Кластеризация DBScan в программировании на R
Кластеризация приложений с шумом на основе плотности (DBScan) - это нелинейный алгоритм с обучением без учителя. Он действительно использует идею плотности достижимости и плотности связи. Данные разбиты на группы со схожими характеристиками или кластеры, но не требует предварительного указания количества этих групп. Кластер определяется как максимальный набор плотно связанных точек. Он обнаруживает кластеры произвольной формы в пространственных базах данных с шумом.
Теория
В кластеризации DBScan зависимость от расстояния-кривой размерности больше. Алгоритм следующий:
- Произвольно выберите точку p .
- Получите все точки, плотность которых достижима из p, с учетом максимального радиуса окрестности (EPS) и минимального количества точек в окрестности eps (Min Pts).
- Если количество точек в окрестности больше, чем Min Pts, тогда p является базовой точкой.
- Для p узловых точек формируется кластер. Если точка p не является основной, отметьте ее как шум / выброс и перейдите к следующей точке.
- Продолжайте процесс, пока все точки не будут обработаны.
Кластеризация DBScan нечувствительна к порядку.
Набор данных
Iris данных ириса состоит из 50 образцов каждого из 3 видов ириса (Iris setosa, Iris virginica, Iris versicolor) и многомерного набора данных, представленного британским статистиком и биологом Рональдом Фишером в его статье 1936 года Использование множественных измерений в таксономических задачах. В каждом образце были измерены четыре характеристики, то есть длина и ширина чашелистиков и лепестков, и на основе комбинации этих четырех характеристик Фишер разработал линейную дискриминантную модель, чтобы отличить виды друг от друга.
# Loading datadata(iris) # Structurestr (iris) |

Выполнение DBScan для набора данных
Использование алгоритма кластеризации DBScan для набора данных, который включает 11 человек и 6 переменных или атрибутов
# Installing Packagesinstall.packages( "fpc" ) # Loading packagelibrary(fpc) # Remove label form datasetiris_1 < - iris[ - 5 ] # Fitting DBScan clustering Model# to training datasetset .seed( 220 ) # Setting seedDbscan_cl < - dbscan(iris_1, eps = 0.45 , MinPts = 5 )Dbscan_cl # Checking clusterDbscan_cl$cluster # Tabletable(Dbscan_cl$cluster, iris$Species) # Plotting Clusterplot(Dbscan_cl, iris_1, main = "DBScan" )plot(Dbscan_cl, iris_1, main = "Petal Width vs Sepal Length" ) |
Выход:
- Модель dbscan_cl:
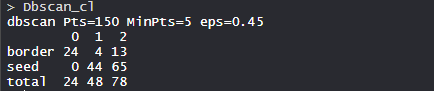
В модели 150 баллов, минимальные баллы - 5, eps - 0,5.
- Идентификация кластера:

Показаны кластеры в модели.
- Построение кластера:
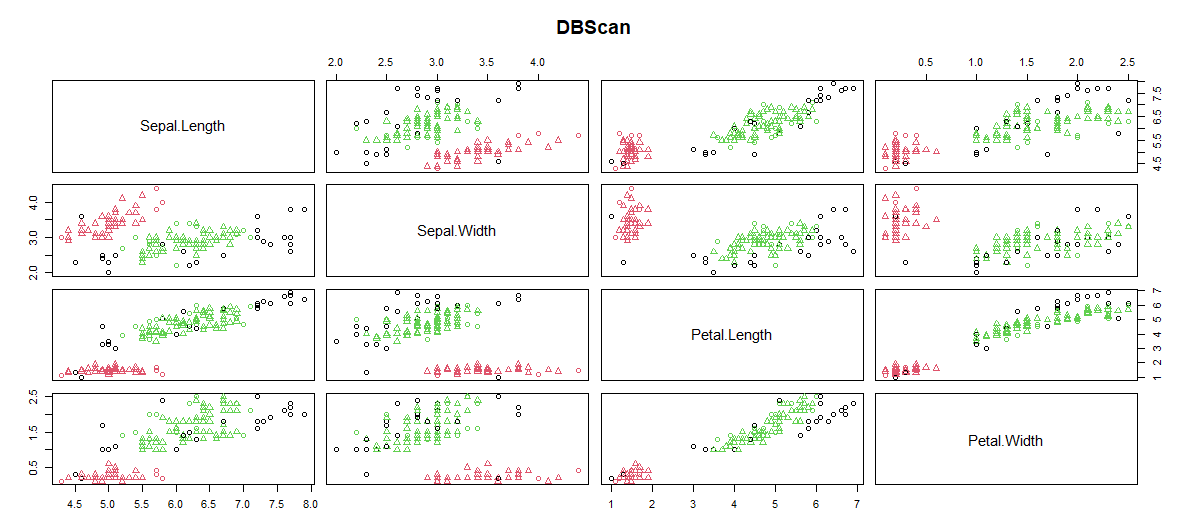
Кластер DBScan строится с помощью Sepal.Length, Sepal.Width, Petal.Length, Petal.Width.
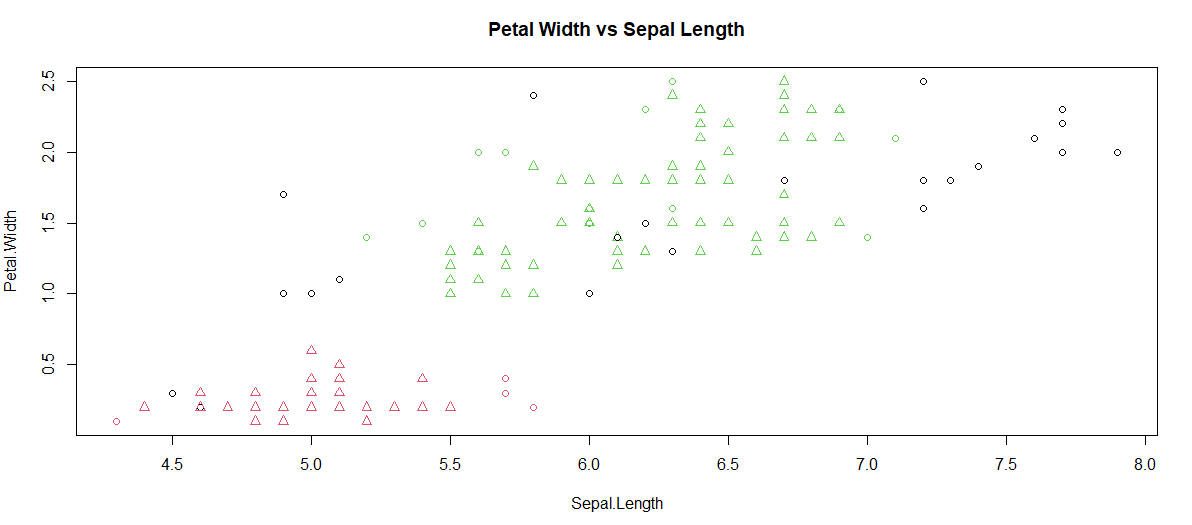
График построен между Petal.Width и Sepal.Length.
Таким образом, алгоритм кластеризации DBScan также может формировать необычные формы, которые полезны для поиска кластера нелинейных форм в отрасли.