Изучение распределения данных | Комплект 1
Когда мы работаем в области науки о данных и машинного обучения, наш подход к обработке данных и поиску чего-то полезного основан на их распределении.
Распределение означает, что данные могут быть представлены различными возможными способами, процент конкретных данных, идентифицирующий выбросы. Итак, распределение данных - это способ использования графических методов для организации и отображения полезной информации.
Термины, связанные с исследованием распространения данных
-> Коробчатая диаграмма -> Таблица частот -> Гистограмма -> График плотности
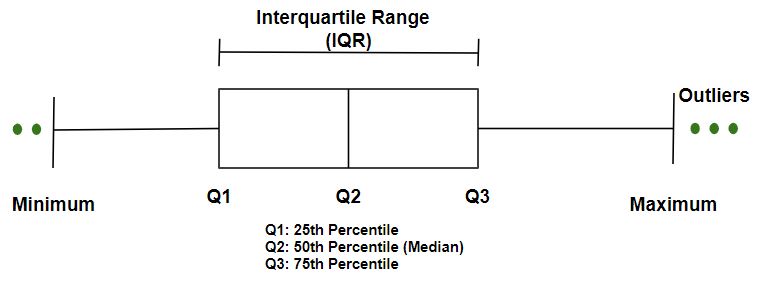
- Коробчатая диаграмма: основана на процентилях данных, как показано на рисунке ниже. Верх и низ прямоугольной диаграммы - это 75- й и 25- й процентили данных. Расширенные линии известны как усы, которые включают диапазон остальных данных.
Чтобы получить ссылку на используемый файл
csv, щелкните здесь.Код # 1: загрузка библиотек
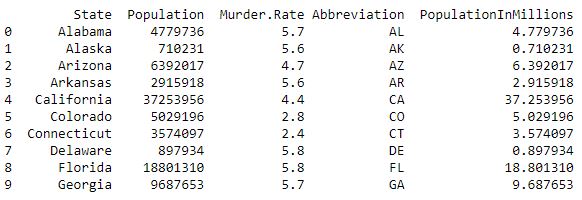
importnumpy as npimportpandas as pdimportseaborn as snsimportmatplotlib.pyplot as pltКод # 2: загрузка данных
data=pd.read_csv("../data/state.csv")# Adding a new column with derived datadata['PopulationInMillions']=data['Population']/1000000print(data.head(10))Выход :
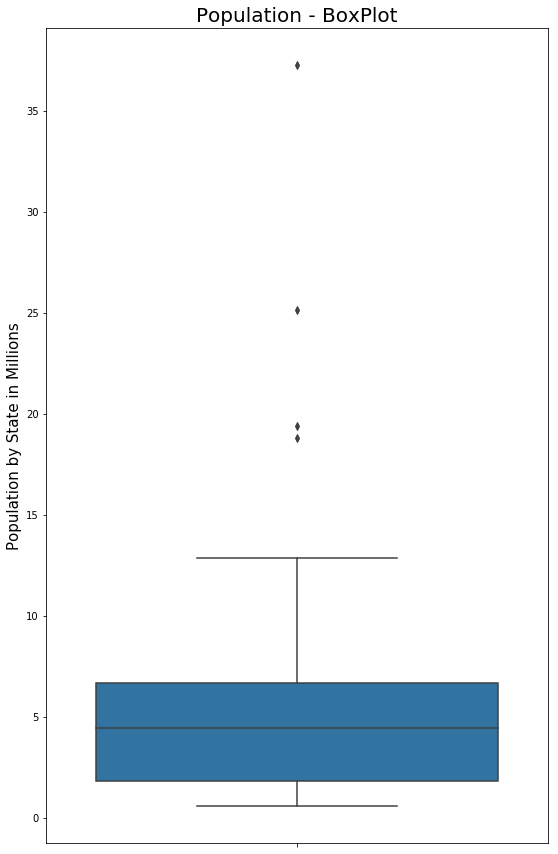
Код # 3: BoxPlot
# BoxPlot Population In Millionsfig, ax1=plt.subplots()fig.set_size_inches(9,15)ax1=sns.boxplot(x=data.PopulationInMillions, orient="v")ax1.set_ylabel("Population by State in Millions", fontsize=15)ax1.set_title("Population - BoxPlot", fontsize=20)Выход :
- Таблица частот: это инструмент для распределения данных в равномерно распределенные диапазоны, сегменты и сообщает нам, сколько значений попадает в каждый сегмент.
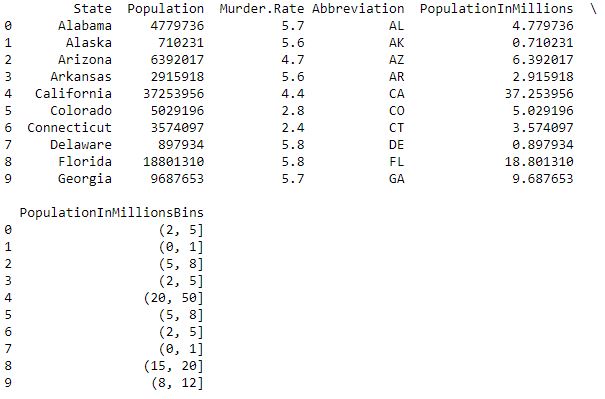
Код №1: добавление столбца для выполнения функций кросс-таблицы и группировки.
# Perform the binning action, the bins have been# chosen to accentuate the output for the Frequency Tabledata['PopulationInMillionsBins']=pd.cut(data.PopulationInMillions, bins=[0,1,2,5,8,12,15,20,50])print(data.head(10))Выход :
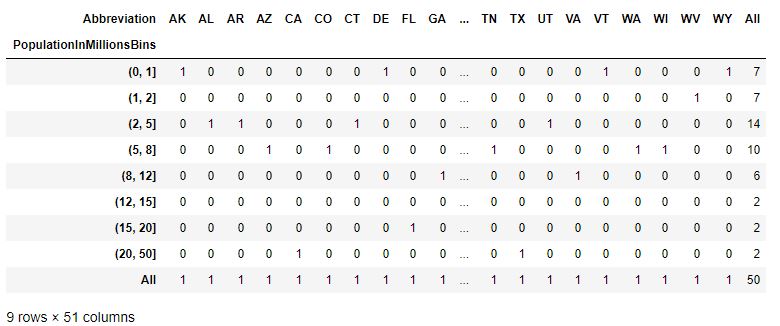
Код # 2: Кросс-таблица - тип таблицы частот
# Cross Tab - a type of Frequency Tablepd.crosstab(data.PopulationInMillionsBins, data.Abbreviation, margins=True)Выход :
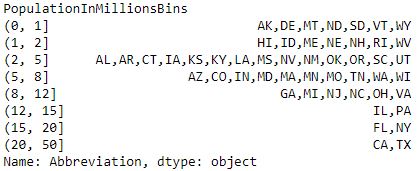
Код # 3: GroupBy - тип таблицы частот
# Groupby - a type of Frequency Tabledata.groupby(data.PopulationInMillionsBins)['Abbreviation'].apply(', '.join)Выход :
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.