IBM HR Analytics об убытке и производительности сотрудников с использованием классификатора случайного леса
Убыль - это проблема, которая затрагивает все предприятия, независимо от географии, отрасли и размера компании. Это серьезная проблема для организации, и прогнозирование текучести кадров находится в авангарде потребностей отдела кадров (HR) во многих организациях. Организации несут огромные расходы, связанные с текучестью кадров. Благодаря достижениям в области машинного обучения и науки о данных можно прогнозировать увольнение сотрудников, и мы будем прогнозировать, используя алгоритм случайного лесного классификатора.
Набор данных: набор данных, который публикуется отделом кадров IBM, доступен на Kaggle.
Код: реализация алгоритма классификатора случайного леса для классификации.
Код: загрузка библиотек
Python3
# performing linear algebraimport numpy as np # data processingimport pandas as pd # visualisationimport matplotlib.pyplot as pltimport seaborn as sns % matplotlib inline |
Код: Импорт набора данных
Python3
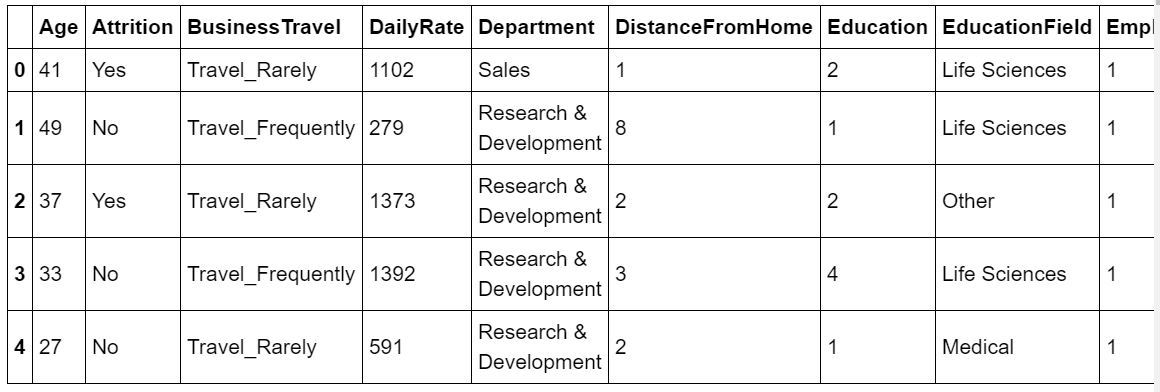
dataset = pd.read_csv( "WA_Fn-UseC_-HR-Employee-Attrition.csv" )print (dataset.head) |
Выход :
Код: информация о наборе данных
Python3
dataset.info() |
Выход :
RangeIndex: 1470 записей, от 0 до 1469 Столбцы данных (всего 35 столбцов): Возраст 1470 ненулевой int64 Истощение 1470 ненулевой объект BusinessTravel 1470 ненулевой объект DailyRate 1470 ненулевое значение int64 Ненулевой объект отдела 1470 DistanceFromHome 1470 ненулевое значение int64 Образование 1470 непустое int64 EducationField 1470 ненулевой объект EmployeeCount 1470 ненулевое значение int64 EmployeeNumber 1470 ненулевое значение int64 EnvironmentSatisfaction 1470 ненулевое значение int64 Пол 1470 ненулевой объект HourlyRate 1470 ненулевое значение int64 JobInvolvement 1470 ненулевое значение int64 JobLevel 1470 ненулевое значение int64 JobRole 1470 ненулевой объект JobSatisfaction 1470 ненулевое значение int64 MaritalStatus 