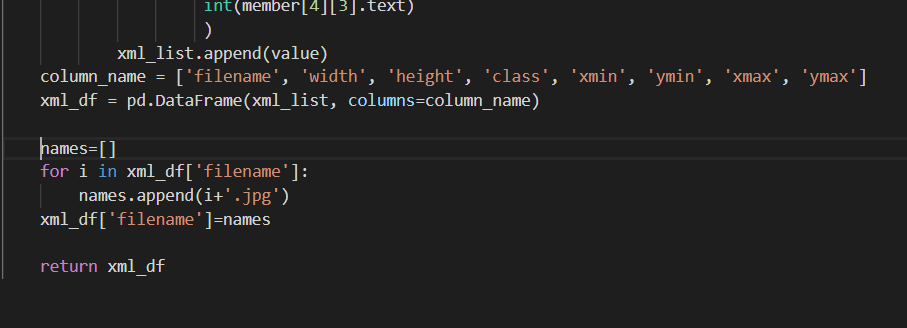
Сначала давайте преобразуем все файлы XML в файлы CSV, запустив файл xml_to_csv.py со следующей командой в каталоге object_detection:python xml_to_csv.py
В папке изображений будут созданы файлы test.csv и train.csv.
Затем откройте файл generate_tfrecord.py в текстовом редакторе и отредактируйте метод class_text_to_int (), который можно найти в строке 30, как показано на изображении ниже.
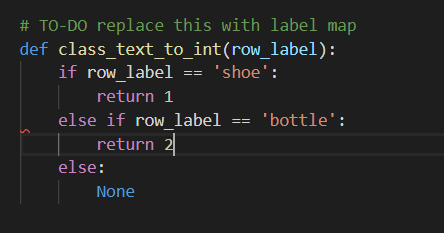
Затем сгенерируйте файлы TFRecord, выполнив эти команды из папки object_detection:
python generate_tfrecord.py --csv_input = images train_labels.csv --image_dir = images train --output_path = train.record python generate_tfrecord.py --csv_input = images test_labels.csv --image_dir = images test --output_path = test.record
Это создает файлы test.record и train.record в каталоге object_detection.
- Контрольный пункт 4: Настройка обучения:
Чтобы пересечь эту контрольную точку, нам сначала нужно создать карту меток.
Создайте новый каталог с именем training внутри каталога object_detection.
Используйте текстовый редактор, чтобы создать новый файл и сохранить его как labelmap.pbtxt в каталоге обучения. Карта меток сообщает обучающему, что представляет собой каждый объект, путем определения сопоставления имен классов с номерами идентификаторов классов.
Теперь добавьте содержимое в файл labelmap.pbtxt в следующем формате, чтобы создать карту меток для вашего классификатора.пункт { id: 1 имя: 'обувь' } пункт { id: 2 имя: 'бутылка' }Идентификационные номера карты меток должны совпадать с тем, что определено в файле generate_tfrecord.py.
Теперь приступим к настройке обучения!
Нам нужна модель, то есть алгоритм для обучения нашего классификатора. В этом проекте мы собираемся использовать модель fast_rcnn_inception. API обнаружения объектов Tensorflow поставляется с огромным количеством моделей. Перейдите в object_detection samples configs .
В этом месте вы можете найти множество файлов конфигурации для всех моделей, предоставляемых API. Скачать модель можно по этой ссылке. Загрузите файл fast_rcnn_inception_v2_coco . После завершения загрузки извлеките папку fast_rcnn_inception_v2_coco_2018_01_28 в каталог object_detection. Чтобы понять, как работает модель, обратитесь к этой статье.Поскольку в этом проекте мы используем модель Fast_rcnn_inception_v2_coco , скопируйте файл Fast_rcnn_inception_v2_coco.config из object_detection samples configs и вставьте его в каталог для обучения, созданный ранее.
С помощью текстового редактора откройте файл конфигурации и внесите следующие изменения в файл fast_rcnn_inception_v2_pets.config.
Примечание . Пути необходимо вводить с помощью одинарных косых черт (НЕ обратных косых черт), иначе TensorFlow выдаст ошибку пути к файлу при попытке обучения модели! Кроме того, пути должны быть заключены в двойные кавычки (”), а не в одинарные кавычки (').- Строка 10: Установите значение num_classes на количество объектов, которые классифицирует ваш классификатор. В моем случае, когда я классифицирую обувь и бутылки, это будет num_classes: 2.
