K означает кластеризацию - Введение
Нам предоставляется набор данных элементов с определенными функциями и значениями для этих функций (например, вектор). Задача состоит в том, чтобы разделить эти предметы на группы. Для этого мы будем использовать алгоритм kMeans; алгоритм обучения без учителя.
Обзор
(Это поможет, если вы будете думать о предметах как о точках в n-мерном пространстве). Алгоритм разделит элементы на k групп сходства. Чтобы вычислить это сходство, мы будем использовать евклидово расстояние в качестве меры.
Алгоритм работает следующим образом:
- Сначала мы случайным образом инициализируем k точек, называемых средними.
- Мы классифицируем каждый элемент по его ближайшему среднему значению и обновляем координаты среднего значения, которые являются средними значениями элементов, отнесенных к этому среднему значению на данный момент.
- Мы повторяем процесс для заданного количества итераций, и в конце у нас есть кластеры.
Вышеупомянутые «точки» называются средними, потому что они содержат средние значения элементов, отнесенных к этой категории. Для инициализации этих средств у нас есть много вариантов. Интуитивно понятный метод - инициализировать средние значения случайными элементами в наборе данных. Другой метод - инициализировать средние значения случайными значениями между границами набора данных (если для характеристики x элементы имеют значения в [0,3], мы инициализируем средние значениями для x в [0,3]) .
Вышеупомянутый алгоритм в псевдокоде:
Инициализировать k средних со случайными значениями
Для заданного количества итераций:
Перебирать элементы:
Найдите среднее значение, наиболее близкое к элементу
Присвойте элемент значению
Обновить среднее
Прочитать данные
Мы получаем ввод в виде текстового файла ('data.txt'). Каждая строка представляет элемент и содержит числовые значения (по одному для каждой функции), разделенные запятыми. Здесь вы можете найти образец набора данных.
Мы будем читать данные из файла, сохраняя их в список. Каждый элемент списка - это еще один список, содержащий значения элементов для функций. Мы делаем это с помощью следующей функции:
def ReadData(fileName): # Read the file, splitting by lines f = open (fileName, 'r' ); lines = f.read().splitlines(); f.close(); items = []; for i in range ( 1 , len (lines)): line = lines[i].split( ',' ); itemFeatures = []; for j in range ( len (line) - 1 ): # Convert feature value to float v = float (line[j]); # Add feature value to dict itemFeatures.append(v); items.append(itemFeatures); shuffle(items); return items; |
Инициализировать средства
Мы хотим инициализировать каждое среднее значение в диапазоне значений характеристик элементов. Для этого нам нужно найти минимальное и максимальное значение для каждой функции. Мы достигаем этого с помощью следующей функции:
def FindColMinMax(items): n = len (items[ 0 ]); minima = [sys.maxint for i in range (n)]; maxima = [ - sys.maxint - 1 for i in range (n)]; for item in items: for f in range ( len (item)): if (item[f] < minima[f]): minima[f] = item[f]; if (item[f] > maxima[f]): maxima[f] = item[f]; return minima,maxima; |
Переменные minima, maxima представляют собой списки, содержащие минимальные и максимальные значения элементов соответственно. Мы случайным образом инициализируем значения характеристик каждого среднего между соответствующим минимумом и максимумом в этих двух списках:
def InitializeMeans(items, k, cMin, cMax): # Initialize means to random numbers between # the min and max of each column/feature f = len (items[ 0 ]); # number of features means = [[ 0 for i in range (f)] for j in range (k)]; for mean in means: for i in range ( len (mean)): # Set value to a random float # (adding +-1 to avoid a wide placement of a mean) mean[i] = uniform(cMin[i] + 1 , cMax[i] - 1 ); return means; |
Евклидово расстояние
Мы будем использовать евклидово расстояние в качестве метрики сходства для нашего набора данных (примечание: в зависимости от ваших элементов вы можете использовать другую метрику сходства).
