DeepPose: оценка позы человека с помощью глубоких нейронных сетей
Опубликовано: 21 Июля, 2021
DeepPose был предложен исследователями из Google для оценки поз на конференции 2014 года по компьютерному зрению и распознаванию образов. Они работают над формулировкой задачи оценки позы как задачи регрессии на основе DNN к суставам тела. Они представляют собой каскад DNN-регрессоров, которые позволили получить высокоточные оценки позы.
Архитектура:
Вектор позы:
- Чтобы выразить человеческое тело в форме позы, авторы этой статьи кодируют расположение всех k частей тела в суставах, называемых вектором позы, определенным следующим образом
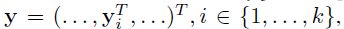
- где y i представляет собой координаты x, y местоположения i- го сустава тела.
- Изображение представлено в виде (x, y), где x - данные изображения, а y - данные вектора истинной позы.
- Поскольку описанные здесь координаты являются абсолютными координатами изображения в полном размере. Если мы изменим размер изображения, это может вызвать проблему. Поэтому мы нормализовали координаты относительно ограничивающего прямоугольника b, который ограничивает человеческое тело или некоторые его части. Эти блоки представлены как b = (b c , b h , b w, ), где b c - центр ограничивающей рамки, b h - высота, а b w - ширина границы.
- Мы нормализовали координаты местоположения по следующей формуле.
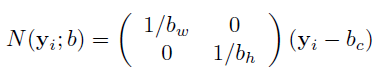
- Наконец, мы получаем нормализованные координаты вектора позы.
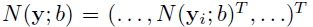
Архитектура CNN
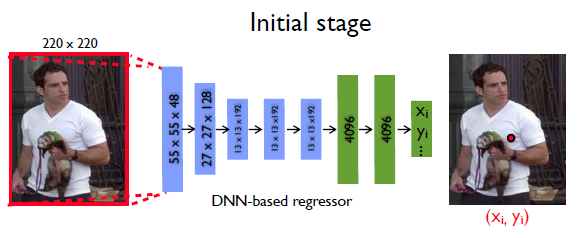
- Авторы этой статьи используют AlexNet в качестве архитектуры своей CNN, потому что она показала отличные результаты в задаче локализации изображений.
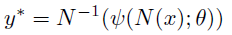
- где theta представляет обучаемые параметры (веса и смещения), shi представляет нейронную архитектуру, применяемую к нормализованному вектору позы N (x), прогнозируемый результат y * может быть получен денормализацией вывода (N -1 ).
- Эта архитектура нейронной сети берет изображение размером 220 × 220 и применяет шаг 4 .
- Архитектура CNN содержит 7 уровней, которые могут быть перечислены как: C (55 × 55 × 96) - LRN - P - C (27 × 27 × 256) - LRN - P - C (13 × 13 × 384) - C (13 × 13 × 384) - C (13 × 13 × 256) - P - F (4096) - F (4096)
- где C - сверточный слой, который использует ReLU в качестве функции активации для внесения нелинейности в модель, LRN - это нормализация локального отклика, P - уровень объединения, а F - полностью связанный слой.
- Последний уровень архитектуры выводит 2k совместных координат.
- Общее количество параметров - 40 миллионов.
- Архитектура использует функцию потерь L2, чтобы минимизировать расстояние между предсказанными координатами и функцией истинных потерь на земле.
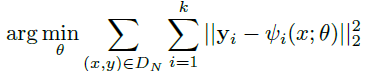
- где k - количество стыков на изображении
Регрессор DNN:
- Нелегко увеличить размер ввода, чтобы получить более точную оценку позы, поскольку это увеличит и без того большое количество параметров. Таким образом, предлагается каскад регрессоров позы для уточнения оценки позы.
- Теперь представим первый этап следующим уравнением
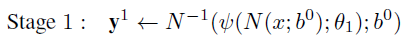
- где b 0 представляет собой полное изображение или ограничивающую рамку, полученную детектором человека.
- Теперь для последующих этапов s> = 2:
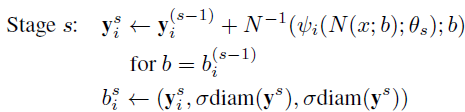
- где diam ( y ) - это расстояние между противоположными суставами, например, левым плечом и правым бедром, а затем масштабируется на? сделать это ? диам ( у ).
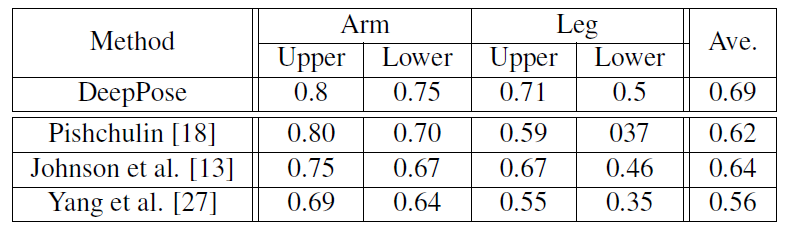
- Каскад DNN-регрессора повысил точность, как мы можем заметить из следующих изображений.

