Анализ скорости передачи мобильных данных из TRAI с помощью Pandas
Python - отличный язык для анализа данных, в первую очередь из-за фантастической экосистемы пакетов Python, ориентированных на данные. Pandas - один из таких пакетов, который значительно упрощает импорт и анализ данных.
Давайте воспользуемся реальным набором данных из TRAI для анализа скорости мобильных данных и попытаемся увидеть средние скорости для конкретного оператора или штата в этом месяце. Это также покажет, насколько легко Pandas можно использовать с любыми реальными данными для получения интересных результатов.
О наборе данных -
Регулирующий орган Индии (TRAI) ежемесячно публикует набор данных о скорости интернета, измеряемой с помощью приложения MySpeed (TRAI). Сюда входят тесты скорости, инициированные самим пользователем, или периодические фоновые тесты, выполняемые приложением. Мы попытаемся проанализировать этот набор данных и увидеть средние скорости для конкретного оператора или штата в этом месяце.
Проверка необработанной структуры данных:
- Перейдите на портал TRAI MySpeed и загрузите CSV-файл за последний месяц в разделе « Загрузки ». Вы также можете скачать CSV-файл, использованный в этой статье: sept18_publish.csv или sept18_publish_drive.csv

- Откройте этот файл электронной таблицы.
ПРИМЕЧАНИЕ . Поскольку набор данных огромен, программное обеспечение может выдать предупреждение о том, что не удалось загрузить все строки. Это хорошо. Также, если вы используете Microsoft Excel, может появиться предупреждение об открытии файла SYLK. Эту ошибку можно игнорировать, поскольку это распространенная ошибка в Excel.
Теперь давайте посмотрим на расположение данных -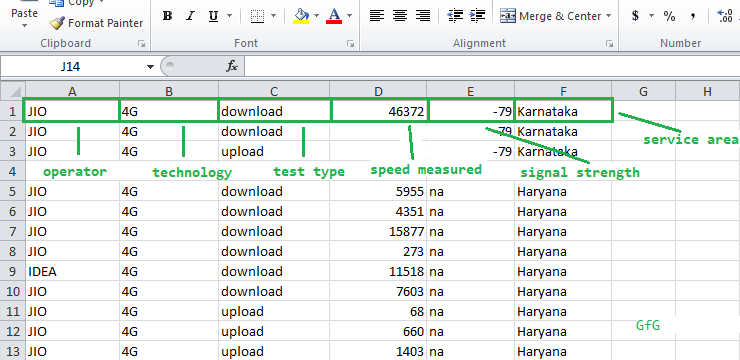
Имена столбцов в наборе данных
1st column is of the Network Operator – JIO, Airtel etc.
2nd column is of the Network Technology – 3G or 4G.
3rd column is the Type of Test initiated – upload or download.
4th column is the Speed Measured in Kilobytes per second.
5th column is the Signal Strength during the measurement.
6th column is the Local Service Area(LSA), or the circle where the test was done – Delhi, Orissa etc. We will refer to this as simply ‘states’.ПРИМЕЧАНИЕ. Уровень сигнала может иметь значения
na (Not Available)из-за того, что некоторые устройства не могут захватывать сигнал. Мы проигнорируем использование этого параметра в наших расчетах, чтобы упростить задачу. Однако его можно легко добавить в качестве условия при фильтрации.Packages required –
Pandas – a popular data analysis toolkit. Very powerful for crunching large sets of data.
Numpy – provides fast and efficient operations on arrays of homogeneous data. We will use this to along with pandas and matplotlib.
Matplotlib – is a plotting library. We will use its bar plotting function to make bar graphs.Приступим к анализу данных.
Шаг №1: Импортируйте пакеты и определите некоторые константы.
importpandas as pdimportnumpy as npimportmatplotlib.pyplot as plt# we will define some constants# name of the csv datasetDATASET_FILENAME='sept18_publish.csv'# define the operator to be filtered upon.CONST_OPERATOR='JIO'# define the state to be filtered upon.CONST_STATE='Delhi'# define the the technology to be filtered uponCONST_TECHNOLOGY='4G'
Шаг № 2: Определите несколько списков, в которых будут храниться окончательные результаты вычислений, чтобы их можно было легко передать в функцию построения столбцов. Состояние (или оператор), скорость загрузки и скорость загрузки будут сохраняться последовательно, так что для индекса, состояния (или оператора) можно получить доступ к соответствующей скорости загрузки и выгрузки.Например,
final_states[2], final_download_speeds[2]иfinal_upload_speeds[2]дадут соответствующие значения для 3-го состояния.# define listsfinal_download_speeds=[]final_upload_speeds=[]final_states=[]final_operators=[]Шаг № 3: Импортируйте файл с помощью функции Pandas
read_csv()и сохраните его в 'df'. Это создаст DataFrame содержимого csv, над которым мы будем работать.df=pd.read_csv(DATASET_FILENAME)# assign headers for each of the columns based on the data# this allows us to access columns easilydf.columns=['Service Provider','Technology','Test Type','Data Speed','Signal Strength','State']Шаг №4: Сначала давайте найдем все уникальные состояния и операторы в этом наборе данных и сохраним их в соответствующих списках состояний и операторов.