1470 ненулевой объект Ежемесячный доход 1470 ненулевое значение int64 MonthlyRate 1470 ненулевое значение int64 NumCompaniesWorked 1470 ненулевых int64 Более 18 1470 ненулевых объектов OverTime 1470 ненулевой объект PercentSalaryHike 1470 ненулевое значение int64 PerformanceRating 1470 ненулевое значение int64 RelationshipSatisfaction 1470 ненулевое значение int64 StandardHours 1470 ненулевое значение int64 StockOptionLevel 1470 ненулевое значение int64 TotalWorkingYears 1470 ненулевое int64 TrainingTimesLastYear 1470 ненулевое значение int64 WorkLifeBalance 1470 ненулевое значение int64 YearsAtCompany 1470 ненулевое значение int64 YearsInCurrentRole 1470 ненулевое значение int64 YearsSinceLastPromotion 1470 ненулевое значение int64 YearsWithCurrManager 1470 ненулевое значение int64 dtypes: int64 (26), объект (9) использование памяти: 402,0+ КБ
Код: визуализация данных
Python3
# heatmap to check the missing valueplt.figure(figsize =(10, 4))sns.heatmap(dataset.isnull(), yticklabels = False, cbar = False, cmap ="viridis") |
Выход:
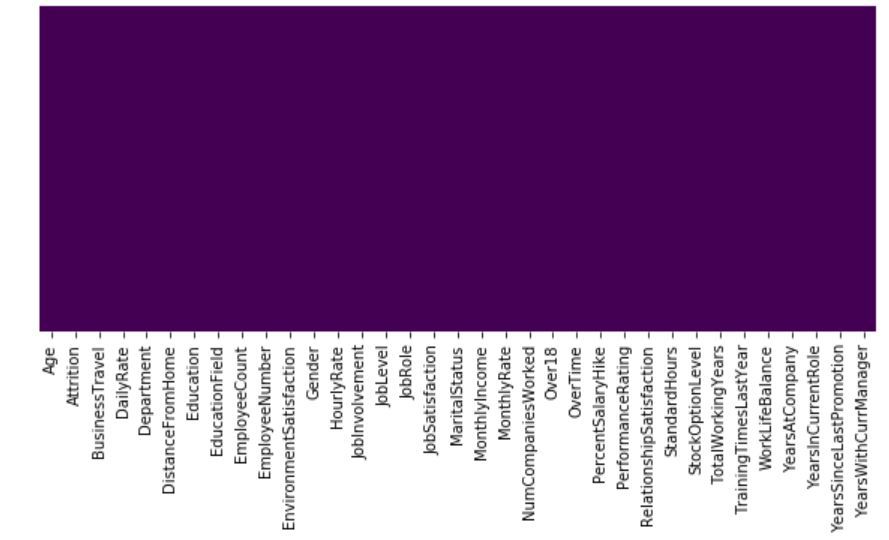
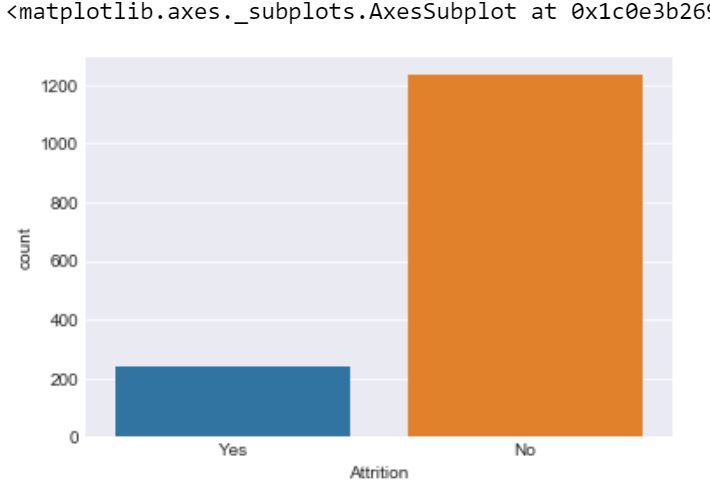
Итак, мы видим, что в наборе данных нет пропущенных значений. Это проблема двоичной классификации, поэтому распределение экземпляров между двумя классами показано ниже:
Код:
Python3
sns.set_style( 'darkgrid' )sns.countplot(x = 'Attrition' , data = dataset) |
Выход:
Код:
Python3
sns.lmplot(x = 'Age' , y = 'DailyRate' , hue = 'Attrition' , data = dataset) |
Выход:
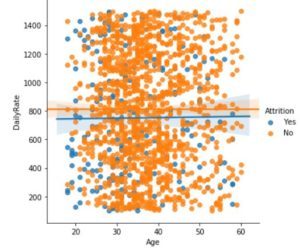
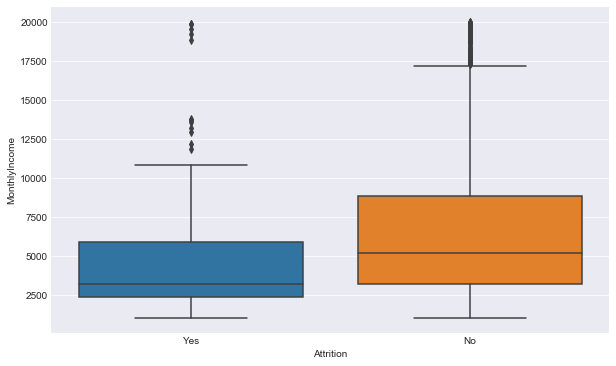
Код:
Python3
plt.figure(figsize = ( 10 , 6 ))sns.boxplot(y = 'MonthlyIncome' , x = 'Attrition' , data = dataset) |
Выход:
Код: предварительная обработка данных
В наборе данных есть 4 нерелевантных столбца, то есть: EmployeeCount, EmployeeNumber, Over18 и StandardHour. Итак, мы должны удалить их для большей точности.
Python3