def EuclideanDistance(x, y): S = 0 ; # The sum of the squared differences of the elements for i in range ( len (x)): S + = math. pow (x[i] - y[i], 2 ) #The square root of the sum return math.sqrt(S) |
Средства обновления
Чтобы обновить среднее значение, нам нужно найти среднее значение для его характеристики для всех элементов в среднем / кластере. Мы можем сделать это, сложив все значения, а затем разделив их на количество элементов, или мы можем использовать более элегантное решение. Мы рассчитаем новое среднее значение без повторного добавления всех значений, выполнив следующие действия:
т = (т * (п-1) + х) / п
где m - среднее значение для функции, n - количество элементов в кластере, а x - значение функции для добавленного элемента. Мы проделываем вышеуказанное для каждой функции, чтобы получить новое среднее значение.
def UpdateMean(n,mean,item): for i in range ( len (mean)): m = mean[i]; m = (m * (n - 1 ) + item[i]) / float (n); mean[i] = round (m, 3 ); return mean; |
Классифицировать предметы
Теперь нам нужно написать функцию для классификации элемента в группу / кластер. Для данного элемента мы найдем его сходство с каждым средним значением и классифицируем этот элемент как наиболее близкий.
def Classify(means,item): # Classify item to the mean with minimum distance minimum = sys.maxint; index = - 1 ; for i in range ( len (means)): # Find distance from item to mean dis = EuclideanDistance(item, means[i]); if (dis < minimum): minimum = dis; index = i; index; return |
Найдите средства
Чтобы на самом деле найти средства, мы переберем все элементы, классифицируем их до ближайшего кластера и обновим среднее значение кластера. Мы повторим процесс для некоторого фиксированного количества итераций. Если между двумя итерациями ни один элемент не меняет классификацию, мы останавливаем процесс, поскольку алгоритм нашел оптимальное решение.
Следующая функция принимает в качестве входных данных k (количество желаемых кластеров), элементы и количество максимальных итераций и возвращает средние значения и кластеры. Классификация элемента хранится в массиве ownTo, а количество элементов в кластере хранится в clusterSizes .
def CalculateMeans(k,items,maxIterations = 100000 ): # Find the minima and maxima for columns cMin, cMax = FindColMinMax(items); # Initialize means at random points means = InitializeMeans(items,k,cMin,cMax); # Initialize clusters, the array to hold # the number of items in a class clusterSizes = [ 0 for i in range ( len (means))]; # An array to hold the cluster an item is in belongsTo = [ 0 for i in range ( len (items))]; # Calculate means for e in range (maxIterations): # If no change of cluster occurs, halt noChange = True ; for i in range ( len (items)): item = items[i]; # Classify item into a cluster and update the # corresponding means. index = Classify(means,item); clusterSizes[index] + = 1 ; cSize = clusterSizes[index]; means[index] = UpdateMean(cSize,means[index],item); # Item changed cluster if (index ! = belongsTo[i]): noChange = False ; belongsTo[i] = index; # Nothing changed, return if (noChange): break ; return means; |
Найти кластеры
Наконец, мы хотим найти кластеры, учитывая средства. Мы переберем все элементы и классифицируем каждый элемент по ближайшему кластеру.
def FindClusters(means,items): clusters = [[] for i in range ( len (means))]; # Init clusters for item in items: # Classify item into a cluster index = Classify(means,item); # Add item to cluster clusters[index].append(item); return clusters; |
Другие широко используемые меры сходства:
1. Косинусное расстояние: определяет косинус угла между точечными векторами двух точек в n-мерном пространстве.

2. Манхэттенское расстояние: вычисляет сумму абсолютных разностей между координатами двух точек данных.
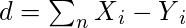
3. Расстояние Минковского: оно также известно как метрика обобщенного расстояния. Его можно использовать как для порядковых, так и для количественных переменных.
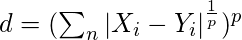
Вы можете найти весь код на моем GitHub вместе с образцом данных и функцией построения графиков. Спасибо за прочтение.
Автор статьи: Антонис Марониколакис . Если вам нравится GeeksforGeeks, и вы хотели бы внести свой вклад, вы также можете написать статью с помощью provide.geeksforgeeks.org или отправить ее по электронной почте на deposit@geeksforgeeks.org. Посмотрите, как ваша статья появляется на главной странице GeeksforGeeks, и помогите другим гикам.
Пожалуйста, напишите комментарии, если вы обнаружите что-то неправильное, или вы хотите поделиться дополнительной информацией по теме, обсужденной выше.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.