K-Ближайшие соседи
K-Nearest Neighbours - один из самых простых, но важных алгоритмов классификации в машинном обучении. Он относится к области контролируемого обучения и находит широкое применение в распознавании образов, интеллектуальном анализе данных и обнаружении вторжений.
Он широко используется в реальных сценариях, поскольку он непараметрический, что означает, что он не делает никаких основополагающих предположений о распределении данных (в отличие от других алгоритмов, таких как GMM, которые предполагают гауссово распределение заданных данных) .
Нам даются некоторые предварительные данные (также называемые обучающими данными), которые классифицируют координаты по группам, определяемым атрибутом.
В качестве примера рассмотрим следующую таблицу точек данных, содержащую две функции: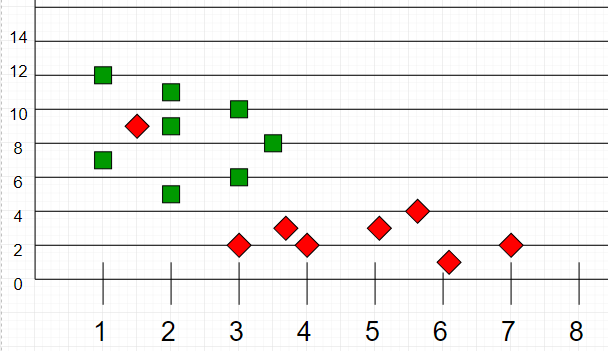
Теперь, учитывая другой набор точек данных (также называемых данными тестирования), распределите эти точки по группе, проанализировав обучающий набор. Обратите внимание, что неклассифицированные точки помечены как «белые».
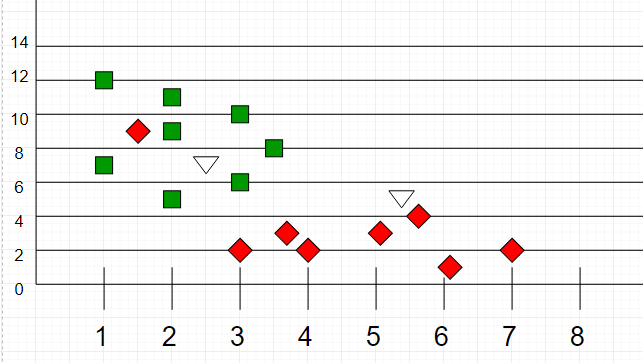
Интуиция
Если мы нанесем эти точки на график, мы сможем найти некоторые кластеры или группы. Теперь, учитывая неклассифицированную точку, мы можем отнести ее к группе, наблюдая, к какой группе принадлежат ее ближайшие соседи. Это означает, что точка, близкая к группе точек, классифицированных как «Красные», с большей вероятностью будет классифицирована как «Красные».
Интуитивно мы видим, что первая точка (2.5, 7) должна быть отнесена к «зеленой», а вторая точка (5.5, 4.5) должна быть отнесена к «красной».
Алгоритм
Пусть m будет количеством обучающих выборок данных. Пусть p - неизвестная точка.
- Сохраните обучающие образцы в массиве точек данных arr []. Это означает, что каждый элемент этого массива представляет собой кортеж (x, y).
для i = от 0 до m: Вычислите евклидово расстояние d (arr [i], p).
- Составьте набор S из K наименьших полученных расстояний. Каждое из этих расстояний соответствует уже классифицированной точке данных.
- Вернуть метку большинства среди S.
Рекомендуется: сначала попробуйте свой подход в {IDE}, прежде чем переходить к решению.
K можно сохранить как нечетное число, чтобы мы могли вычислить явное большинство в случае, когда возможны только две группы (например, красная / синяя). С увеличением K мы получаем более плавные и четкие границы в разных классификациях. Кроме того, точность приведенного выше классификатора увеличивается по мере увеличения количества точек данных в обучающем наборе.
Пример программы
Предположим, что 0 и 1 являются двумя классификаторами (группами).
