Матрица неточностей в машинном обучении
Machine Learning – the study of computer algorithms that improve automatically through experience. It is seen as a subset of artificial intelligence.
Классификация - это процесс категоризации данного набора данных по классам.
В машинном обучении (ML) вы формируете проблему, собираете и очищаете данные, добавляете некоторые необходимые переменные функции (если есть), обучаете модель, измеряете ее производительность, улучшаете ее с помощью некоторой функции стоимости, а затем она готова к развертывать.
Но как измерить его эффективность? Есть ли какая-то особенность, на которую стоит обратить внимание?
Тривиальным и широким ответом было бы сравнение фактических значений с предсказанными значениями. Но это не решает проблемы.
Давайте рассмотрим знаменитый набор данных MNIST и попытаемся проанализировать проблему.
Python3
# Importing the dataset.from sklearn.datasets import fetch_openmlmnist = fetch_openml( 'mnist_784' , version = 1 )# Creating independent and dependent variables.X, y = mnist[ 'data' ], mnist[ 'target' ]# Splitting the data into training set and test set.X_train, X_test, y_train, y_test = X[: 60000 ], X[ 60000 :], y[: 60000 ], y[ 60000 :]"""The training set is already shuffled for us, which is good as this guarantees that allcross-validation folds will be similar."""# Training a binary classifier.y_train_5 = (y_train = = 5 ) # True for all 5s, False for all other digits.y_test_5 = (y_test = = 5 )"""Building a dumb classifier that just classifies every single image in the “not-5” class."""from sklearn.model_selection import cross_val_scorefrom sklearn.base import BaseEstimatorclass Never5Classifier(BaseEstimator): def fit( self , X, y = None ): pass def predict( self , X): return np.zeros(( len (X), 1 ), dtype = bool )never_5_clf = Never5Classifier()cross_val_score(never_5_clf, X_train, y_train_5, cv = 3 , scoring = "accuracy" ) |
Если вы выполните тот же код в среде IDE, вы получите массив точности, каждая с точностью более 90%! Это просто потому, что только около 10% изображений имеют пятерку, поэтому, если вы всегда предполагаете, что изображение не имеет пятерки, вы будете правы примерно в 90% случаев.
Это демонстрирует, почему точность обычно не является предпочтительным показателем производительности для классификаторов, особенно когда вы имеете дело с искаженными наборами данных (т. Е. Когда одни классы встречаются намного чаще, чем другие).
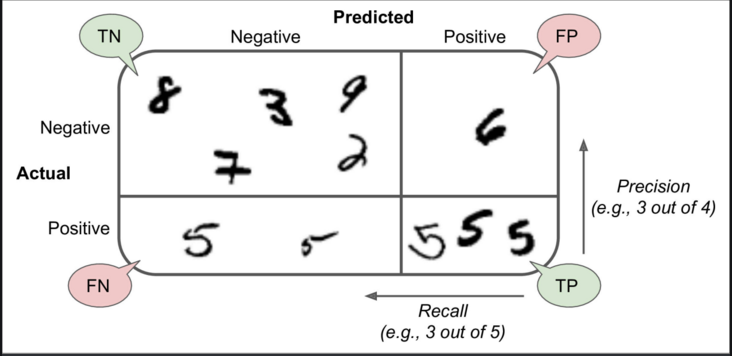
Матрица путаницы
Намного лучший способ оценить производительность классификатора - это посмотреть на матрицу неточностей. Общая идея состоит в том, чтобы подсчитать, сколько раз экземпляры класса A классифицируются как класс B. Например, чтобы узнать, сколько раз классификатор перепутал изображения 5 и 3, вы должны посмотреть в 5-ю строку и 3-й столбец таблицы матрица путаницы.
Каждая строка в матрице неточностей представляет фактический класс, а каждый столбец представляет предсказанный класс. Для получения дополнительной информации о матрице неточностей щелкните здесь.
Матрица путаницы дает вам много информации, но иногда вы можете предпочесть более сжатую метрику.
- Точность
точность = (TP) / (TP + FP)
TP - это количество истинных срабатываний, а FP - количество ложных срабатываний.
Тривиальный способ добиться идеальной точности - сделать один единственный положительный прогноз и убедиться, что он верен (точность = 1/1 = 100%). Это было бы не очень полезно, поскольку классификатор игнорировал бы все, кроме одного положительного экземпляра. - Отзывать
отзыв = (TP) / (TP + FN)
Python3
# Finding precision and recallfrom sklearn.metrics import precision_score, recall_scoreprecision_score(y_train_5, y_train_pred)recall_score(y_train_5, y_train_pred) |
Теперь ваш 5-детектор не выглядит таким блестящим, как если бы вы посмотрели на его точность. Когда он утверждает, что изображение представляет собой 5, оно является правильным только в 72,9% случаев (точность). Более того, он обнаруживает только 75,6% (отзыв) пятерок.
Часто бывает удобно объединить точность и отзыв в единую метрику, называемую оценкой F1, в частности, если вам нужен простой способ сравнения двух классификаторов.
Оценка F1 - это среднее гармоническое значение точности и запоминания.
Python3
# To compute the F1 score, simply call the f1_score() function:from sklearn.metrics import f1_scoref1_score(y_train_5, y_train_pred) |
Оценка F1 отдает предпочтение классификаторам, которые имеют аналогичную точность и отзывчивость.
Это не всегда то, что вам нужно: в некоторых контекстах вас больше волнует точность, а в других - действительно важен отзыв. Например, если вы обучили классификатор обнаруживать видео, безопасные для детей, вы, вероятно, предпочтете классификатор, который отклоняет много хороших видео (низкая запоминаемость), но сохраняет только безопасные (высокая точность), а не классификатор, который имеет много более высокий уровень запоминаемости, но позволяет отображать несколько ужасных видеороликов в вашем продукте (в таких случаях вы можете даже добавить человеческий конвейер для проверки выбора видео классификатором). С другой стороны, предположим, что вы обучаете классификатор обнаруживать воров в магазинах на изображениях наблюдения: вероятно, нормально, если ваш классификатор имеет точность только 30% при условии, что он имеет 99% отзыв (конечно, охранники получат несколько ложных предупреждений, но поймают почти всех воров).
К сожалению, у вас не может быть обоих вариантов: повышение точности снижает отзывчивость, и наоборот. Это называется компромиссом между точностью и отзывчивостью .