Анализ тестовых данных с использованием кластеризации K-средних в Python
Эта статья демонстрирует иллюстрацию кластеризации K-средних на выборке случайных данных с использованием библиотеки open-cv.
Предварительные требования: Numpy, OpenCV, matplot-lib
Давайте сначала визуализируем тестовые данные с несколькими функциями, используя инструмент matplot-lib.
# importing required toolsimport numpy as npfrom matplotlib import pyplot as plt # creating two test dataX = np.random.randint( 10 , 35 ,( 25 , 2 ))Y = np.random.randint( 55 , 70 ,( 25 , 2 ))Z = np.vstack((X,Y))Z = Z.reshape(( 50 , 2 )) # convert to np.float32Z = np.float32(Z) plt.xlabel( 'Test Data' )plt.ylabel( 'Z samples' ) plt.hist(Z, 256 ,[ 0 , 256 ]) plt.show() |
Здесь «Z» - это массив размером 100 и значениями от 0 до 255. Теперь преобразовал «z» в вектор-столбец. Это будет более полезно, когда присутствует более одной функции. Затем измените данные на тип np.float32.
Выход: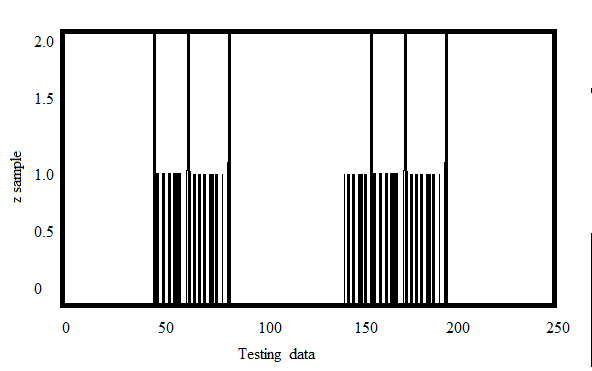
Теперь примените алгоритм кластеризации k-средних к тому же примеру, что и в приведенных выше тестовых данных, и посмотрите его поведение.
Вовлеченные шаги:
1) Сначала нам нужно установить тестовые данные.
2) Определите критерии и примените kmeans ().
3) Теперь разделите данные.
4) Наконец, постройте данные.
Выход: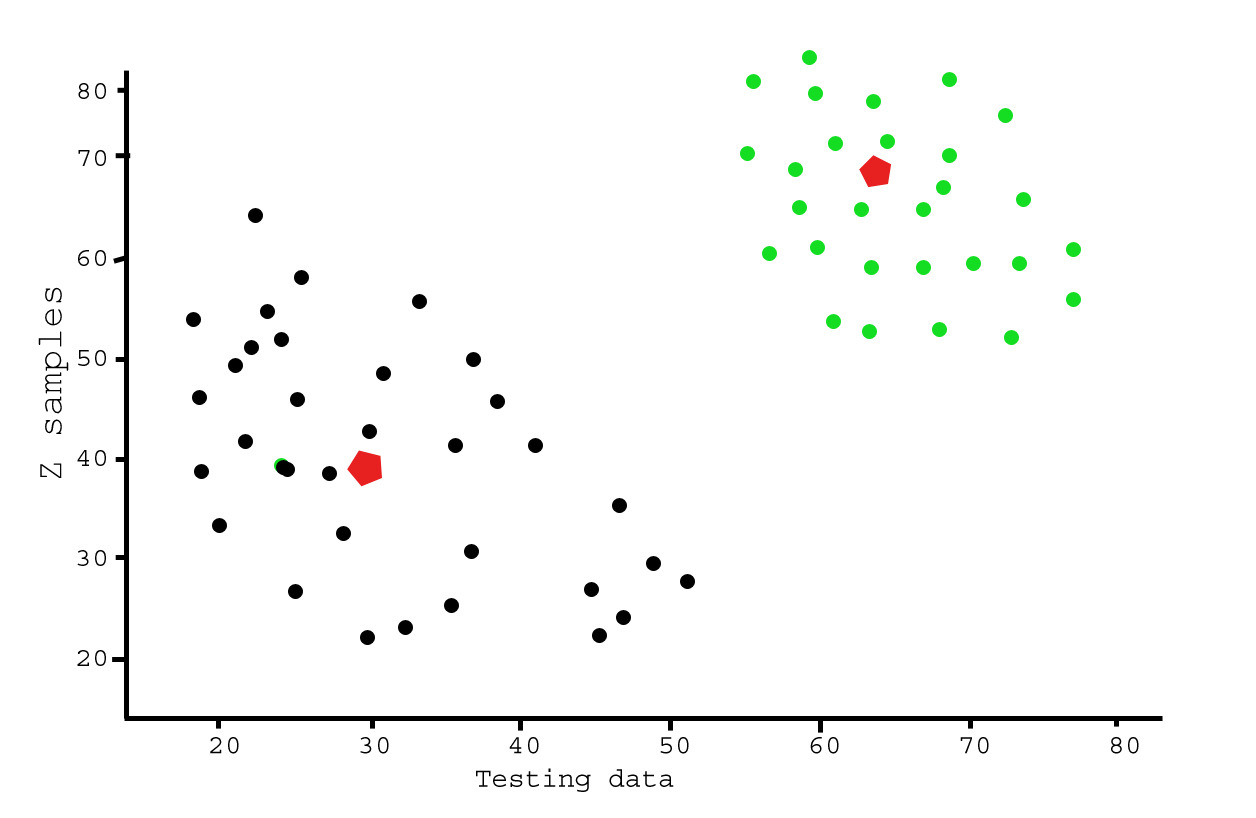
Этот пример предназначен для иллюстрации того, где k-means будет создавать интуитивно возможные кластеры.
Приложения :
1) Выявление раковых данных.
2) Прогнозирование успеваемости студентов.
3) Прогноз активности лекарства.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.