Математическое понимание РНС и ее вариантов
Вступление:
Эксперты ожидают, что искусственный интеллект (ИИ) будет работать над улучшением условий жизни. Они говорят, что по мере того, как в ближайшее время будет доступно больше вычислительных мощностей, то есть больше графических процессоров, ИИ будет делать больше и продуктивнее для людей. Сегодня можно увидеть множество таких приложений на базе искусственного интеллекта, таких как борьба с торговлей людьми, советник по здравоохранению, беспилотные автомобили, обнаружение и предотвращение вторжений, отслеживание и подсчет объектов, обнаружение и распознавание лиц, прогнозирование заболеваний и виртуальная помощь людям. помощь. В этом конкретном посте рассказывается о RNN, его вариантах (LSTM, GRU) и математике, лежащей в основе этого. RNN - это тип нейронной сети, которая принимает входные данные переменной длины и выдает выходные данные переменной длины. Он используется для разработки различных приложений, таких как преобразование текста в речь, чат-боты, языковое моделирование, сентиментальный анализ, прогнозирование запасов временных рядов, машинный перевод и распознавание сущностей nam.
Содержание:
- Что такое RNN и чем она отличается от нейронных сетей прямого распространения
- Математика, лежащая в основе RNN
- Варианты RNN (LSTM и GRU)
- Практическое применение RNN
- Заключительное примечание
Что такое RNN и чем она отличается от нейронных сетей прямого распространения:
RNN - это рекуррентная нейронная сеть, текущий выход которой зависит не только от его текущего значения, но и от прошлых входов, тогда как для сети с прямой связью текущий выход зависит только от текущего входа. Взгляните на приведенный ниже пример, чтобы лучше понять RNN.
Rahul belongs to congress.
Rahul is part of indian cricket team.
Если кого-то спросят, кто такой Рахул, он / она ответит, что оба Рахула разные, то есть один из индийского национального конгресса, а другой из индийской команды по крикету. Теперь, если та же самая задача дана машине для выдачи вывода, она не может сказать, пока не узнает полный контекст, т.е. предсказание идентичности отдельного слова зависит от знания всего контекста. Такие задачи могут быть реализованы с помощью Bi-LSTM, который является вариантом RNN. RNN подходят для такой работы благодаря своей способности изучать контекст. Другие приложения включают преобразование речи в текст, создание виртуальных помощников, прогнозирование запасов по временным рядам, сентиментальный анализ, языковое моделирование и машинный перевод. С другой стороны, нейронная сеть с прямой связью производит вывод, который зависит только от текущего ввода. Примерами таких задач являются задача классификации изображений, сегментация изображений или задача обнаружения объектов. Одним из таких типов такой сети является сверточная нейронная сеть (CNN). Помните, что и RNN, и CNN являются контролируемыми моделями глубокого обучения, то есть им нужны ярлыки на этапе обучения.
