Hadoop - Введение
В этом мире изменилось определение сильного человека. Сильный - это тот, у кого есть доступ к данным. Это потому, что объем данных увеличивается с огромной скоростью. Предположим, мы живем в мире 100% данных. Тогда 90% данных производятся за последние 2–4 года. Это потому, что теперь, когда рождается ребенок, раньше матери, она впервые сталкивается со вспышкой фотоаппарата. Все эти фотографии и видео - не что иное, как данные. Точно так же есть данные электронной почты, различных приложений для смартфонов, статистические данные и т. Д. Все эти данные обладают огромной силой влиять на различные инциденты и тенденции. Эти данные используются не только компаниями для воздействия на своих потребителей, но и политиками для воздействия на выборы. Эти огромные данные называются большими данными . В таком мире, где данные производятся с такой экспоненциальной скоростью, их необходимо поддерживать, анализировать и обрабатывать. Вот тут-то и появляется Hadoop.
Hadoop - это набор инструментов с открытым исходным кодом, распространяемый по лицензии Apache. Он используется для управления данными, хранения данных и обработки данных для различных приложений больших данных, работающих в кластерных системах. В предыдущие годы большие данные определялись как « 3V », но теперь есть « 5V » больших данных, которые также называются характеристиками больших данных.
- Объем: с ростом зависимости от технологий данные производятся в больших объемах. Типичными примерами являются данные, производимые различными сайтами социальных сетей, датчиками, сканерами, авиакомпаниями и другими организациями.
- Скорость: огромное количество данных генерируется в секунду. Предполагается, что к концу 2020 года каждый человек будет производить 3 МБ данных в секунду. Этот большой объем данных генерируется с большой скоростью.
- Разнообразие: данные, получаемые разными способами, бывают трех типов:
- Структурированные данные: это реляционные данные, которые хранятся в виде строк и столбцов.
- Неструктурированные данные: тексты, изображения, видео и т. Д. Являются примерами неструктурированных данных, которые нельзя хранить в виде строк и столбцов.
- Полуструктурированные данные: файлы журналов являются примерами данных этого типа.
- Достоверность: термин «достоверность» используется для обозначения противоречивых или неполных данных, которые приводят к созданию сомнительной или недостоверной информации. Часто несогласованность данных возникает из-за объема или количества данных, например, объемные данные могут создать путаницу, тогда как меньший объем данных может передать половину или неполную информацию.
- Ценность: после учета 4 В следует еще одна В, которая означает Ценность !. Большой объем данных, не имеющих ценности, бесполезен для компании, если вы не превратите их во что-то полезное. Данные сами по себе бесполезны или важны, но их нужно преобразовать во что-то ценное для извлечения информации. Следовательно, вы можете заявить, что Value! это самый важный V из всех 5V
Теперь, чтобы справиться с этими 5 V, используется инструмент под названием Hadoop .
Эволюция Hadoop: Hadoop был разработан Дугом Каттингом и Майклом Кафареллой в 2005 году. Дизайн Hadoop вдохновлен Google. Hadoop хранит огромное количество данных через систему под названием Hadoop Distributed File System (HDFS) и обрабатывает эти данные с помощью технологии Map Reduce. Дизайн HDFS и Map Reduce вдохновлен файловой системой Google (GFS) и Map Reduce. В 2000 году Google внезапно обогнал все существующие поисковые системы и стал самой популярной и прибыльной поисковой системой. Успех Google был приписан его уникальной файловой системе Google и Map Reduce. До того времени об этом не знал никто, кроме Google. Итак, в 2003 году Google опубликовал несколько статей о GFS. Но этого было недостаточно, чтобы понять, как работает Google в целом. Итак, в 2004 году Google снова опубликовал оставшиеся документы. Двое энтузиастов, Дуг Каттинг и Майкл Кафарелла, изучили эти документы и в 2005 году разработали то, что называется Hadoop. У сына Дуга был игрушечный слоник по имени Hadoop, и поэтому Дуг и Майкл дали своему новому творению имя «Hadoop» и, следовательно, символ «игрушечный слоник». Так эволюционировал Hadoop. Таким образом, проекты HDFS и Map Reduced, хотя и были созданы Дугом Каттингом и Майклом Кафареллой, но изначально вдохновлены Google. Для получения дополнительной информации об эволюции Hadoop вы можете обратиться к Hadoop | История или эволюция .
