Архитектура Hadoop YARN
YARN означает « еще один переговорщик ресурсов ». Он был введен в Hadoop 2.0 для устранения узкого места в Job Tracker, которое присутствовало в Hadoop 1.0. Во время запуска YARN описывалась как « переработанный диспетчер ресурсов », но теперь она стала известна как крупномасштабная распределенная операционная система, используемая для обработки больших данных.
Архитектура YARN в основном отделяет уровень управления ресурсами от уровня обработки. В версии Hadoop 1.0 ответственность за отслеживание заданий разделена между диспетчером ресурсов и диспетчером приложений.
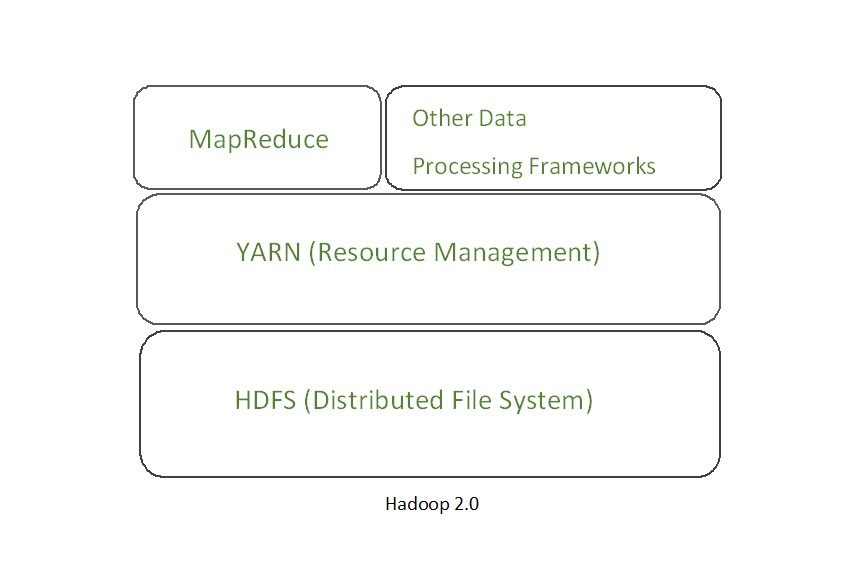
YARN также позволяет различным механизмам обработки данных, таким как обработка графиков, интерактивная обработка, потоковая обработка, а также пакетная обработка, запускать и обрабатывать данные, хранящиеся в HDFS (распределенная файловая система Hadoop), что делает систему намного более эффективной. Посредством своих различных компонентов он может динамически распределять различные ресурсы и планировать обработку приложений. Для обработки больших объемов данных совершенно необходимо правильно управлять доступными ресурсами, чтобы каждое приложение могло их использовать.
Особенности ПРЯЖИ: ПРЯЖА приобрела популярность благодаря следующим характеристикам:
- Масштабируемость . Планировщик в диспетчере ресурсов архитектуры YARN позволяет Hadoop расширять и управлять тысячами узлов и кластеров.
- Совместимость: YARN без сбоев поддерживает существующие приложения map-reduce, что делает его также совместимым с Hadoop 1.0.
- Использование кластера: поскольку YARN поддерживает динамическое использование кластера в Hadoop, что позволяет оптимизировать использование кластера.
- Многопользовательская среда: она обеспечивает доступ к нескольким серверам, что дает организациям возможность пользоваться несколькими арендаторами.