- В строке 107: укажите абсолютный путь к файлу model.ckpt параметру file_tuning_checkpoint. Файл model.ckpt находится в местоположении object_detection / Fast_rcnn_inception_v2_coco_2018_01_28 . В моем случае,
fine_tune_checkpoint: «F: /Programming/geeksforgeeks_project/models-master/research/object_detection/faster_rcnn_inception_v2_coco_2018_01_28/model.ckpt»
- Раздел train_input_reader: вы можете найти этот раздел в строке 120. В этом разделе установите параметр input_path для вашего файла train.record. В моем случае это
input_path: «F: /Programming/geeksforgeeks_project/models-master/research/object_detection/train.record».Установите параметр label_map_path для файла labelmap.pbtxt. В моем случае это:
label_map_path: «F: /Programming/geeksforgeeks_project/models-master/research/object_detection/training/labelmap.pbtxt» - Раздел конфигурации eval: вы можете найти этот раздел в строке 128. установите параметр num_examples равным количеству изображений, присутствующих в тестовом каталоге. В моем случае,
num_examples: 10 - Раздел eval_input_reader: вы можете найти этот раздел в строке 134. Как и в разделе train_input_reader, установите пути к файлам test.record и labelmap.pbtxt. В моем случае,
input_path: «F: /Programming/geeksforgeeks_project/models-master/research/object_detection/train.record»label_map_path: «F: /Programming/geeksforgeeks_project/models-master/research/object_detection/training/labelmap.pbtxt»
На этом все настройки завершены, и мы собираемся добраться до нашей последней контрольной точки.
- Контрольный пункт 5: Обучение модели:
Наконец-то пришло время обучить нашу модель. Вы можете найти файл с именем train.py по адресу object_detection / legacy /.Скопируйте файл train.py и вставьте его в каталог object_detection.