Традиционный подход: предположим, мы хотим обработать данные. В традиционном подходе мы использовали для хранения данных на локальных машинах. Затем эти данные были обработаны. Теперь, когда объем данных начал увеличиваться, локальные машины или компьютеры были недостаточно способны хранить этот огромный набор данных. Итак, данные начали храниться на удаленных серверах. Теперь предположим, что нам нужно обработать эти данные. Таким образом, при традиционном подходе эти данные должны быть получены с серверов и затем обработаны. Предположим, это данные 500 ГБ. На практике получить эти данные очень сложно и дорого. Этот подход также называется корпоративным подходом.
В новом подходе Hadoop вместо получения данных на локальных машинах мы отправляем запрос к данным. Очевидно, что запрос на обработку данных не будет таким огромным, как сами данные. Причем на сервере запрос разбит на несколько частей. Все эти части обрабатывают данные одновременно. Это называется параллельным выполнением и возможно благодаря Map Reduce. Таким образом, теперь не только нет необходимости извлекать данные, но и обработка занимает меньше времени. Затем результат запроса отправляется пользователю. Таким образом, Hadoop упрощает хранение, обработку и анализ данных по сравнению с традиционным подходом.
Компоненты Hadoop: Hadoop состоит из трех компонентов:
- HDFS: Распределенная файловая система Hadoop - это специальная файловая система для хранения больших данных с помощью кластера стандартного оборудования или более дешевого оборудования с потоковой схемой доступа. Это позволяет хранить данные на нескольких узлах кластера, что обеспечивает безопасность данных и отказоустойчивость.
- Уменьшение карты: данные, однажды сохраненные в HDFS, также должны обрабатываться. Теперь предположим, что отправлен запрос для обработки набора данных в HDFS. Теперь Hadoop определяет, где хранятся эти данные, это называется сопоставлением. Теперь запрос разбит на несколько частей, и результаты всех этих нескольких частей объединены, и общий результат отправляется обратно пользователю. Это называется процессом сокращения. Таким образом, в то время как HDFS используется для хранения данных, Map Reduce используется для обработки данных.
- ПРЯЖА: ПРЯЖА расшифровывается как еще один переговорщик ресурсов . Это специальная операционная система для Hadoop, которая управляет ресурсами кластера, а также функционирует как основа для планирования заданий в Hadoop. Существуют различные типы планирования: «Первый пришел - первый обслуга», «Планировщик справедливого распределения» и «Планировщик емкости» и т. Д. Планирование «первым пришел - первым обслужи» установлено в YARN по умолчанию.
Как компоненты Hadoop могут стать решением для больших данных?
- Распределенная файловая система Hadoop: на нашем локальном ПК размер блока на жестком диске по умолчанию составляет 4 КБ . Когда мы устанавливаем Hadoop, HDFS по умолчанию изменяет размер блока на 64 МБ . Поскольку он используется для хранения огромных данных. Мы также можем изменить размер блока на 128 МБ . Теперь HDFS работает с узлом данных и узлом имени. В то время как Name Node является главной службой и хранит метаданные о том, на каком серийном оборудовании находятся данные, Data Node хранит фактические данные. Теперь, поскольку размер блока составляет 64 МБ, объем хранилища, необходимый для хранения метаданных, уменьшается, что делает HDFS лучше. Кроме того, Hadoop хранит по три копии каждого набора данных в трех разных местах. Это гарантирует, что Hadoop не будет подвержен единой точке отказа.
- Map Reduce: проще всего понять, что MapReduce разбивает запрос на несколько частей, и теперь каждая часть обрабатывает данные согласованно. Такое параллельное выполнение помогает выполнять запросы быстрее и делает Hadoop подходящим и оптимальным выбором для работы с большими данными.