dataset.drop( 'EmployeeCount' , axis = 1 , inplace = True )dataset.drop( 'StandardHours' , axis = 1 , inplace = True )dataset.drop( 'EmployeeNumber' , axis = 1 , inplace = True )dataset.drop( 'Over18' , axis = 1 , inplace = True ) print (dataset.shape) |
Выход:
(1470, 31)
Итак, мы удалили ненужный столбец.
Код: входные и выходные данные
Python3
y = dataset.iloc[:, 1 ]X = dataset X.drop( 'Attrition' , axis = 1 , inplace = True ) |
Код: кодирование метки
Python3
from sklearn.preprocessing import LabelEncoderlb = LabelEncoder()y = lb.fit_transform(y) |
В наборе данных есть 7 категориальных данных, поэтому мы должны изменить их на данные типа int, т.е. мы должны создать 7 фиктивных переменных для большей точности.
Код: создание фиктивной переменной
Python3
dum_BusinessTravel = pd.get_dummies(dataset[ 'BusinessTravel' ], prefix = 'BusinessTravel' ) dum_Department = pd.get_dummies(dataset[ 'Department' ], prefix = 'Department' ) dum_EducationField = pd.get_dummies(dataset[ 'EducationField' ], prefix = 'EducationField' ) dum_Gender = pd.get_dummies(dataset[ 'Gender' ], prefix = 'Gender' , drop_first = True ) dum_JobRole = pd.get_dummies(dataset[ 'JobRole' ], prefix = 'JobRole' ) dum_MaritalStatus = pd.get_dummies(dataset[ 'MaritalStatus' ], prefix = 'MaritalStatus' ) dum_OverTime = pd.get_dummies(dataset[ 'OverTime' ], prefix = 'OverTime' , drop_first = True ) # Adding these dummy variable to input XX = pd.concat([x, dum_BusinessTravel, dum_Department, dum_EducationField, dum_Gender, dum_JobRole, dum_MaritalStatus, dum_OverTime], axis = 1 ) # Removing the categorical dataX.drop([ 'BusinessTravel' , 'Department' , 'EducationField' , 'Gender' , 'JobRole' , 'MaritalStatus' , 'OverTime' ], axis = 1 , inplace = True ) print (X.shape)print (y.shape) |
Выход:
(1470, 49) (1470,)
Код: разделение данных на обучение и тестирование
Python3
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.25 , random_state = 40 ) |
Итак, предварительная обработка завершена, теперь нам нужно применить классификатор случайного леса к набору данных.
