Функции активации в нейронных сетях | Set2
Статья Activation-functions-neural-networks поможет понять использование функции активации вместе с объяснением некоторых ее вариантов, таких как linear, sigmoid, tanh, Relu и softmax. Существуют и другие варианты функции активации, такие как Elu, Selu, Leaky Relu, Softsign и Softplus, которые кратко обсуждаются в этой статье.
Функция Leaky Relu:
Leaky Rectified linear unit (Leaky Relu) - это расширение функции Relu для решения проблемы умирающего нейрона.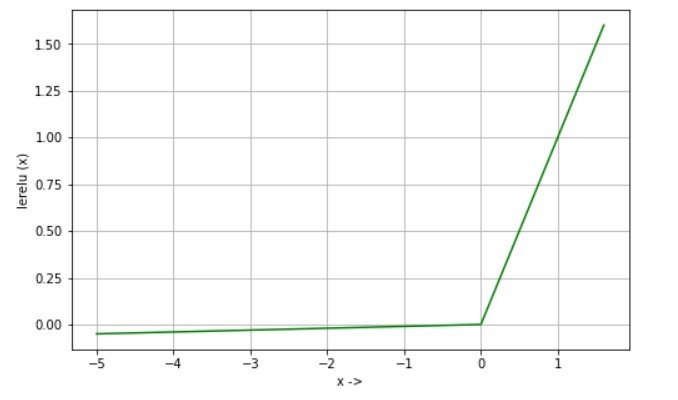
Уравнение:
lerelu (x) = x, если x> 0 lerelu (x) = 0,01 * x, если x <= 0
Производная:
d / dx lerelu (x) = 1, если x> 0 d / dx lerelu (x) = 0,01, если x <= 0
Использование: Relu возвращает 0, если вход отрицательный и, следовательно, нейрон становится неактивным, поскольку он не способствует градиентному потоку. Leaky Relu решает эту проблему, позволяя течь небольшому значению, когда входной сигнал отрицательный. Итак, если обучение с использованием Relu идет слишком медленно, можно попробовать использовать Leaky Relu, чтобы увидеть, произойдет ли улучшение или нет.
Функция Elu:
Экспоненциальная линейная единица также похожа на Leaky Relu, но отличается для отрицательного входа. Это также помогает преодолеть проблему умирающего нейрона.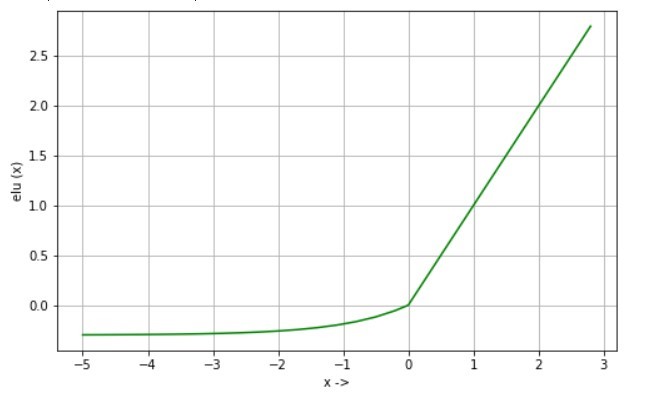
Уравнение:
elu (x) = x, если x> 0 elu (x) = alpha * (exp (x) -1), если x <0
Производная:
d / dx elu (x) = 1, если x> 0 d / dx elu (x) = elu (x) + alpha, если x <= 0
Использование: он имеет ту же цель, что и Leaky Relu, и сходимость функции стоимости к нулю быстрее, чем у Relu, а также у Leaky Relu. Например, обучение нейронной сети на Imagenet с использованием Elu происходит быстрее, чем с помощью Relu.
