Логистическая регрессия в программировании на R
Логистическая регрессия в программировании на R - это алгоритм классификации, используемый для определения вероятности успешного и неудачного события. Логистическая регрессия используется, когда зависимая переменная является двоичной (0/1, Истина / Ложь, Да / Нет) по своей природе. Функция логита используется как функция связи в биномиальном распределении.
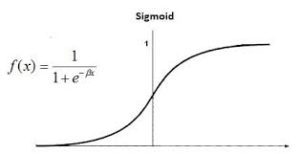
Логистическая регрессия также известна как биномиальная логистическая регрессия . Он основан на сигмоидной функции, где выход - это вероятность, а вход может быть от -infinity до + infinity.
Теория
Логистическая регрессия также известна как обобщенная линейная модель. Поскольку он используется в качестве метода классификации для прогнозирования качественного ответа, значение y варьируется от 0 до 1 и может быть представлено следующим уравнением:
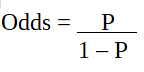
p - вероятность интересующей характеристики. Отношение шансов определяется как вероятность успеха по сравнению с вероятностью неудачи. Это ключевое представление коэффициентов логистической регрессии, которое может принимать значения от 0 до бесконечности. Отношение шансов 1 - это когда вероятность успеха равна вероятности неудачи. Отношение шансов 2 - это когда вероятность успеха в два раза больше, чем вероятность неудачи. Отношение шансов 0,5 - это когда вероятность неудачи в два раза больше вероятности успеха.
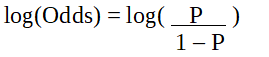
Поскольку мы работаем с биномиальным распределением (зависимой переменной), нам нужно выбрать функцию связи, которая лучше всего подходит для этого распределения.
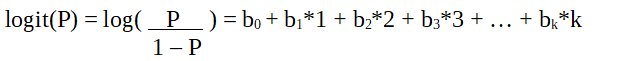
Это функция логита . В приведенном выше уравнении круглые скобки выбраны, чтобы максимизировать вероятность наблюдения значений выборки, а не минимизировать сумму квадратов ошибок (как обычная регрессия). Логит также известен как журнал шансов. Функция logit должна быть линейно связана с независимыми переменными. Это из уравнения A, где левая часть представляет собой линейную комбинацию x. Это похоже на предположение OLS о том, что y линейно связано с x.
Переменные b0, b1, b2… и т. Д. Неизвестны и должны быть оценены по имеющимся обучающим данным. В модели логистической регрессии умножение b1 на одну единицу изменяет логит на b0. Изменение P из-за изменения на одну единицу будет зависеть от умноженного значения. Если b1 положительно, то P будет увеличиваться, а если b1 отрицательно, то P будет уменьшаться.
Набор данных
mtcars ) включает в себя расход топлива, характеристики и 10 аспектов автомобильной конструкции для 32 автомобилей. Он поставляется с dplyr пакетом dplyr в R.
# Installing the packageinstall.packages( "dplyr" ) # Loading packagelibrary(dplyr) # Summary of dataset in packagesummary(mtcars) |
Выполнение логистической регрессии для набора данных
Логистическая регрессия реализована в R с использованием glm() путем обучения модели с использованием функций или переменных в наборе данных.
# Installing the packageinstall.packages( "caTools" ) # For Logistic regressioninstall.packages( "ROCR" ) # For ROC curve to evaluate model # Loading packagelibrary(caTools)library(ROCR) # Splitting datasetsplit < - sample.split(mtcars, SplitRatio = 0.8 )split train_reg < - subset(mtcars, split = = "TRUE" )test_reg < - subset(mtcars, split = = "FALSE" ) # Training modellogistic_model < - glm(vs ~ wt + disp, data = train_reg, family = "binomial" )logistic_model # Summarysummary(logistic_model) # Predict test data based on modelpredict_reg < - predict(logistic_model, test_reg, type = "response" )predict_reg # Changing probabilitiespredict_reg < - ifelse(predict_reg > 0.5 , 1 , 0 ) # Evaluating model accuracy# using confusion matrixtable(test_reg$vs, predict_reg) missing_classerr < - mean(predict_reg ! = test_reg$vs)print (paste( 'Accuracy =' , 1 - missing_classerr)) # ROC-AUC CurveROCPred < - prediction(predict_reg, test_reg$vs)ROCPer < - performance(ROCPred, measure = "tpr" , x.measure = "fpr" ) auc < - performance(ROCPred, measure = "auc" )auc < - auc@y.values[[ 1 ]]auc # Plotting curveplot(ROCPer)plot(ROCPer, colorize = TRUE, print .cutoffs.at = seq( 0.1 , by = 0.1 ), main = "ROC CURVE" )abline(a = 0 , b = 1 ) auc < - round (auc, 4 )legend(. 6 , . 4 , auc, title = "AUC" , cex = 1 ) |
wt положительно влияет на зависимые переменные, и увеличение веса на одну единицу увеличивает логарифм шансов для vs = 1 на 1,44. disp отрицательно влияет на зависимые переменные, и увеличение disp на одну единицу уменьшает логарифм шансов для vs = 1 на 0,0344. Нулевое отклонение составляет 31,755 (соответствие зависимой переменной с перехватом), а остаточное отклонение - 14,457 (соответствие зависимой переменной со всеми независимыми переменными). Значение AIC (критерий щелочной информации) составляет 20,457, т.е. чем меньше, тем лучше для модели. Точность составляет 0,75, т. Е. 75%.
Модель оценивается с использованием матрицы неточностей, кривой AUC (площадь под кривой) и ROC (рабочие характеристики приемника). В матрице неточностей мы должны искать не всегда точность, но также чувствительность и специфичность. Построена кривая ROC и AUC.
Выход:
- Оценка точности модели с использованием матрицы неточностей:
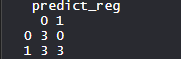
Имеется 0 ошибок типа 2, т.е. невозможно отклонить ошибку, если она ложна. Кроме того, есть 3 ошибки типа 1, т.е. отклонение, когда оно истинно.
- Кривая ROC:
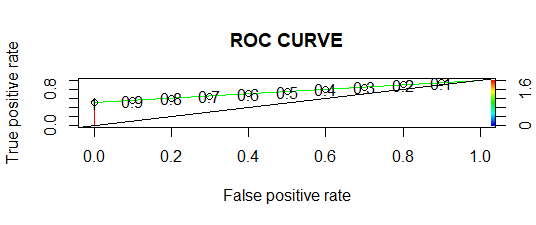
В кривой ROC, чем больше площадь под кривой, тем лучше модель.
- Кривая ROC-AUC:
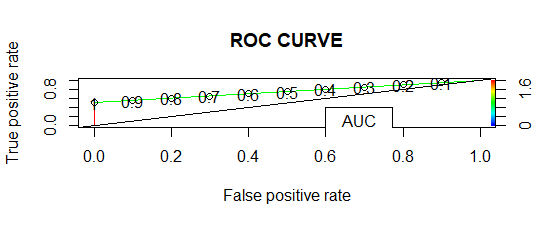
AUC составляет 0,7333, поэтому чем больше AUC, тем лучше работает модель.