Архитектура Hadoop YARN
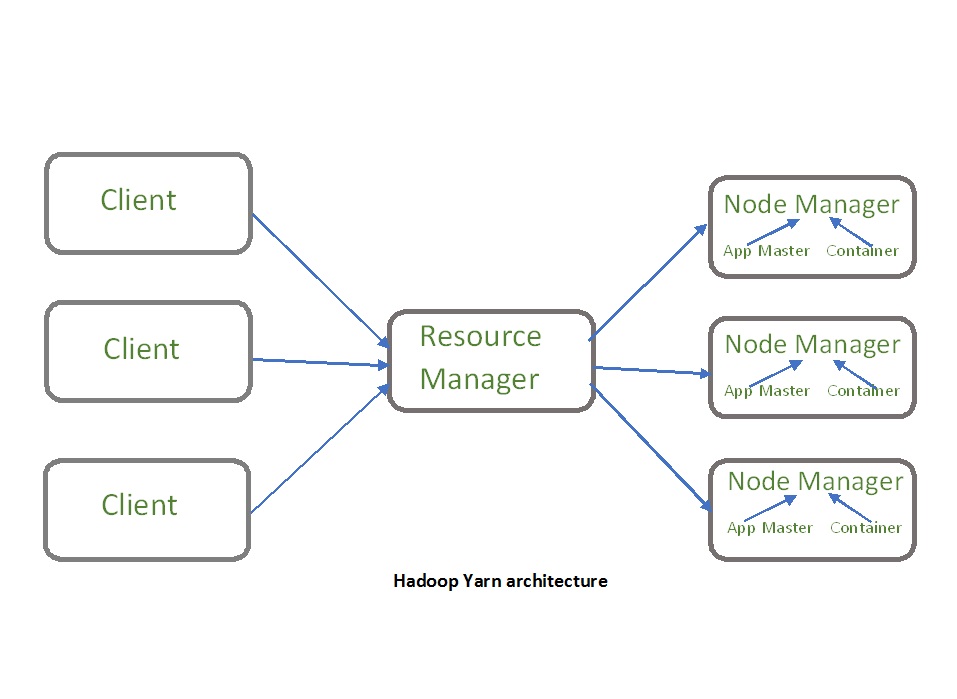
Основные компоненты архитектуры YARN включают:
- Клиент: он отправляет задания по сокращению карты.
- Диспетчер ресурсов: это главный демон YARN, который отвечает за назначение ресурсов и управление всеми приложениями. Всякий раз, когда он получает запрос на обработку, он пересылает его соответствующему администратору узла и соответственно выделяет ресурсы для завершения запроса. Он состоит из двух основных компонентов:
- Планировщик: он выполняет планирование на основе выделенного приложения и доступных ресурсов. Это чистый планировщик, что означает, что он не выполняет других задач, таких как мониторинг или отслеживание, и не гарантирует перезапуск в случае сбоя задачи. Планировщик YARN поддерживает такие плагины, как Capacity Scheduler и Fair Scheduler для разделения ресурсов кластера.
- Диспетчер приложений: он отвечает за принятие приложения и согласование первого контейнера от диспетчера ресурсов. Он также перезапускает контейнер диспетчера приложений в случае сбоя задачи.
- Node Manager: он заботится об отдельном узле в кластере Hadoop и управляет приложением, рабочим процессом и этим конкретным узлом. Его основная задача - не отставать от Node Manager. Он отслеживает использование ресурсов, выполняет управление журналами, а также уничтожает контейнер в соответствии с указаниями диспетчера ресурсов. Он также отвечает за создание процесса контейнера и запуск его по запросу мастера приложения.
- Мастер приложений: приложение - это отдельное задание, отправленное в платформу. Диспетчер приложений отвечает за согласование ресурсов с диспетчером ресурсов, отслеживание состояния и мониторинг выполнения отдельного приложения. Мастер приложения запрашивает контейнер у диспетчера узлов, отправляя контекст запуска контейнера (CLC), который включает все, что необходимо приложению для запуска. После запуска приложение время от времени отправляет отчет о работоспособности диспетчеру ресурсов.
- Контейнер: это набор физических ресурсов, таких как ОЗУ, ядра ЦП и диск на одном узле. Контейнеры вызываются контекстом запуска контейнера (CLC), который представляет собой запись, содержащую такую информацию, как переменные среды, токены безопасности, зависимости и т. Д.
Рабочий процесс приложения в Hadoop YARN:
- Клиент подает заявку
- Диспетчер ресурсов выделяет контейнер для запуска диспетчера приложений.
- Диспетчер приложений регистрируется в диспетчере ресурсов.
- Диспетчер приложений согласовывает контейнеры с диспетчером ресурсов.
- Диспетчер приложений уведомляет диспетчер узлов о запуске контейнеров.
- Код приложения выполняется в контейнере
- Клиент связывается с диспетчером ресурсов / диспетчером приложений для отслеживания статуса приложения.
- После завершения обработки диспетчер приложений отменяет регистрацию в диспетчере ресурсов.