- YARN: Как мы знаем,
Yet Another Resource Negotiatorработает как операционная система для Hadoop, а поскольку операционные системы являются менеджерами ресурсов, YARN управляет ресурсами Hadoop, чтобы Hadoop лучше обслуживал большие данные.
Версии Hadoop. На сегодняшний день существует три следующих версии Hadoop.
- Hadoop 1. Это первая и самая базовая версия Hadoop. Он включает в себя Hadoop Common, распределенную файловую систему Hadoop (HDFS) и Map Reduce.
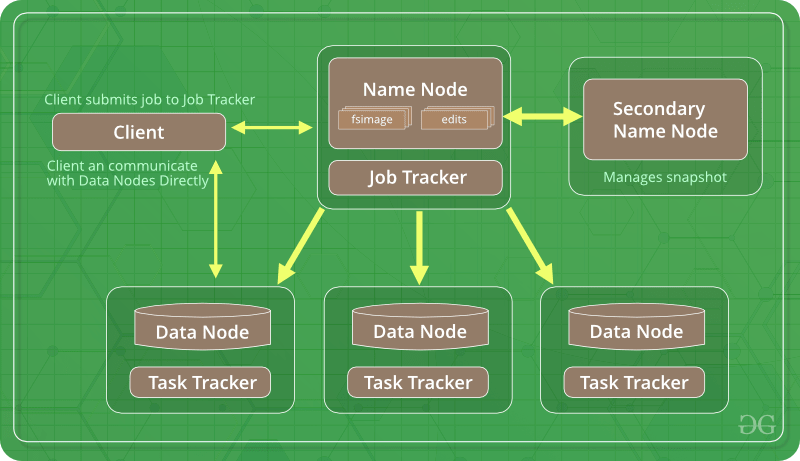
- Hadoop 2: единственное различие между Hadoop 1 и Hadoop 2 заключается в том, что Hadoop 2 дополнительно содержит YARN (еще один согласователь ресурсов). YARN помогает в управлении ресурсами и планировании задач с помощью двух своих демонов, а именно отслеживания заданий и мониторинга прогресса.
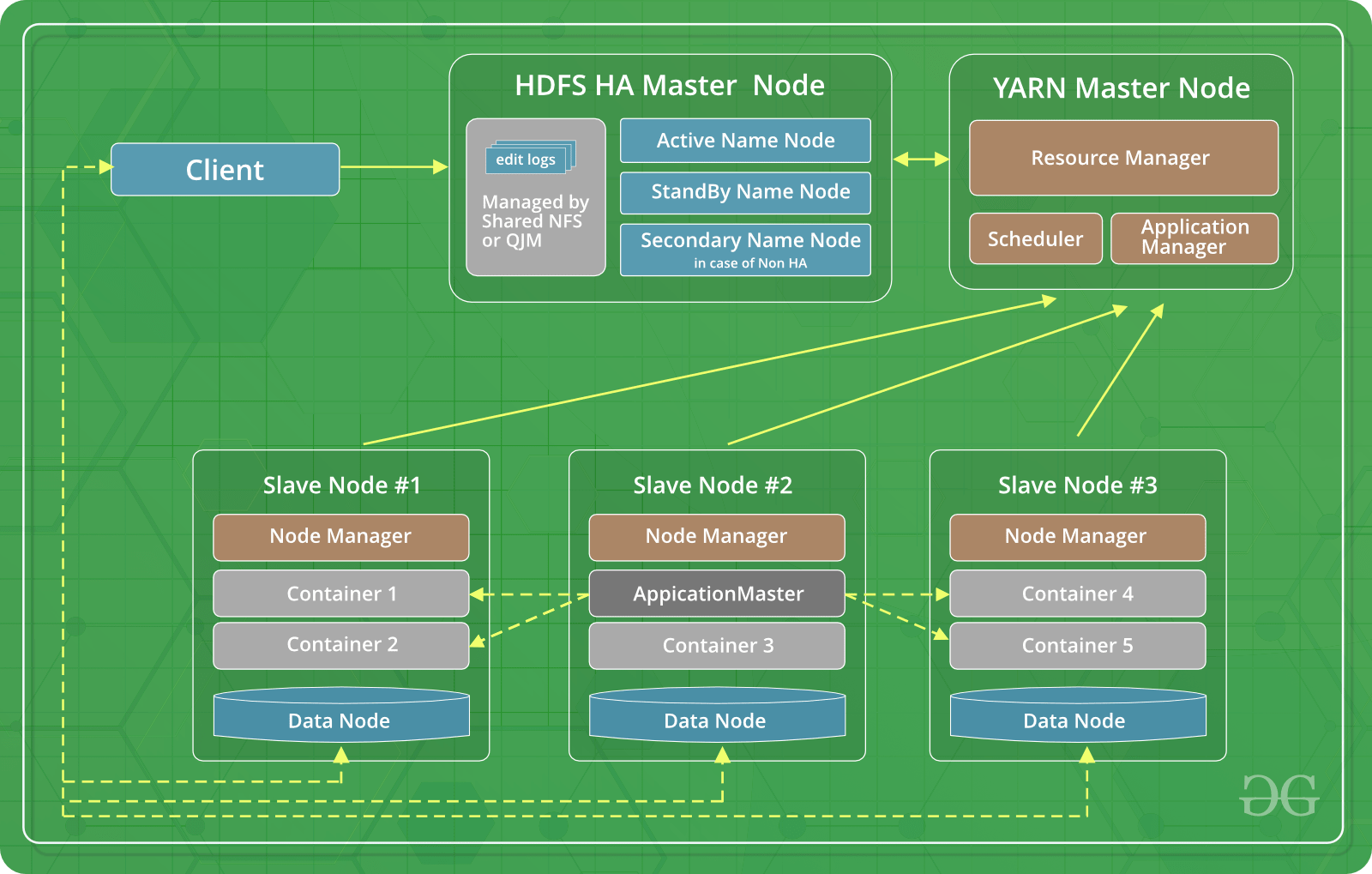
- Hadoop 3: это последняя версия Hadoop. Наряду с достоинствами первых двух версий Hadoop 3 имеет одно важнейшее достоинство. Он решил проблему отказа единой точки за счет наличия нескольких узлов имен. Различные другие преимущества, такие как кодирование со стиранием, использование аппаратного обеспечения графического процессора и докеров, делают его лучше, чем более ранние версии Hadoop.
Особенности Hadoop. Среди различных функций Hadoop, которые делают его привлекательным выбором для аналитиков по всему миру, являются следующие:
- Экономически осуществимо: хранить и обрабатывать данные дешевле, чем при традиционном подходе. Поскольку фактические машины, используемые для хранения данных, являются только товарным оборудованием.
- Простота использования: над проектами или набором инструментов, предоставляемых Apache Hadoop, легко работать для анализа сложных наборов данных.
- Открытый исходный код: поскольку Hadoop распространяется как программное обеспечение с открытым исходным кодом под лицензией Apache License, за него не нужно платить, просто загрузите его и используйте.
- Отказоустойчивость: поскольку Hadoop хранит три копии данных, даже если одна копия будет потеряна из-за сбоя любого стандартного оборудования, данные будут в безопасности. Более того, поскольку Hadoop версии 3 имеет несколько узлов имен, даже единственная точка отказа Hadoop также была удалена.
- Масштабируемость: Hadoop по своей природе хорошо масштабируется. Если нужно увеличить или уменьшить масштаб кластера, достаточно изменить количество стандартного оборудования в кластере.
- Распределенная обработка: HDFS и Map Reduce обеспечивают распределенное хранение и обработку данных.
- Локальность данных: это одна из самых привлекательных и многообещающих функций Hadoop. В Hadoop для обработки запроса к набору данных вместо передачи данных на локальный компьютер мы отправляем запрос на сервер и получаем оттуда окончательный результат. Это называется локальностью данных.