Перейдите в каталог object_detection и выполните следующую команду, чтобы начать обучение вашей модели!python train.py --logtostderr --train_dir = обучение / --pipeline_config_path = обучение / быстрее_rcnn_inception_v2_coco.config
Инициализация настройки до начала обучения занимает около 1 минуты. Когда начинается тренировка, это выглядит так:
Tensorflow создает контрольную точку каждые 5 минут и сохраняет ее. Вы можете видеть, что все контрольные точки сохранены в каталоге обучения.
Вы можете следить за ходом обучения с помощью TensorBoard. Для этого откройте новую командную строку, перейдите в каталог object_detection и введите следующую команду:тензорборд --logdir = обучение
Тензорборд выглядит так:
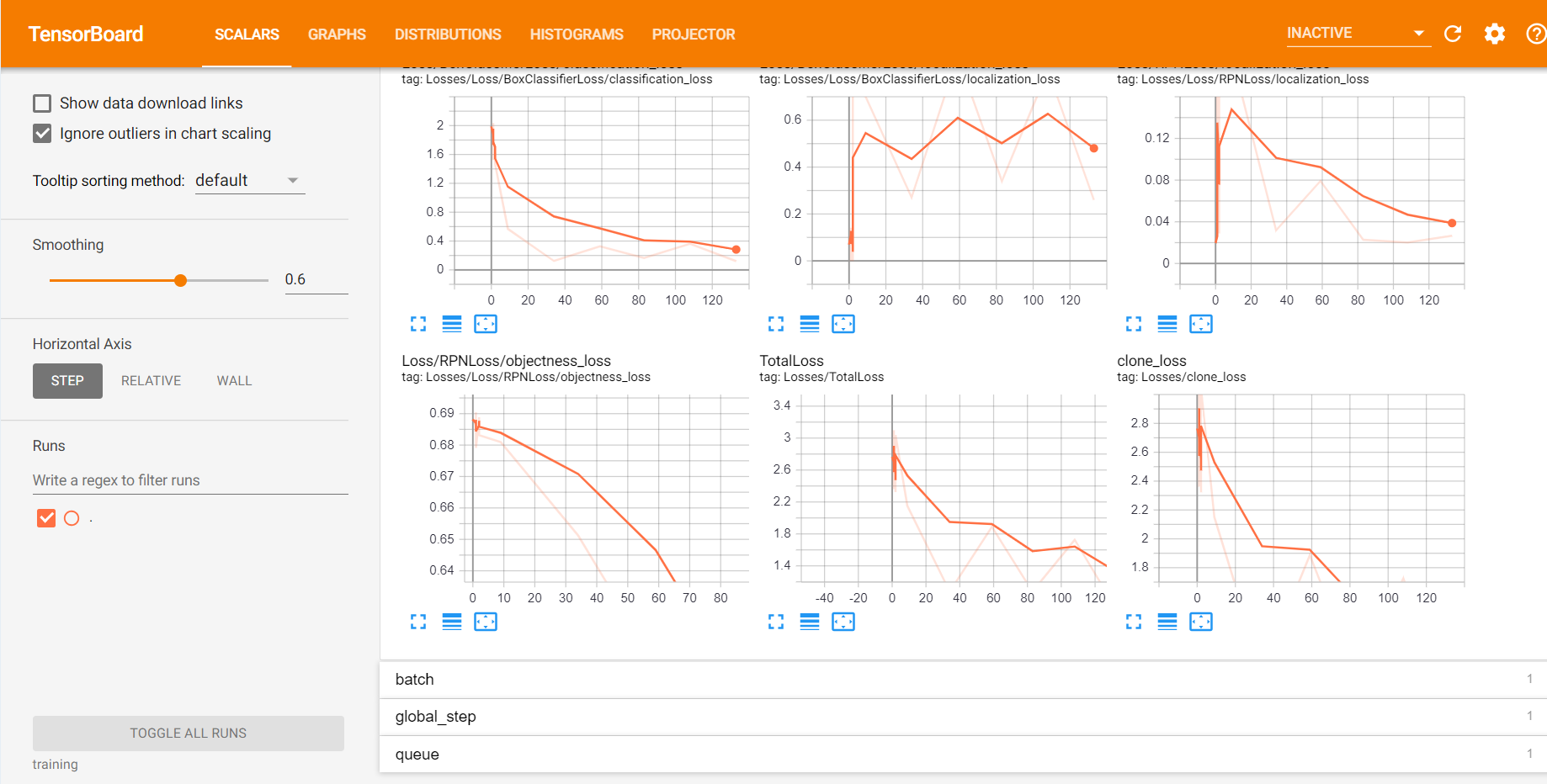
Продолжайте тренировочный процесс до тех пор, пока потеря не станет меньше или равна 0,1.
- Контрольный пункт 6: экспорт диаграммы вывода:
Это последний контрольно-пропускной пункт, который нужно пересечь, чтобы добраться до пункта назначения.
Теперь, когда у нас есть обученная модель, нам нужно создать граф вывода, который можно использовать для запуска модели. Для этого нам нужно сначала узнать наивысший сохраненный номер шага. Для этого нам нужно перейти в каталог обучения и найти файл model.ckpt с самым большим индексом.Затем мы можем создать граф вывода, введя следующую команду в командной строке.
python export_inference_graph.py --input_type image_tensor --pipeline_config_path training / Fast_rcnn_inception_v2_coco.config --trained_checkpoint_prefix training / model.ckpt-XXXX --output_directory inference_graph
XXXX должен быть заполнен по наивысшему номеру контрольной точки.
Это создает файл frozen_inference_graph.pb в папке object_detection inference_graph. Файл .pb содержит классификатор обнаружения объектов.
На этом мы закончили построение нашего классификатора. Все, что осталось завершить наше приключение, - это использовать нашу модель для обнаружения объектов.
