Классификатор K-NN в программировании на R
K-Nearest Neighbor или K-NN - это контролируемый нелинейный алгоритм классификации. K-NN - это непараметрический алгоритм, то есть он не делает никаких предположений о базовых данных или их распределении. Это один из самых простых и широко используемых алгоритмов, который зависит от его значения k (соседи) и находит применение во многих отраслях, таких как финансовая промышленность, здравоохранение и т. Д.
Теория
В алгоритме KNN K указывает количество соседей, и его алгоритм выглядит следующим образом:
- Выберите число K соседа.
- Возьмите K ближайшего соседа неизвестной точки данных в соответствии с расстоянием.
- Среди K-соседей подсчитайте количество точек данных в каждой категории.
- Назначьте новую точку данных категории, в которой вы посчитали наибольшее количество соседей.
Для классификатора ближайшего соседа расстояние между двумя точками выражается в форме евклидова расстояния.
Пример:
Рассмотрим набор данных, содержащий две характеристики: красный и синий, и мы их классифицируем. Здесь K равно 5, т.е. мы рассматриваем 5 соседей в соответствии с евклидовым расстоянием.
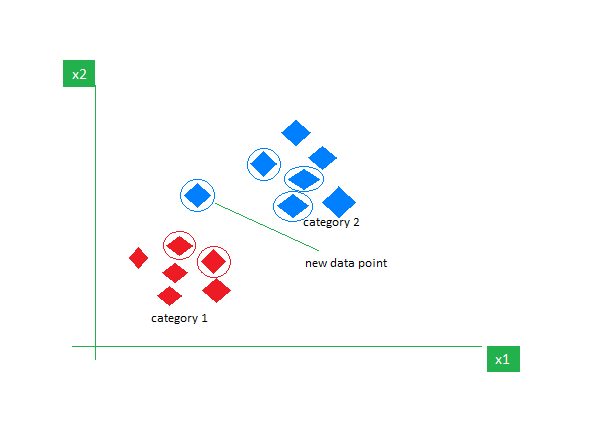
Итак, когда входит новая точка данных, из 5 соседей 3 - синие, а 2 - красные. Мы присваиваем новую точку данных категории с наибольшим количеством соседей, то есть синей.
Набор данных
Iris dataset consists of 50 samples from each of 3 species of Iris(Iris setosa, Iris virginica, Iris versicolor) and a multivariate dataset introduced by British statistician and biologist Ronald Fisher in his 1936 paper The use of multiple measurements in taxonomic problems. Four features were measured from each sample i.e length and width of the sepals and petals and based on the combination of these four features, Fisher developed a linear discriminant model to distinguish the species from each other.
# Loading datadata(iris) # Structure str(iris) |

Выполнение K ближайшего соседа в наборе данных
Using the K-Nearest Neighbor algorithm on the dataset which includes 11 persons and 6 variables or attributes.
# Installing Packagesinstall.packages("e1071")install.packages("caTools")install.packages("class") # Loading packagelibrary(e1071)library(caTools)library(class) # Loading datadata(iris)head(iris) # Splitting data into train# and test datasplit <- sample.split(iris, SplitRatio = 0.7)train_cl <- subset(iris, split == "TRUE")test_cl <- subset(iris, split == "FALSE") # Feature Scalingtrain_scale <- scale(train_cl[, 1:4])test_scale <- scale(test_cl[, 1:4]) # Fitting KNN Model # to training datasetclassifier_knn <- knn(train = train_scale, test = test_scale, cl = train_cl$Species, k = 1)classifier_knn # Confusiin Matrixcm <- table(test_cl$Species, classifier_knn)cm # Model Evaluation - Choosing K# Calculate out of Sample errormisClassError <- mean(classifier_knn != test_cl$Species)print(paste("Accuracy =", 1-misClassError)) # K = 3classifier_knn <- knn(train = train_scale, test = test_scale, cl = train_cl$Species, k = 3)misClassError <- mean(classifier_knn != test_cl$Species)print(paste("Accuracy =", 1-misClassError)) # K = 5classifier_knn <- knn(train = train_scale, test = test_scale, cl = train_cl$Species, k = 5)misClassError <- mean(classifier_knn != test_cl$Species)print(paste("Accuracy =", 1-misClassError)) # K = 7classifier_knn <- knn(train = train_scale, test = test_scale, cl = train_cl$Species, k = 7)misClassError <- mean(classifier_knn != test_cl$Species)print(paste("Accuracy =", 1-misClassError)) # K = 15classifier_knn <- knn(train = train_scale, test = test_scale, cl = train_cl$Species, k = 15)misClassError <- mean(classifier_knn != test_cl$Species)print(paste("Accuracy =", 1-misClassError)) # K = 19classifier_knn <- knn(train = train_scale, test = test_scale, cl = train_cl$Species, k = 19)misClassError <- mean(classifier_knn != test_cl$Species)print(paste("Accuracy =", 1-misClassError)) |
Выход:
- Модель classifier_knn (k = 1):
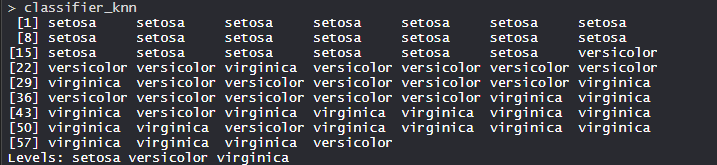
Модель KNN оснащена последовательностью, тестом и значением k. Кроме того, в модель встроена функция классификатора видов.
- Матрица неточностей:
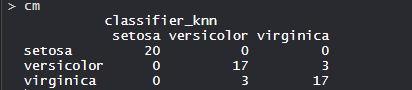
Итак, 20 сетос правильно классифицируются как сетоса. Из 20 разноцветных сортов 17 правильно классифицируются как разноцветные, а 3 классифицируются как вирджиника. Из 20 вирджиники 17 вирджиника правильно классифицируются как вирджиника, а 3 - как разноцветные.
- Оценка модели:
(к = 1)
Модель достигла точности 90% при k = 1.
(К = 3)

Модель достигла точности 88,33% при k = 3, что ниже, чем при k = 1.
(К = 5)

Модель достигла точности 91,66% при k = 5, что больше, чем при k = 1 и 3.
(К = 7)

Модель достигла точности 93,33% при k = 7, что больше, чем при k = 1, 3 и 5.
(К = 15)

Модель достигла точности 95% при k = 15, что больше, чем при k = 1, 3, 5 и 7.
(К = 19)

Модель достигла 95% точности при k = 19, что больше, чем при k = 1, 3, 5 и 7. Такая же точность при k = 15, что означает, что теперь увеличение значений k не влияет на точность.
Итак, K Nearest Neighbor широко используется в отрасли.