Код: исполнение модели
Python3
from sklearn.model_selection import cross_val_predict, cross_val_scorefrom sklearn.metrics import accuracy_score, classification_report, confusion_matrixfrom sklearn.ensemble import RandomForestClassifier rf = RandomForestClassifier(n_estimators = 10 , criterion = 'entropy' )rf.fit(X_train, y_train)y_pred = rf.predict(X_test) def print_score(clf, X_train, y_train, X_test, y_test, train = True ): if train: print ( "Train Result:" ) print ( "------------" ) print ( "Classification Report:
{}
" . format (classification_report( y_train, clf.predict(X_train)))) print ( "Confusion Matrix:
{}
" . format (confusion_matrix( y_train, clf.predict(X_train)))) res = cross_val_score(clf, X_train, y_train, cv = 10 , scoring = 'accuracy' ) print ( "Average Accuracy: {0:.4f}" . format (np.mean(res))) print ( "Accuracy SD: {0:.4f}" . format (np.std(res))) print ( "----------------------------------------------------------" ) elif train = = False : print ( "Test Result:" ) print ( "-----------" ) print ( "Classification Report:
{}
" . format ( classification_report(y_test, clf.predict(X_test)))) print ( "Confusion Matrix:
{}
" . format ( confusion_matrix(y_test, clf.predict(X_test)))) print ( "accuracy score: {0:.4f}
" . format ( accuracy_score(y_test, clf.predict(X_test)))) print ( "-----------------------------------------------------------" ) print_score(rf, X_train, y_train, X_test, y_test, train = True ) print_score(rf, X_train, y_train, X_test, y_test, train = False ) |
Выход:
Результат поезда:
------------
Классификационный отчет:
точный отзыв поддержка f1-score
0 0,98 1,00 0,99 988
1 1,00 0,90 0,95 188
точность 0,98 1176
макрос ср. 0,99 0,95 0,97 1176
средневзвешенная 0,98 0,98 0,98 1176
Матрица неточностей:
[[988 0]
[19 169]]
Средняя точность: 0,8520
Стандартное отклонение точности: 0,0122
-------------------------------------------------- --------
Результат испытаний:
-----------
Классификационный отчет:
точный отзыв поддержка f1-score
0 0,86 0,98 0,92 245
1 0,71 0,20 0,32 49
точность 0,85 294
макрос среднем 0,79 0,59 0,62 294
средневзвешенная 0,84 0,85 0,82 294
Матрица неточностей:
[[241 4]
[39 10]]
оценка точности: 0,8537
-------------------------------------------------- ---------
Код: Ключевые особенности для определения результата
Python3
pd.Series(rf.feature_importances_, index = X.columns).sort_values(ascending = False ).plot(kind = 'bar' , figsize = ( 14 , 6 )); |
Выход:
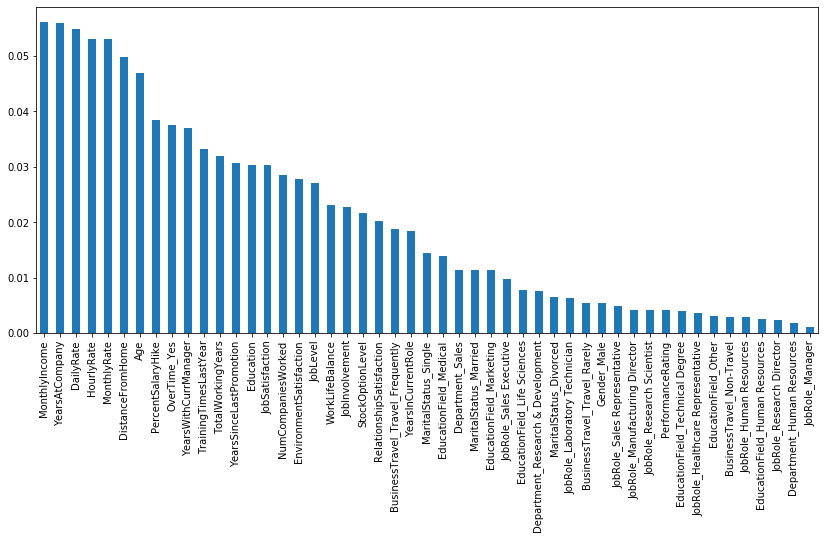
Итак, согласно классификатору случайного леса наиболее важной функцией для прогнозирования результата является ежемесячный доход, а наименее важной функцией является jobRole_Manager .