Математика, лежащая в основе RNN
1.) Математическое уравнение RNN
Чтобы понять математику, лежащую в основе RNN, взгляните на изображение ниже.
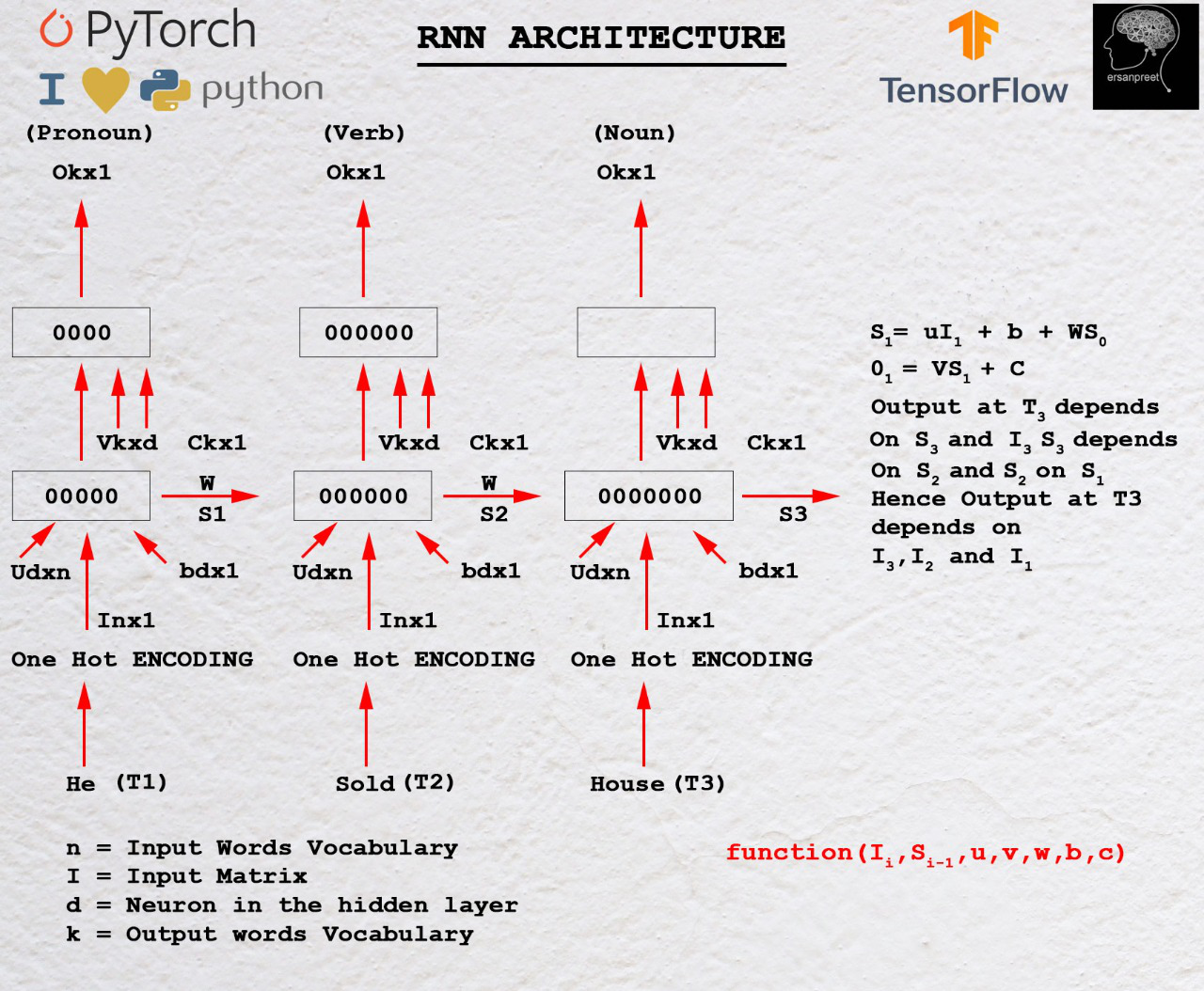
Математика, лежащая в основе RNN
Как уже говорилось в первом заголовке, вывод зависит как от текущих, так и от прошлых вводов. Пусть I 1 будет первым входом, размерность которого равна n * 1, где n - длина словаря. S 0 - это скрытое состояние для первой клетки РНС, имеющей d нейронов. Для каждой ячейки входное скрытое состояние должно быть одним предыдущим. Для первой ячейки инициализируйте S 0 нулями или каким-либо случайным числом, потому что предыдущего состояния не видно. U - другая матрица размерности d * n, где d - количество нейронов в первой ячейке RNN, а n - размер входного словаря. W - еще одна матрица, размерность которой равна d * d . b - смещение, размерность которого d * 1 . Для нахождения выхода из первой ячейки берется другая матрица V , размерность которой равна k * d, где c - смещение с размерностью k * 1 .
Математически выходы из первой ячейки RNN следующие:
S 1 = UI 1 + WS 0 + b O 1 = VS 1 + c
В общем,
S n = UI n + WS n-1 + b O n = VS n + c
Ключевой вывод из приведенного выше уравнения
В общем, выход O n зависит от S n, а S n зависит от S n-1 . S n-1 зависят от S n-2 . Процесс продолжается до достижения S 0. Это ясно демонстрирует, что выход на n- м временном шаге зависит от всех предыдущих входов.
2.) Параметры и градиенты
Параметры в RNN - это U, V, b, c, W , общие для всех ячеек RNN. Причина совместного использования - создать общую функцию, которая может применяться на всех временных шагах. Параметры доступны для обучения и отвечают за обучение модели. На каждом временном шаге потери вычисляются и передаются обратно через алгоритм градиентного спуска.
2.1) Градиент потерь по V
Градиент представляет собой наклон касательной и указывает в направлении наибольшей скорости увеличения функции. Нам интересно найти то V, где потери минимальны. Из потерь это означает функцию стоимости или ошибку. В простом смысле функция стоимости - это разница между истинным значением и прогнозируемым значением. Перемещение производится в направлении, противоположном направлению градиента потерь относительно V. Математически новое значение V получается с использованием нижеприведенной математической формулы
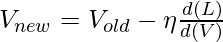
Где d (L) / d (V) - это сумма всех потерь, полученных на временных шагах. Есть два способа обновить веса. Один из них - вычислить градиент определенного пакета, а затем обновить его (мини-пакет) или рассчитать для каждого образца и обновления (стохастический). При вычислении d (L) / d (V) применяется цепное правило. Взгляните на рисунок ниже, чтобы понять правила расчета и цепочки.
