Data Mining | Комплект 2
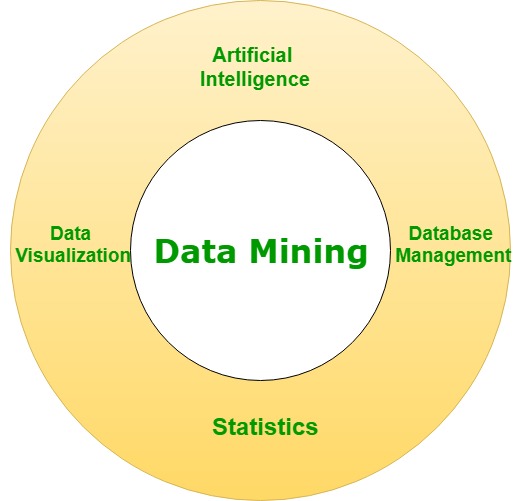
Data Mining может быть термином из прикладной науки. Обычно это дополнительно называют обнаружением данных в базах данных (KDD). Обработка данных связана с поиском новой информации в огромном количестве знаний. данные, полученные в результате обработки данных, будем надеяться каждый новый и полезный.
За работой:
В некоторых случаях информация сохраняется; поэтому его можно использовать позже. данные сохраняются с целью. Например, магазину нужно сэкономить много из того, что было куплено. Им нужно попытаться сделать это, чтобы понять, какое количество они должны купить сами, чтобы иметь достаточно, чтобы продать позже. Сохранение этой информации дает много знаний. информация иногда сохраняется в виде избыточной информации. объяснение того, почему информация сохраняется, называется основным использованием.
Позже постоянная информация может также использоваться для получения альтернативной информации, которая не требовалась для основного использования. магазину, возможно, необходимо в настоящее время понять, какие разумные вещи люди покупают после того, как они совершают покупки в магазине. (Многие люди, которые покупают еду, дополнительно покупают грибы в качестве примера.) Этот вид {информации | информации | знаний} находится в пределах данных и полезен, однако не является объяснением того, почему данные были сохранены. Эта информация новая и может быть полезной. Это второе использование постоянной информации. Поиск новой информации, которая даже будет полезной из информации, называется обработкой данных.
Что касается данных, существует множество различных видов обработки данных для получения новой информации. Обычно речь идет о предсказании; есть неуверенность в ожидаемых результатах. последующее основано на наблюдении, что есть маленькое неопытное яблоко, во время которого мы можем структурно изменить нашу информацию. Вот несколько видов обработки данных:
Распознавание образов (Попытка найти сходства в строках отчета в рамках правил. Крошечный -> неопытный. (Маленькие яблоки квадратной меткой обычно зеленые))
Использование сети теорем (Попытка создать что-то одно, что, однако, будет говорить, что различные информационные атрибуты связаны / влияют друг на друга. Размеры и, следовательно, цветовая квадратная мера связаны. Поэтому, если вы узнаете одну вещь, касающуюся аспектов, вы угадаю цвет.)
Использование нейронной сети (попытка создать модель мозга, которую трудно понять; однако компьютер скажет, что если яблоко неопытное, то следующая вероятность быть горьким, если мы склонны говорить компьютеру: Apple неопытна. поэтому часто это своего рода модель диктофона, у нас есть тенденция к тому, что она не работает, но она работает.)
Использование дерева классификации (со всеми альтернативными данными, пытающимися указать, какая именно альтернативная проблема, связанная с проблемой, мы склонны к квадратичной оценке, наблюдение будет. Вот ассоциативное яблоко с размером, цветом и блеском, на что будет похож его стиль? )
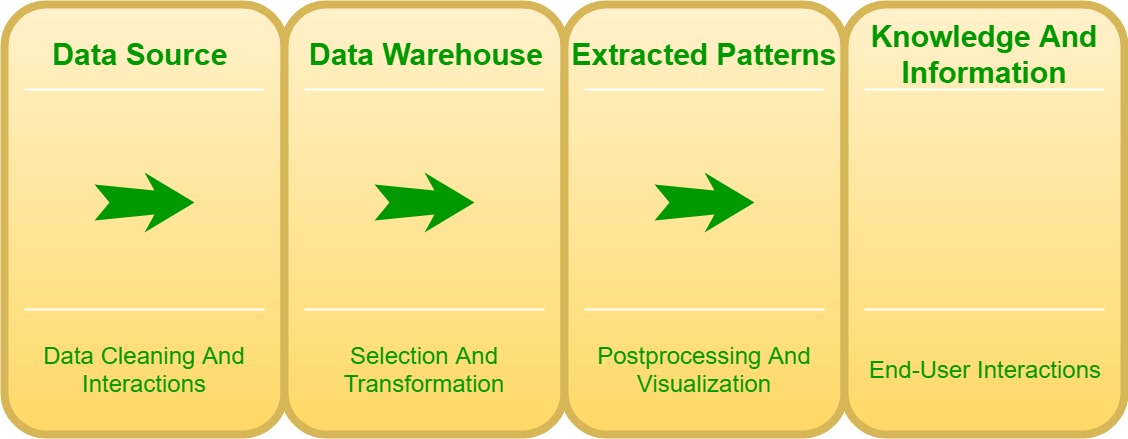
Интеллектуальный анализ данных требует подготовки информации, которая может раскрыть информацию или шаблоны, которые могут поставить под угрозу конфиденциальность и обязательства по обеспечению конфиденциальности. Стандартное средство для этого - агрегация информации. Агрегирование информации включает в себя объединение информации (возможно, из многочисленных источников) в очень средства, которые облегчают анализ (но это дополнительно, возможно, будет способствовать идентификации личной информации на индивидуальном уровне дедуктивным или иным образом очевидным). Это может быть не внутренняя обработка данных, а результаты подготовки данных перед анализом и для его нужд.
Угроза неприкосновенности частной жизни вступает в игру, как только информация после компиляции заставляет человека, работающего вручную над информацией, или любого другого учреждения Организации Объединенных Наций, имеющего доступ к недавно собранному набору информации, быть готовым определить конкретных людей, особенно если информация ранее была анонимный.
Данные также могут быть изменены; поэтому, чтобы стать анонимным, чтобы люди не могли быть известны сразу. Однако даже «деидентифицированные» / «анонимные» информационные наборы, несомненно, будут содержать достаточно информации, чтобы позволить идентифицировать людей, как это произошло, когда журналисты были готовы понять, что многие люди поддерживали группу историй поиска, которые неосознанно были бесплатными для AOL.