Исследовательский анализ данных в Python | Комплект 1
Исследовательский анализ данных - это метод анализа данных с помощью визуальных методов и всех статистических результатов. Мы узнаем, как применять эти методы, прежде чем применять какие-либо модели машинного обучения.
Чтобы получить ссылку на csv , щелкните здесь.
Загрузка библиотек:
import numpy as npimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as plt from scipy.stats import trim_mean |
Загрузка данных:
data = pd.read_csv( "state.csv" ) # Check the type of dataprint ( "Type : " , type (data), "
" ) # Printing Top 10 Recordsprint ( "Head --
" , data.head( 10 )) # Printing last 10 Recordsprint ( "
Tail --
" , data.tail( 10 )) |
Выход :
Тип: класс 'pandas.core.frame.DataFrame'
Глава --
Государственное убийство населения. Сокращенное наименование.
0 Алабама 4779736 5,7 AL
1 Аляска 710231 5,6 АК
2 Аризона 639 2017 4,7 AZ
3 Арканзас 2915918 5,6 AR
4 Калифорния 37253956 4,4 CA
5 Колорадо 5029196 2,8 CO
6 Коннектикут 3574097 2,4 CT
7 Делавэр 897934 5,8 DE
8 Флорида 18801310 5,8 FL
9 Грузия 9687653 5,7 GA
Хвост --
Государственное убийство населения. Сокращенное наименование.
40 Южная Дакота 814180 2.3 SD
41 Теннесси 6346105 5,7 TN
42 Техас 25145561 4,4 Техаса
43 Юта 2763885 2.3 UT
44 Вермонт 625741 1,6 VT
45 Вирджиния 8001024 4,1 ВА
46 Вашингтон 6724540 2,5 Вт
47 Западная Вирджиния 1852994 4,0 Западная Вирджиния
48 Висконсин 5686986 2,9 Висконсин
49 Вайоминг 563626 2,7 WY
Код # 1: добавление столбца в фрейм данных
# Adding a new column with derived data data[ 'PopulationInMillions' ] = data[ 'Population' ] / 1000000 # Changed dataprint (data.head( 5 )) |
Выход :
Убийство населения штата. Аббревиатура Население в миллионах
0 Алабама 4779736 5,7 AL 4.779736
1 Аляска 710231 5,6 АК 0,710231
2 Аризона 639 2017 4,7 АЗ 6,39 2017
3 Арканзас 2915918 5,6 AR 2.915918
4 Калифорния 37253956 4,4 Калифорния 37.253956
Код # 2: Описание данных
data.describe() |
Выход :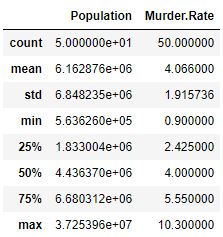
Код # 3: Информация о данных
data.info() |
Выход :
RangeIndex: 50 записей, от 0 до 49 Столбцы данных (всего 4 столбца): Состояние 50 ненулевого объекта Население 50, отличное от null, int64 Murder.Rate 50 ненулевое значение float64 Аббревиатура 50 ненулевой объект dtypes: float64 (1), int64 (1), объект (2) использование памяти: 1,6+ КБ
Код # 4: переименование заголовка столбца
# Rename column heading as it# has '.' in it which will create# problems when dealing functions data.rename(columns = { 'Murder.Rate' : 'MurderRate' }, inplace = True ) # Lets check the column headingslist (data) |
Выход :
["Штат", "Население", "Уровень убийств", "Аббревиатура"]
Код # 5: Расчет среднего
Population_mean = data.Population.mean()print ( "Population Mean : " , Population_mean) MurderRate_mean = data.MurderRate.mean()print ( "
MurderRate Mean : " , MurderRate_mean) |
Выход:
Среднее население: 6162876,3 Среднее количество убийств: 4,066
Код # 6: усеченное среднее
# Mean after discarding top and# bottom 10 % values eliminating outliers population_TM = trim_mean(data.Population, 0.1 )print ( "Population trimmed mean: " , population_TM) murder_TM = trim_mean(data.MurderRate, 0.1 )print ( "
MurderRate trimmed mean: " , murder_TM) |
Выход :
Среднее значение усеченного населения: 4783697,125 Среднее усеченное значение MurderRate: 3.9450000000000003
Код # 7: средневзвешенное значение
# here murder rate is weighed as per# the state population murderRate_WM = np.average(data.MurderRate, weights = data.Population)print ( "Weighted MurderRate Mean: " , murderRate_WM) |
Выход :
Взвешенное значение показателя убийств: 4,445833981123393
Код # 8: Медиана
Population_median = data.Population.median()print ( "Population median : " , Population_median) MurderRate_median = data.MurderRate.median()print ( "
MurderRate median : " , MurderRate_median) |
Выход :
Медиана численности населения: 4436369,5 Среднее значение MurderRate: 4,0
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.