C / C ++
// C++ program to find groups of unknown// Points using K nearest neighbour algorithm.#include <bits/stdc++.h>using namespace std; struct Point{ int val; // Group of point double x, y; // Co-ordinate of point double distance; // Distance from test point}; // Used to sort an array of points by increasing// order of distancebool comparison(Point a, Point b){ return (a.distance < b.distance);} // This function finds classification of point p using// k nearest neighbour algorithm. It assumes only two// groups and returns 0 if p belongs to group 0, else// 1 (belongs to group 1).int classifyAPoint(Point arr[], int n, int k, Point p){ // Fill distances of all points from p for ( int i = 0; i < n; i++) arr[i].distance = sqrt ((arr[i].x - px) * (arr[i].x - px) + (arr[i].y - py) * (arr[i].y - py)); // Sort the Points by distance from p sort(arr, arr+n, comparison); // Now consider the first k elements and only // two groups int freq1 = 0; // Frequency of group 0 int freq2 = 0; // Frequency of group 1 for ( int i = 0; i < k; i++) { if (arr[i].val == 0) freq1++; else if (arr[i].val == 1) freq2++; } return (freq1 > freq2 ? 0 : 1);} // Driver codeint main(){ int n = 17; // Number of data points Point arr[n]; arr[0].x = 1; arr[0].y = 12; arr[0].val = 0; arr[1].x = 2; arr[1].y = 5; arr[1].val = 0; arr[2].x = 5; arr[2].y = 3; arr[2].val = 1; arr[3].x = 3; arr[3].y = 2; arr[3].val = 1; arr[4].x = 3; arr[4].y = 6; arr[4].val = 0; arr[5].x = 1.5; arr[5].y = 9; arr[5].val = 1; arr[6].x = 7; arr[6].y = 2; arr[6].val = 1; arr[7].x = 6; arr[7].y = 1; arr[7].val = 1; arr[8].x = 3.8; arr[8].y = 3; arr[8].val = 1; arr[9].x = 3; arr[9].y = 10; arr[9].val = 0; arr[10].x = 5.6; arr[10].y = 4; arr[10].val = 1; arr[11].x = 4; arr[11].y = 2; arr[11].val = 1; arr[12].x = 3.5; arr[12].y = 8; arr[12].val = 0; arr[13].x = 2; arr[13].y = 11; arr[13].val = 0; arr[14].x = 2; arr[14].y = 5; arr[14].val = 1; arr[15].x = 2; arr[15].y = 9; arr[15].val = 0; arr[16].x = 1; arr[16].y = 7; arr[16].val = 0; /*Testing Point*/ Point p; px = 2.5; py = 7; // Parameter to decide group of the testing point int k = 3; printf ( "The value classified to unknown point" " is %d.
" , classifyAPoint(arr, n, k, p)); return 0;} |
Python
# Python3 program to find groups of unknown# Points using K nearest neighbour algorithm. import math def classifyAPoint(points,p,k = 3 ): ''' This function finds the classification of p using k nearest neighbor algorithm. It assumes only two groups and returns 0 if p belongs to group 0, else 1 (belongs to group 1). Parameters - points: Dictionary of training points having two keys - 0 and 1 Each key have a list of training data points belong to that p : A tuple, test data point of the form (x,y) k : number of nearest neighbour to consider, default is 3 ''' distance = [] for group in points: for feature in points[group]: #calculate the euclidean distance of p from training points euclidean_distance = math.sqrt((feature[ 0 ] - p[ 0 ]) * * 2 + (feature[ 1 ] - p[ 1 ]) * * 2 ) # Add a tuple of form (distance,group) in the distance list distance.append((euclidean_distance,group)) # sort the distance list in ascending order # and select first k distances distance = sorted (distance)[:k] freq1 = 0 #frequency of group 0 freq2 = 0 #frequency og group 1 for d in distance: if d[ 1 ] = = 0 : freq1 + = 1 elif d[ 1 ] = = 1 : freq2 + = 1 return 0 if freq1>freq2 else 1 # driver functiondef main(): # Dictionary of training points having two keys - 0 and 1 # key 0 have points belong to class 0 # key 1 have points belong to class 1 points = { 0 :[( 1 , 12 ),( 2 , 5 ),( 3 , 6 ),( 3 , 10 ),( 3.5 , 8 ),( 2 , 11 ),( 2 , 9 ),( 1 , 7 )], 1 :[( 5 , 3 ),( 3 , 2 ),( 1.5 , 9 ),( 7 , 2 ),( 6 , 1 ),( 3.8 , 1 ),( 5.6 , 4 ),( 4 , 2 ),( 2 , 5 )]} # testing point p(x,y) p = ( 2.5 , 7 ) # Number of neighbours k = 3 print ( "The value classified to unknown point is: {}" . format (classifyAPoint(points,p,k))) if __name__ = = '__main__' : main() # This code is contributed by Atul Kumar (www.fb.com/atul.kr.007) |
Выход:
Значение, отнесенное к неизвестной точке, равно 0.
Эта статья предоставлена Ананней Уберой . Если вам нравится GeeksforGeeks, и вы хотели бы внести свой вклад, вы также можете написать статью с помощью provide.geeksforgeeks.org или отправить ее по электронной почте на deposit@geeksforgeeks.org. Посмотрите, как ваша статья появляется на главной странице GeeksforGeeks, и помогите другим гикам.
Пожалуйста, напишите комментарии, если вы обнаружите что-то неправильное, или вы хотите поделиться дополнительной информацией по теме, обсужденной выше.
Вниманию читателя! Не прекращайте учиться сейчас. Освойте все важные концепции DSA с помощью самостоятельного курса DSA по приемлемой для студентов цене и будьте готовы к работе в отрасли. Чтобы завершить подготовку от изучения языка к DS Algo и многому другому, см. Полный курс подготовки к собеседованию .
Если вы хотите посещать живые занятия с отраслевыми экспертами, пожалуйста, обращайтесь к Geeks Classes Live и Geeks Classes Live USA.