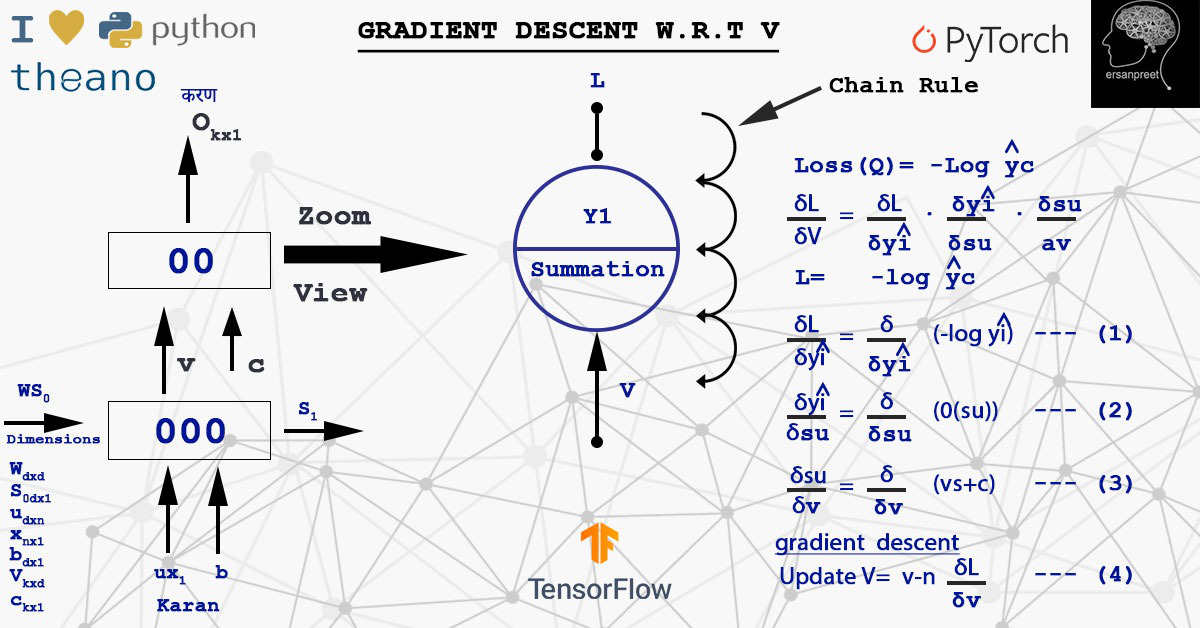
Реализация цепного правила для расчета градиента потерь по V
2.2) Градиент потерь по W
W умножается на S. Чтобы вычислить производную потерь по весу на любом временном шаге, применяется цепное правило для учета всего пути достижения W от S n до S 0 . Это означает, что из-за неправильного значения S n , пострадает W. Другими словами, некоторая неверная информация пришла из какого-то скрытого состояния, что приводит к потере. Математически вес обновляется, как показано ниже.
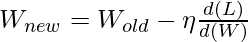
Ключевой момент, о котором следует помнить, заключается в том, что градиенты и веса обновляются при каждой выборке или после партии. Это зависит от выбранного алгоритма: стохастический или мини-пакет. Взгляните на приведенный ниже снимок экрана, чтобы визуализировать концепцию в более изысканной форме.