Функция Селу:
Масштабированная экспоненциальная линейная единица - это масштабированная форма Elu. Просто умножьте вывод Elu на заранее определенный параметр «scale», и вы получите желаемый результат, который дает selu.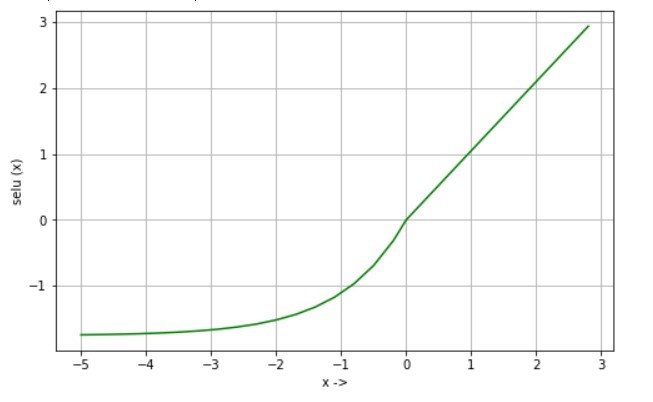
Уравнение:
selu (x) = масштаб * x, если x> 0 selu (x) = scale * alpha * (exp (x) -1), если x <= 0 где, альфа = 1,67326324 scale = 1.05070098
Производная:
d / dx selu (x) = масштаб, если x> 0 d / dx selu (x) = selu (x) + масштаб * альфа, если x <= 0
Использование: эта функция активации используется в самонормализующихся нейронных сетях (SNN), которые используются для обучения глубокой и надежной сети, менее подверженной исчезновению и взрыву градиента.
Функция софтсайна:
Функция Softsign является альтернативой функции tanh, где tanh сходится экспоненциально, а softsign сходится полиномиально.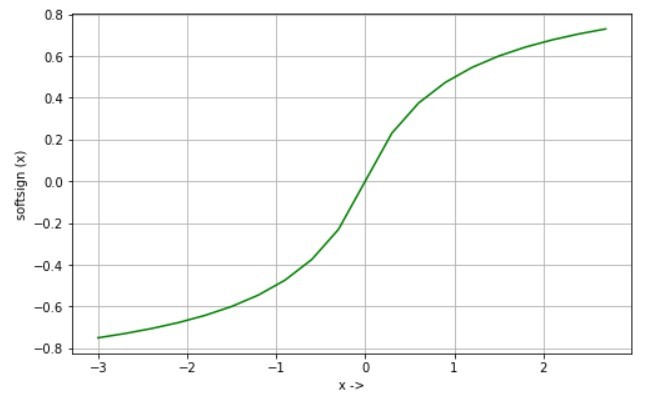
Уравнение:
softtsign (х) = х / (1 + | х |)
Производная:
d / dx softtsign (x) = 1 / (1 + | x |) ^ 2
Использование: в основном используется в задаче регрессии и может использоваться в глубокой нейронной сети для преобразования текста в речь.
Функция Softplus:
Функция Softplus - это сглаженная форма функции активации Relu, а ее производная - сигмовидная функция. Это также помогает в преодолении проблемы умирающего нейрона.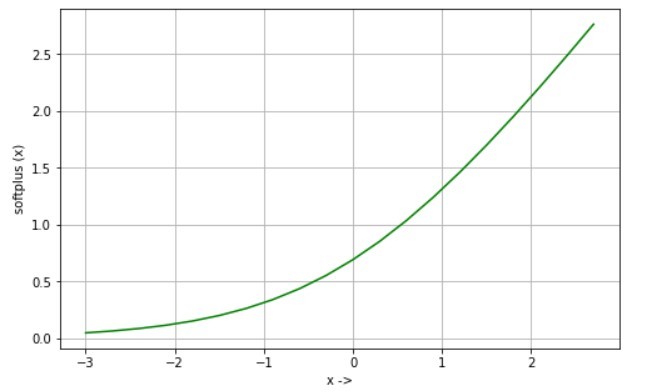 Уравнение:
Уравнение:
softplus (x) = журнал (1 + exp (x))
Производная:
d / dx softplus (x) = 1 / (1 + exp (-x))
Использование: Некоторые эксперименты показывают, что softplus требует меньше эпох, чтобы сойтись, чем Relu и sigmoid. Его можно использовать в системе распознавания речи.