Маска R-CNN | ML
Более быстрые R-CNN и YOLO хорошо обнаруживают объекты на входном изображении. Они также имеют очень низкое время обнаружения и могут использоваться в системах реального времени. Однако есть проблема, с которой невозможно справиться с обнаружением объекта, ограничивающая рамка, созданная YOLO и Faster R-CNN, не дает никаких указаний о форме объекта.
Сегментация экземпляра:
Эта сегментация идентифицирует каждый экземпляр (появление каждого объекта, присутствующего в изображении, и окрашивание их в разные пиксели). Он в основном работает для классификации местоположения каждого пикселя и создания маски сегментации для каждого из объектов изображения. Этот подход дает больше информации об объектах на изображении, потому что он сохраняет безопасность этих объектов, распознавая их.

Сегментация экземпляра (Источник: ссылка)
Архитектура Mask R-CNN: Маска R-CNN была предложена Kaiming He et al. в 2017 году. Он очень похож на Faster R-CNN, за исключением того, что есть еще один уровень для сегментированного прогнозирования. Этап создания предложения региона одинаков как в архитектуре, так и на втором этапе, который работает в параллельном классе прогнозирования, генерирует ограничивающую рамку, а также выводит двоичную маску для каждого RoI.

Он состоит из -
- Магистральная сеть
- Сеть предложений региона
- Представление маски
- RoI Align
Магистральная сеть:
Авторы Mask R-CNN экспериментировали с двумя типами магистральных сетей. Первая - это стандартная архитектура ResNet (ResNet-C4), а вторая - это ResNet с сетью пирамиды функций. Стандартная архитектура ResNet была похожа на архитектуру Faster R-CNN, но ResNet-FPN предложила некоторые модификации. Он состоит из многоуровневого поколения RoI. Эта многослойная сеть с пирамидой функций генерирует RoI разного масштаба, что повышает точность предыдущей архитектуры ResNet.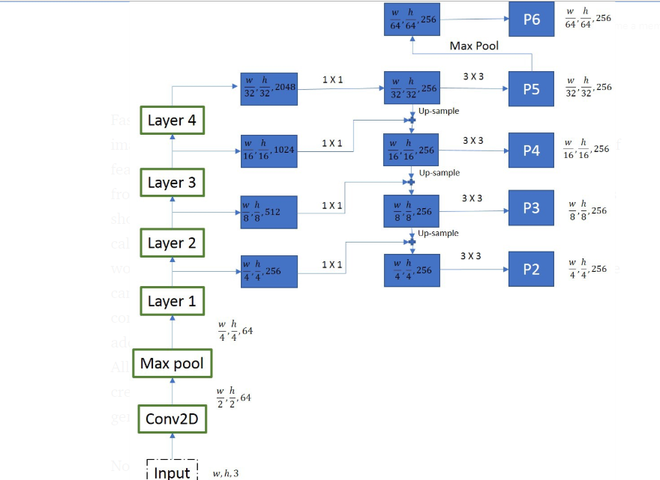
На каждом слое размер карт объектов уменьшается вдвое, а количество карт объектов удваивается. Мы взяли выход из четырех слоев (слой - 1, 2, 3 и 4) . Чтобы сгенерировать окончательные карты функций, мы используем подход, называемый «путь сверху-снизу». Мы начинаем с верхней карты функций (w / 32, h / 32, 256) и спускаемся к более крупным с помощью операций масштабирования. Перед повышающей дискретизацией мы также применяем свертку 1 * 1, чтобы уменьшить количество каналов до 256 . Затем он поэлементно добавляется к выходным данным с повышенной дискретизацией из предыдущей итерации. Все выходные данные подвергаются сверточному слою 3 X 3, чтобы создать окончательные 4 карты характеристик (P2, P3, P4, P5) . Пятая карта характеристик (P6) генерируется из операции максимального объединения из P5 .
Сеть предложений региона:
Вся карта функций свертки, созданная предыдущим слоем, проходит через слой свертки 3 * 3. Результат этого затем передается в две параллельные ветви, которые определяют оценку объектности и регрессируют координаты ограничивающего прямоугольника.

Здесь мы используем только один шаг привязки и 3 соотношения привязки для пирамиды функций (потому что у нас уже есть карты функций разных размеров для проверки объектов разного размера).
Представление маски:
Маска содержит пространственную информацию об объекте. Таким образом, в отличие от слоев регрессии классификации и ограничивающей рамки, мы не могли свернуть вывод до полностью подключенного слоя для улучшения, так как для этого требуется соответствие пикселя с пикселем из вышеупомянутого слоя. Маска R-CNN использует полностью подключенную сеть для прогнозирования маски. Эта ConvNet принимает на вход RoI и выводит представление маски m * m. Мы также масштабируем эту маску для вывода на входное изображение и уменьшаем количество каналов до 256, используя свертку 1 * 1. Чтобы сгенерировать входные данные для этой полностью подключенной сети, которая прогнозирует маску, мы используем RoIAlign. Цель RoIAlign - использовать преобразование карты функций разного размера, созданной сетью региональных предложений, в карту функций фиксированного размера. В статье Mask R-CNN было предложено два варианта архитектуры. В одном варианте вход CNN генерации маски передается после применения RoIAlign (ResNet C4), но в другом варианте вход передается непосредственно перед полностью подключенным слоем (сеть FPN).

(Источник: ссылка)
Эта ветвь генерации маски является полностью сверточной сетью и выводит K * (m * m) , где K - количество классов (по одному для каждого класса) и m = 14 для ResNet-C4 и 28 для ResNet_FPN .
RoI Align:
Выравнивание RoI имеет тот же мотив, что и пул RoI, - генерировать регионы фиксированного размера на основе предложений регионов. Он работает в следующих этапах: 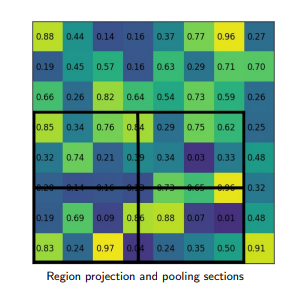
Учитывая карту характеристик предыдущего слоя свертки размером h * w , разделите эту карту характеристик на сетки M * N равного размера (мы НЕ будем просто брать целочисленное значение).
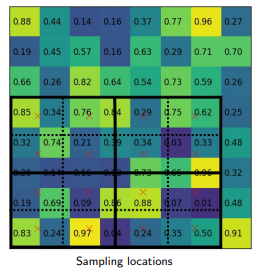
Скорость вывода R-CNN по маске составляет около 2 кадров в секунду , что хорошо, учитывая добавление сегмента сегментации в архитектуре.
Приложения :
Благодаря дополнительной способности генерировать сегментированные маски, он используется во многих приложениях компьютерного зрения, таких как:
- Оценка позы человека
- Самостоятельное вождение автомобиля
- Отображение изображений дрона и т. Д.
Справка:
- Маска из бумаги R-CNN
- Маска слайдов R-CNN
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.