Кластеризация в программировании на R
Кластеризация в R - это метод обучения без учителя, при котором набор данных разбивается на несколько групп, называемых кластерами, на основе их сходства. После сегментации данных создается несколько кластеров данных. Все объекты в кластере имеют общие характеристики. Во время интеллектуального анализа и анализа данных для поиска похожих наборов данных используется кластеризация.
Приложения кластеризации в R
- Маркетинг: в программировании на R кластеризация полезна в области маркетинга. Это помогает найти рыночную модель и, таким образом, найти вероятных покупателей. Учет интересов клиентов с помощью кластеризации и демонстрация того же продукта, который их интересует, может увеличить вероятность покупки продукта.
- Медицинская наука: в области медицины ежедневно появляются новые лекарства и методы лечения. Иногда новые виды также находят исследователи и ученые. Их категорию можно легко найти с помощью алгоритма кластеризации, основанного на их сходстве.
- Игры: Алгоритм кластеризации также можно использовать для демонстрации игр пользователю в зависимости от его интересов.
- Интернет: пользователь просматривает много веб-сайтов в зависимости от своего интереса. Историю просмотров можно объединить для выполнения кластеризации, и на основе результатов кластеризации создается профиль пользователя.
Методы кластеризации
В программировании на R существует 2 типа кластеризации:
- Жесткая кластеризация: в этом типе кластеризации точка данных либо принадлежит кластеру полностью, либо нет, и точка данных назначается только одному кластеру. Алгоритм, используемый для жесткой кластеризации, - это кластеризация k-средних.
- Мягкая кластеризация: при мягкой кластеризации вероятность или вероятность точки данных назначается в кластерах, а не помещается каждая точка данных в кластер. Каждая точка данных существует во всех кластерах с некоторой вероятностью. Алгоритм, используемый для мягкой кластеризации, - это метод нечеткой кластеризации или мягкое k-среднее.
Кластеризация K-средних в R
K-Means - это метод итеративной жесткой кластеризации, использующий алгоритм обучения без учителя. При этом общее количество кластеров заранее определяется пользователем, и на основе сходства каждой точки данных точки данных группируются. Этот алгоритм также определяет центроид кластера.
Алгоритм:
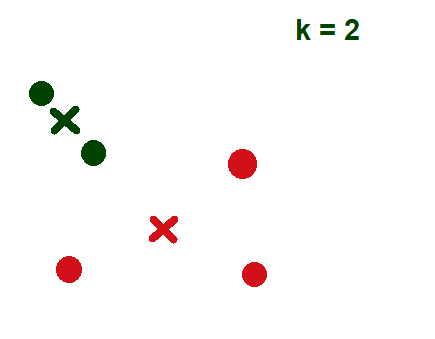
- Укажите количество кластеров (K): Давайте возьмем пример k = 2 и 5 точек данных.
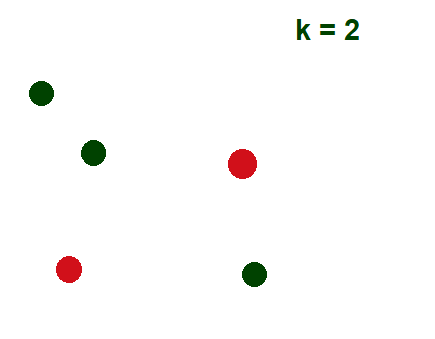
- Случайным образом назначьте каждую точку данных кластеру: В приведенном ниже примере красным и зеленым цветом показаны 2 кластера с назначенными им соответствующими случайными точками данных.
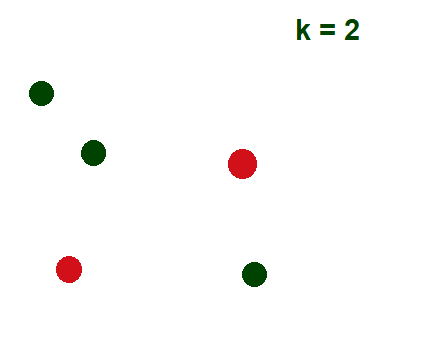
- Вычислить центроиды кластера: крестик представляет собой центроид соответствующего кластера.
