Иерархическая кластеризация в программировании на R
Иерархическая кластеризация - это неконтролируемый нелинейный алгоритм, в котором кластеры создаются таким образом, что они имеют иерархию (или заранее определенный порядок). Например, рассмотрим семью до трех поколений. У дедушки и матери есть дети, которые становятся отцом и матерью своих детей. Таким образом, все они сгруппированы в одно семейство, т.е. образуют иерархию.
Иерархическая кластеризация бывает двух типов:
- Разделяющая иерархическая кластеризация: она начинается с отдельных листьев и успешно объединяет кластеры. Это подход снизу вверх.
- Агломеративная иерархическая кластеризация: она начинается с корня и рекурсивно разделяет кластеры. Это подход сверху вниз.
Теория
В иерархической кластеризации объекты подразделяются на иерархию, аналогичную древовидной структуре, которая используется для интерпретации моделей иерархической кластеризации. Алгоритм следующий:
- Сделайте каждую точку данных в единственном кластере точки, который образует N кластеров.
- Возьмите две ближайшие точки данных и объедините их в один кластер, который образует N-1 кластеров.
- Возьмите два ближайших кластера и сделайте их одним кластером, который образует N-2 кластера.
- Повторяйте шаги 3, пока не останется только один кластер.
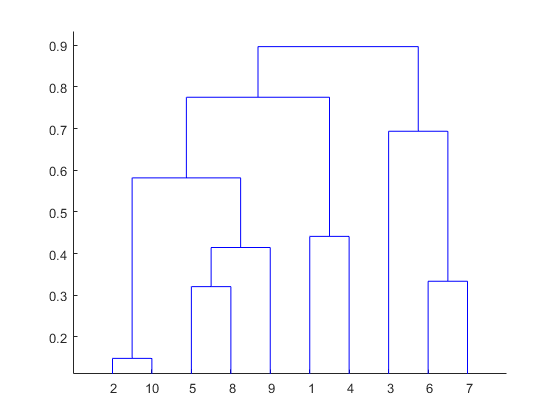
Дендрограмма - это иерархия кластеров, в которой расстояния конвертируются в высоту. Он объединяет n единиц или объектов, каждый с p характеристикой, в более мелкие группы. Объекты в одном кластере соединяются горизонтальной линией. Листья внизу представляют отдельные единицы. Он обеспечивает визуальное представление кластеров.
Правило большого пальца: максимальное расстояние по вертикали, которое не пересекает горизонтальную линию, определяет оптимальное количество кластеров.
Набор данных
mtcars ) включает в себя расход топлива, характеристики и 10 аспектов автомобильной конструкции для 32 автомобилей. Он поставляется с предустановленным пакетом dplyr в R.
# Installing the packageinstall.packages( "dplyr" ) # Loading packagelibrary(dplyr) # Summary of dataset in packagehead(mtcars) |

Выполнение иерархической кластеризации набора данных
Использование алгоритма иерархической кластеризации для набора данных с использованием hclust() который предварительно установлен в пакете статистики при установке R.
# Finding distance matrixdistance_mat < - dist(mtcars, method = 'euclidean' )distance_mat # Fitting Hierarchical clustering Model# to training datasetset .seed( 240 ) # Setting seedHierar_cl < - hclust(distance_mat, method = "average" )Hierar_cl # Plotting dendrogramplot(Hierar_cl) # Choosing no. of clusters# Cutting tree by heightabline(h = 110 , col = "green" ) # Cutting tree by no. of clustersfit < - cutree(Hierar_cl, k = 3 )fit table(fit)rect.hclust(Hierar_cl, k = 3 , border = "green" ) |
Выход:
- Матрица расстояний:
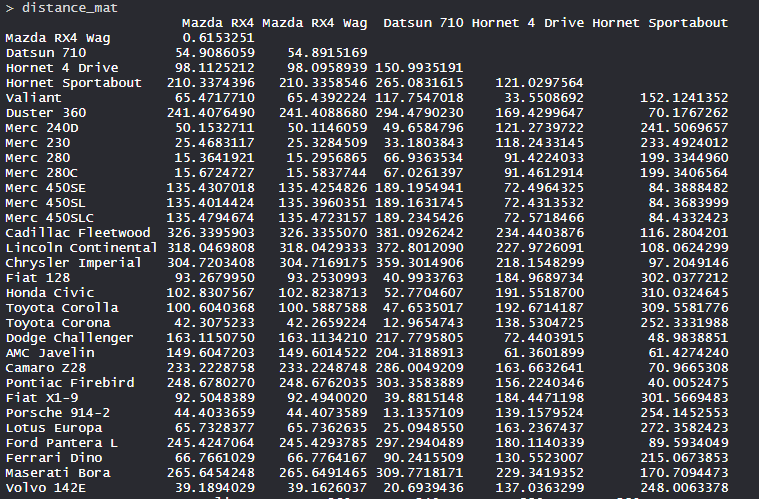
Значения показаны в соответствии с расчетом матрицы расстояний с использованием метода как евклидова.
- Модель Hierar_cl:
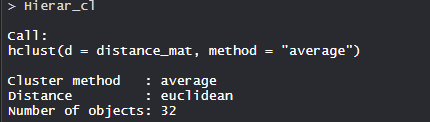
В модели кластерный метод средний, расстояние евклидово и нет. Всего объектов 32.
- Постройте дендрограмму:

Дендрограмма графика показана с осью X в качестве матрицы расстояний и осью Y в качестве высоты.
- Срезанное дерево:
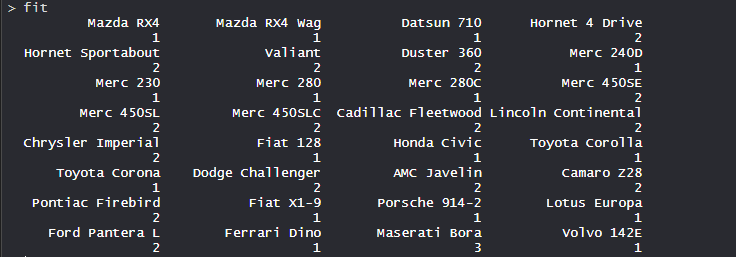
Итак, дерево вырезано там, где k = 3, и каждая категория представляет свое количество кластеров.
- Построение дендрограммы после вырезания:

График обозначает дендрограмму после разреза. Зеленые линии показывают количество кластеров согласно правилу большого пальца.
Итак, иерархическая кластеризация широко используется в отрасли.