создайте файл python в каталоге object_detection с помощью следующего кода:
# Write Python3 code hereimport osimport cv2import numpy as npimport tensorflow as tfimport sys # This is needed since the notebook is stored in the object_detection folder.sys.path.append( ".." ) # Import utilitesfrom utils import label_map_utilfrom utils import visualization_utils as vis_util # Name of the directory containing the object detection module we're usingMODEL_NAME = 'inference_graph' # The path to the directory where frozen_inference_graph is stored.IMAGE_NAME = '11man.jpg' # The path to the image in which the object has to be detected. # Grab path to current working directoryCWD_PATH = os.getcwd() # Path to frozen detection graph .pb file, which contains the model that is used# for object detection.PATH_TO_CKPT = os.path.join(CWD_PATH, MODEL_NAME, 'frozen_inference_graph.pb' ) # Path to label map filePATH_TO_LABELS = os.path.join(CWD_PATH, 'training' , 'labelmap.pbtxt' ) # Path to imagePATH_TO_IMAGE = os.path.join(CWD_PATH, IMAGE_NAME) # Number of classes the object detector can identifyNUM_CLASSES = 2 # Load the label map.# Label maps map indices to category names, so that when our convolution# network predicts `5`, we know that this corresponds to `king`.# Here we use internal utility functions, but anything that returns a# dictionary mapping integers to appropriate string labels would be finelabel_map = label_map_util.load_labelmap(PATH_TO_LABELS)categories = label_map_util.convert_label_map_to_categories( label_map, max_num_classes = NUM_CLASSES, use_display_name = True )category_index = label_map_util.create_category_index(categories) # Load the Tensorflow model into memory.detection_graph = tf.Graph()with detection_graph.as_default(): od_graph_def = tf.GraphDef() with tf.gfile.GFile(PATH_TO_CKPT, 'rb' ) as fid: serialized_graph = fid.read() od_graph_def.ParseFromString(serialized_graph) tf.import_graph_def(od_graph_def, name = '') sess = tf.Session(graph = detection_graph) # Define input and output tensors (ie data) for the object detection classifier # Input tensor is the imageimage_tensor = detection_graph.get_tensor_by_name( 'image_tensor:0' ) # Output tensors are the detection boxes, scores, and classes# Each box represents a part of the image where a particular object was detecteddetection_boxes = detection_graph.get_tensor_by_name( 'detection_boxes:0' ) # Each score represents level of confidence for each of the objects.# The score is shown on the result image, together with the class label.detection_scores = detection_graph.get_tensor_by_name( 'detection_scores:0' )detection_classes = detection_graph.get_tensor_by_name( 'detection_classes:0' ) # Number of objects detectednum_detections = detection_graph.get_tensor_by_name( 'num_detections:0' ) # Load image using OpenCV and# expand image dimensions to have shape: [1, None, None, 3]# ie a single-column array, where each item in the column has the pixel RGB valueimage = cv2.imread(PATH_TO_IMAGE)image_expanded = np.expand_dims(image, axis = 0 ) # Perform the actual detection by running the model with the image as input(boxes, scores, classes, num) = sess.run( [detection_boxes, detection_scores, detection_classes, num_detections], feed_dict = {image_tensor: image_expanded}) # Draw the results of the detection (aka 'visualize the results') vis_util.visualize_boxes_and_labels_on_image_array( image, np.squeeze(boxes), np.squeeze(classes).astype(np.int32), np.squeeze(scores), category_index, use_normalized_coordinates = True , line_thickness = 8 , min_score_thresh = 0.60 ) # All the results have been drawn on the image. Now display the image.cv2.imshow( 'Object detector' , image) # Press any key to close the imagecv2.waitKey( 0 ) # Clean upcv2.destroyAllWindows() |
В строке 17 укажите путь к изображению, на котором должен быть обнаружен объект.
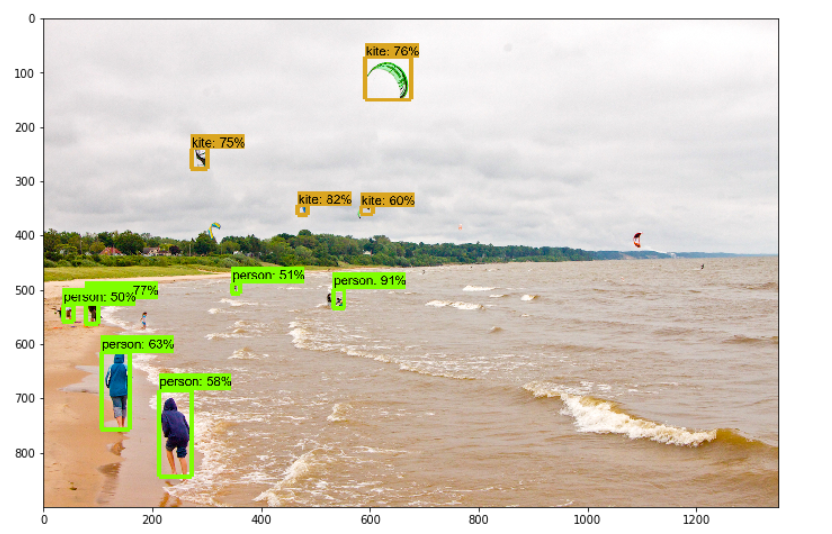
Ниже приведены некоторые результаты моей модели.