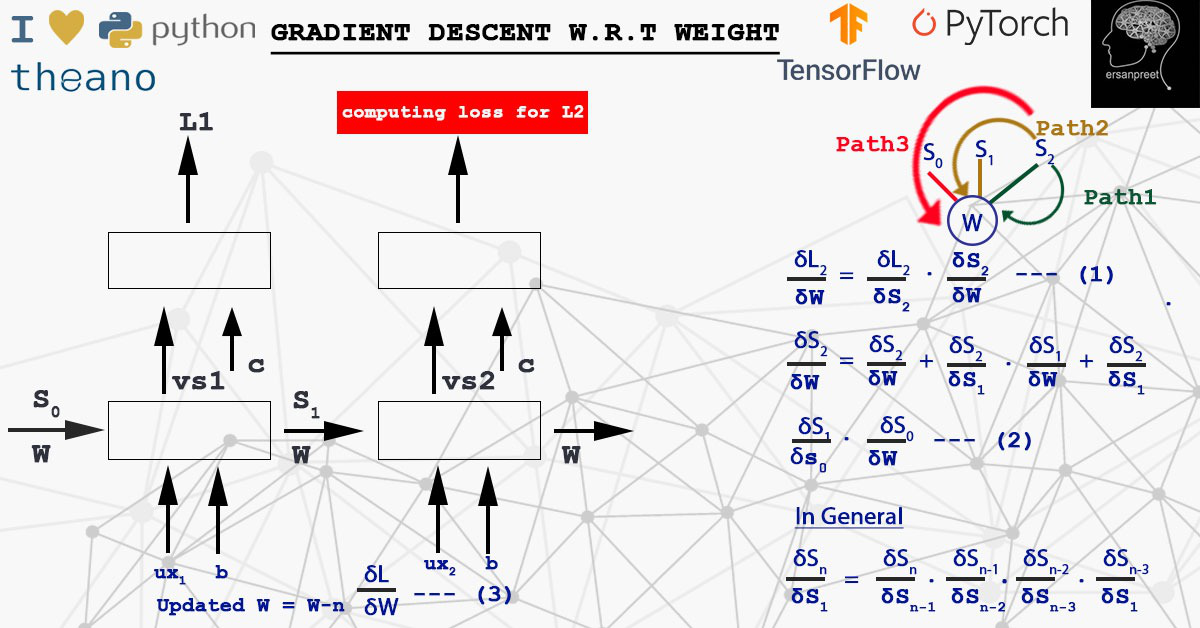
Градиентный спуск по W
Варианты RNN (LSTM и GRU)
Из приведенного выше обсуждения я надеюсь, что математика, лежащая в основе RNN, теперь ясна. Главный недостаток RNN - какой бы длины ни была последовательность, размерность вектора состояния остается прежней. Принимая во внимание случай, если длина входной последовательности очень велика, новая информация добавляется к тому же вектору состояния. Когда кто-то достигает n-го временного шага, который далеко от первого временного шага, информация становится очень запутанной. В таком положении неясно, какая информация была предоставлена на временном шаге 1 или 2. Это аналогично доске, размер которой фиксирован, и на ней продолжают писать. В некоторых местах становится очень неаккуратно. Невозможно даже прочитать то, что написано на борту. Для решения подобных проблем были разработаны его варианты, так называемые LSTM и GRU. Они работают по принципу выборочного чтения, записи и забывания. Теперь доска ( аналог вектора состояния ) такая же, но только желаемая информация записывается на временном шаге, а ненужная информация отфильтровывается, что делает последовательную нейронную сеть подходящей для обучения с длинными последовательностями. Здесь можно прочитать разницу между LSTM и GRU.
LSTM (долгосрочная краткосрочная память)
Математическое представление:
Используемая стратегия - выборочная запись, чтение и забывание.
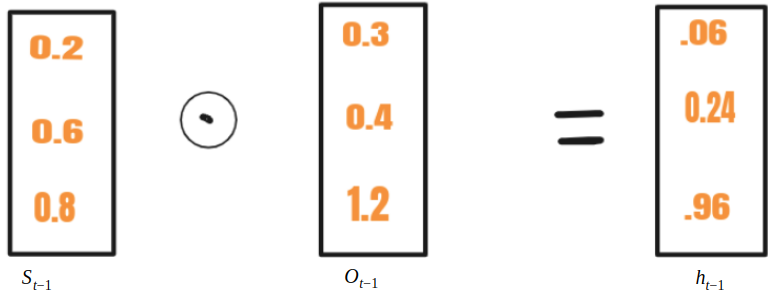
Выборочная запись
Выборочная запись:
В RNN S t- 1 подается вместе с x t в ячейку, тогда как в LSTM S t-1 преобразуется в h t-1 используя другой вектор O t-1 . Этот процесс называется выборочной записью . Математические уравнения для выборочной записи приведены ниже.
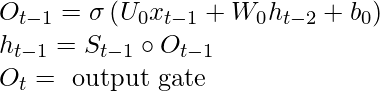
Выборочное чтение:
Взгляните на изображение ниже, чтобы понять концепцию.