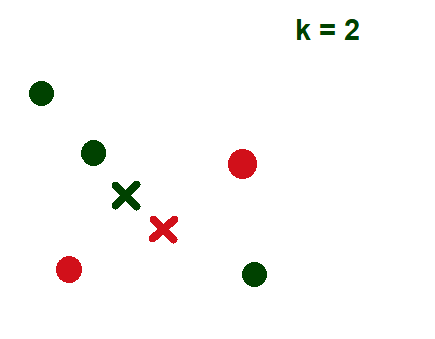
- Перераспределите каждую точку данных по ближайшему центроиду кластера: зеленая точка данных назначается красному кластеру, так как она находится рядом с центроидом красного кластера.
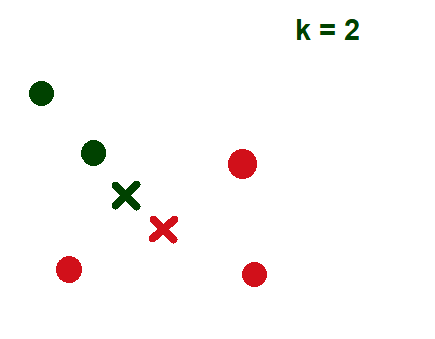
- Изобразить центроид кластера
Синтаксис:
kmeans (x, центры, nstart)
где,
x represents numeric matrix or data frame object
centers represents the K value or distinct cluster centers
nstart represents number of random sets to be chosen
Пример:
# Library required for fviz_cluster functioninstall.packages( "factoextra" )library(factoextra) # Loading datasetdf < - mtcars # Omitting any NA valuesdf < - na.omit(df) # Scaling datasetdf < - scale(df) # output to be present as PNG filepng( file = "KMeansExample.png" ) km < - kmeans(df, centers = 4 , nstart = 25 ) # Visualize the clustersfviz_cluster(km, data = df) # saving the filedev.off() # output to be present as PNG filepng( file = "KMeansExample2.png" ) km < - kmeans(df, centers = 5 , nstart = 25 ) # Visualize the clustersfviz_cluster(km, data = df) # saving the filedev.off() |
Выход:
Когда k = 4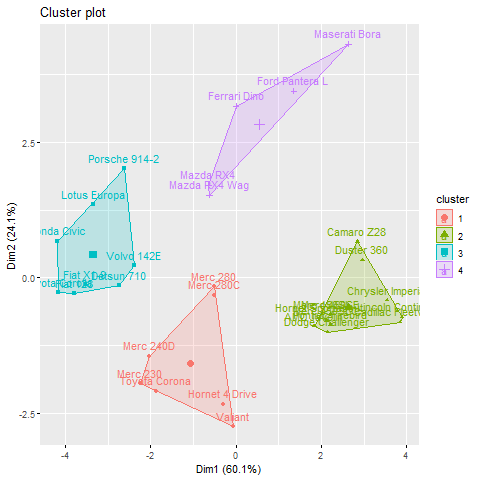
Когда k = 5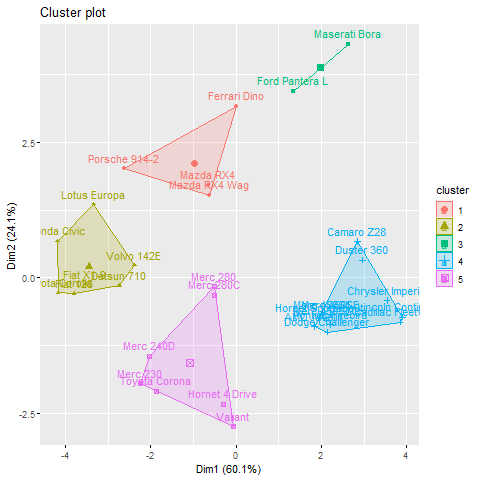
Кластеризация путем агрегирования сходства
Кластеризация путем агрегирования сходства также известна как реляционная кластеризация или метод Кондорсе, который сравнивает каждую точку данных попарно со всеми другими точками данных. Для пары значений A и B эти значения присваиваются как векторам m (A, B), так и d (A, B). A и B одинаковы по m (A, B), но разные по d (A, B).
where, S is the cluster
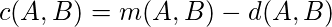
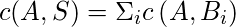
По первому условию создается кластер, а со следующим условием вычисляется глобальный критерий Кондорсе. Он выполняется итеративно до тех пор, пока указанные итерации не будут завершены или глобальный критерий Кондорсе не приведет к улучшению.