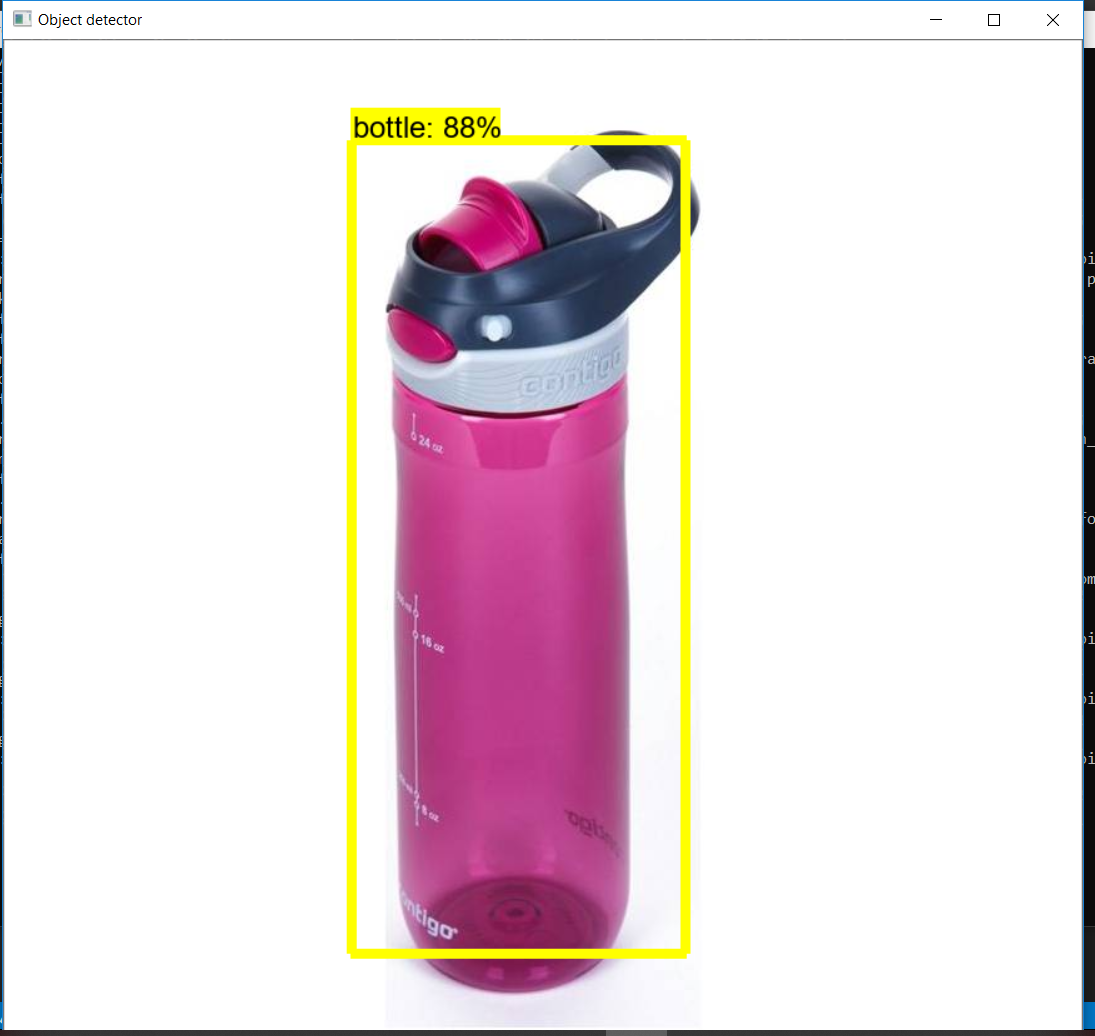
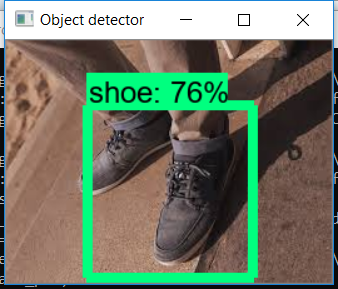


Итак, наконец, наша модель готова. Эта модель также использовалась для создания поисковой системы на основе изображений, которая выполняет поиск с использованием входных данных изображения путем обнаружения объектов на изображении.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.