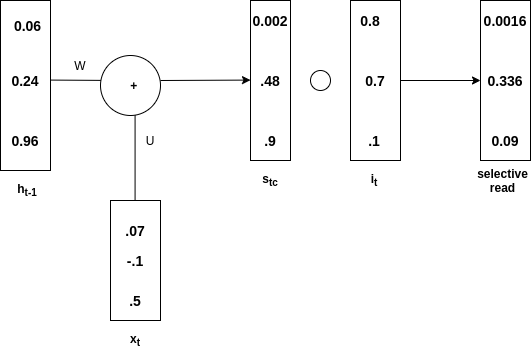
Выборочное чтение
ч т-1 добавляется с x t для получения s t . Тогда произведение Адамара 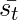 ( на схеме написано s tc ), и это делается для получения s t . Это называется входным вентилем . Т только селективная информация в сек идет , и этот процесс называется селективным чтением. Математически уравнения для выборочного чтения выглядят следующим образом:
( на схеме написано s tc ), и это делается для получения s t . Это называется входным вентилем . Т только селективная информация в сек идет , и этот процесс называется селективным чтением. Математически уравнения для выборочного чтения выглядят следующим образом:
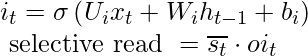
Селективное забвение:
Взгляните на изображение ниже, чтобы понять концепцию.
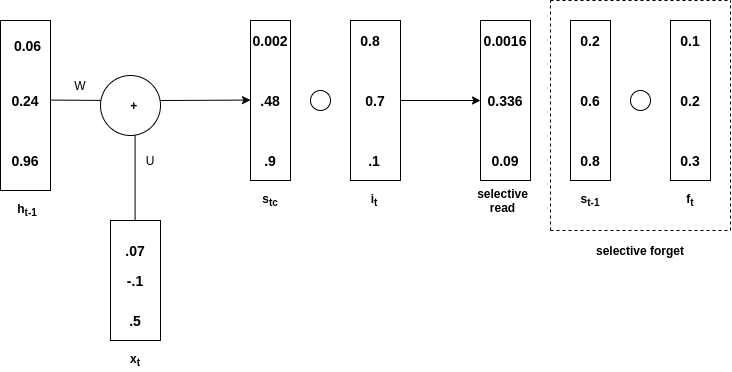
Селективное забвение
с т-1 является произведением хадамара с f t и называется выборочным забыванием . Общий s t получается сложением выборочного чтения и выборочного забывания. См. Диаграмму ниже, чтобы понять приведенное выше утверждение.
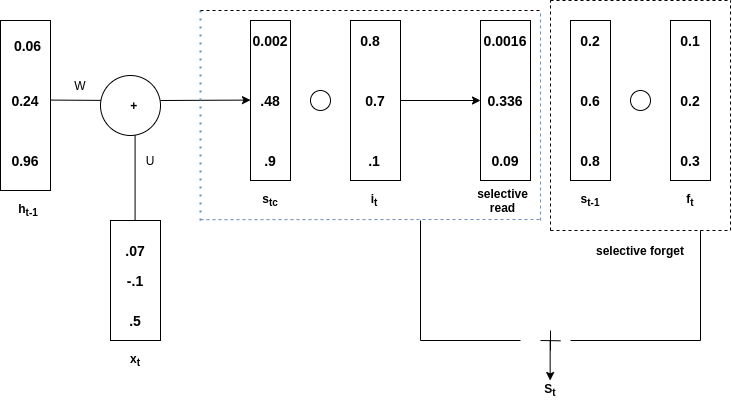
добавление выборочного чтения и забывания
Математически уравнения для выборочного забывания выглядят так:
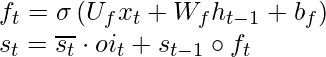
Примечание. В случае GRU (Gated Recurrent Unit) нет ворот для забывания. У него есть только входные и выходные ворота.
Практическое применение RNN:
RNN находит свое применение в преобразовании речи в текст, создании виртуальной помощи, сентиментальном анализе, прогнозировании запасов временных рядов, машинном переводе, языковом моделировании. Продолжаются исследования по созданию генеративных чат-ботов с использованием RNN и ее вариантов. Другие приложения включают в себя подписи к изображениям, создание большого текста из небольшого абзаца и средство суммирования текста (такое приложение, как Inshorts, использует это). Музыкальная композиция и анализ колл-центра - это другие области, в которых используется RNN.
Заключительное примечание:
Вкратце, можно понять разницу между RNN и нейронной сетью прямого распространения из первого абзаца, а затем углубиться в математику, лежащую в основе RNN. В конце статьи объясняются различные варианты RNN и некоторые практические применения RNN. Чтобы работать с приложениями RNN, нужно получить глубокие знания в области исчисления, производных, особенно о том, как работает правило цепочки. После изучения теории некоторые коды по этим темам должны быть написаны на вашем любимом языке программирования. Это даст вам преимущество.