Метрики:
- Процент правильных частей (PCP) : он измеряет скорость обнаружения конечностей, при этом конечность считается обнаруженной, если расстояние между двумя прогнозируемыми местоположениями суставов и истинными местоположениями суставов конечностей составляет не более половины длины конечности. Однако у него есть недостатки, такие как штраф за более короткие и более трудные для обнаружения конечности.
- Процент обнаруженных суставов (PDJ) : для устранения недостатка, вызванного вышеуказанным методом, предлагается другой показатель, основанный на обнаружении суставов. Сустав считается обнаруженным, если расстояние между прогнозируемым и истинным суставом находится в пределах определенной части туловища. диаметр. Изменяя эту долю, можно получить степень обнаружения для различной степени точности локализации.
Полученные результаты:
- Набор данных Framed Label In Cinema (FLIC): этот набор данных содержит 4000 изображений поездов с 1000 тестовых изображений из голливудских фильмов с разными позами и одеждой. Для каждого человека с меткой помечено 10 суставов верхней части тела.

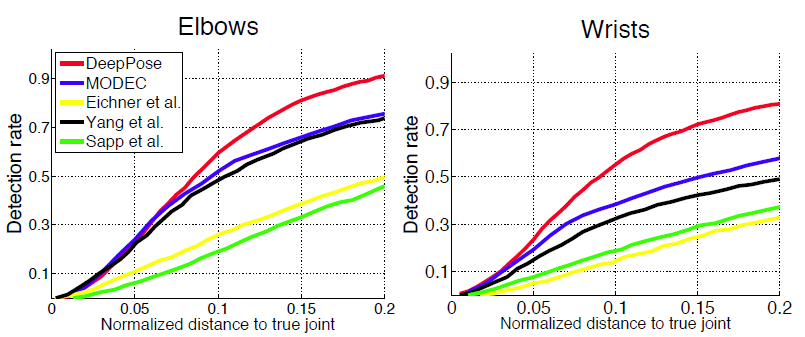
- Leeds Sports Dataset (LSP): Этот набор данных содержит 11000 тренировочных и 1000 тестовых изображений спортивных мероприятий со сложной внешностью и особенно с точки зрения артикуляции. В этом наборе данных для каждого человека все тело обозначено 14 суставами.

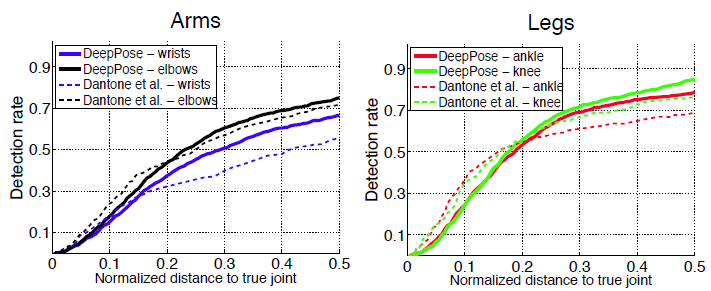
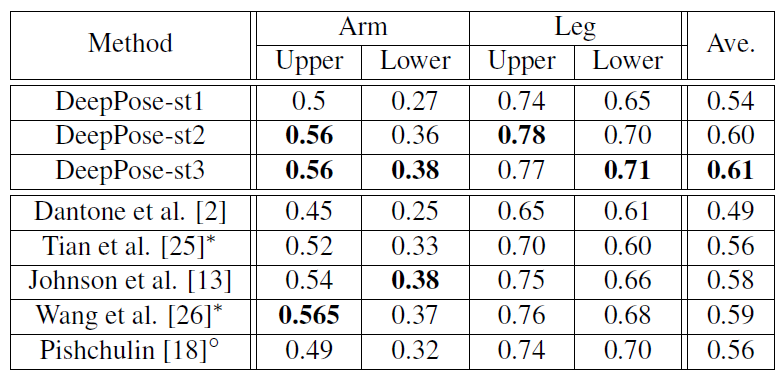
- Чтобы решить проблему обобщения модели, обученной на наборе данных FLIC и LSP, производительность также оценивается на наборе данных Buffy и наборе данных Image Parse.
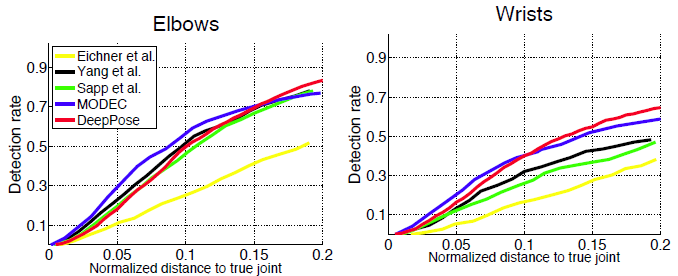
Рекомендации:
- Бумага DeepPose