Мы будем использовать метод
unique()фрейма данных Pandas.# find and display the unique statesstates=df['State'].unique()print('STATES Found: ', states)# find and display the unique operatorsoperators=df['Service Provider'].unique()print('OPERATORS Found: ', operators)Выход:
ШТАТЫ Найдено: ['Керала' Раджастан 'Махараштра' ВВЕРХ Востока 'Карнатака нан 'Мадхья-Прадеш' Калькутта 'Бихар' Гуджарат 'UP West' Орисса ' 'Тамил Наду' Дели 'Ассам' Андхра-Прадеш 'Харьяна' Пенджаб 'Северо-восток' Мумбаи 'Ченнаи' Химачал-Прадеш 'Джамму и Кашмир' 'Западная Бенгалия'] ОПЕРАТОРЫ Найдено: ['IDEA' 'JIO' 'AIRTEL' 'VODAFONE' 'CELLONE']
Шаг № 5: Определите функцию
fixed_operator, которая будет сохранять оператор постоянным и перебирать все доступные состояния для этого оператора. Мы можем построить аналогичную функцию для фиксированного состояния.# filter out the operator and technology# first as this will be common for allfiltered=df[(df['Service Provider']==CONST_OPERATOR)& (df['Technology']==CONST_TECHNOLOGY)]# iterate through each of the statesforstateinstates:# create new dataframe which contains# only the data of the current statebase=filtered[filtered['State']==state]# filter only download speeds based on test typedown=base[base['Test Type']=='download']# filter only upload speeds based on test typeup=base[base['Test Type']=='upload']# calculate mean of speeds in Data Speed# column using the Pandas.mean() methodavg_down=down['Data Speed'].mean()# calculate mean of speeds# in Data Speed columnavg_up=up['Data Speed'].mean()# discard values if mean is not a number(nan)# and append only the valid onesif(pd.isnull(avg_down)orpd.isnull(avg_up)):down, up=0,0else:final_states.append(state)final_download_speeds.append(avg_down)final_upload_speeds.append(avg_up)# print output upto 2 decimal placesprint(str(state)+' -- Avg. Download: '+str('%.2f'%avg_down)+' Avg. Upload: '+str('%.2f'%avg_up))Выход:
Керала - Ср. Скачать: 26129.27 Avg. Загружен: 5193.46 Раджастан - Ср. Скачать: 27784.86 Avg. Загружен: 5736.18 Махараштра - Ср. Скачать: 20707.88 Avg. Загружен: 4130.46 UP Восток - Ср. Скачать: 22451.35 Avg. Загрузить: 5727.95 Карнатака - Ср. Скачать: 16950.36 Avg. Загрузить: 4720.68 Мадхья-Прадеш - Ср. Скачать: 23594,85 Avg. Загрузить: 4802.89 Калькутта - Ср. Скачать: 26747.80 Avg. Загружен: 5655.55 Бихар - Ср. Скачать: 31730.54 Avg. Загружен: 6599.45 Гуджарат - Ср. Скачать: 16377.43 Avg. Загрузить: 3642.89 UP West - Сред. Скачать: 23720,82 Avg. Загружен: 5280.46 Орисса - Ср. Загрузить: 31502.05 Avg. Загружен: 6895.46 Тамил Наду - Ср. Скачать: 16689.28 Avg. Загрузить: 4107.44 Дели - Ср. Загрузить: 20308.30 Avg. Загружен: 4877.40 Ассам - Ср. Скачать: 5653.49 Avg. Загружен: 2864.47 Андхра-Прадеш - Ср. Скачать: 32444.07 Avg. Загрузить: 5755.95 Харьяна - Ср. Скачать: 7170.63 Avg. Загружен: 2680.02 Пенджаб - Ср. Скачать: 14454.45 Avg. Загружен: 4981.15 Северо-восток - ср. Скачать: 6702.29 Avg. Загружен: 2966.84 Мумбаи - Ср. Скачать: 14070.97 Avg. Загружен: 4118.21 Ченнаи - Ср. Скачать: 20054.47 Avg. Загружен: 4602.35 Химачал-Прадеш - Ср. Скачать: 7436,99 Avg. Загружен: 4020.09 Джамму и Кашмир - Ср. Скачать: 8759.20 Avg. Загружен: 4418.21 Западная Бенгалия - Ср. Скачать: 16821.17 Avg. Загружен: 3628.78
Построение данных -
Используйте метод
arange()для Numpy, который возвращает равномерно распределенные значения в пределах заданного интервала. Здесь, передавая длинуfinal_states, мы получаем значения от 0 до количества состояний в списке, например [0, 1, 2, 3…]
Затем мы можем использовать эти индексы для построения полосы в этом месте. Вторая полоса строится путем смещения положения первой полоски на ширину полоски.fig, ax=plt.subplots()# the width of each barbar_width=0.25# opacity of each baropacity=0.8# store the positionsindex=np.arange(len(final_states))# the plt.bar() takes in the position# of the bars, data to be plotted,# width of each bar and some other# optional parameters, like the opacity and colour# plot the download barsbar_download=plt.bar(index, final_download_speeds,bar_width, alpha=opacity,color='b', label='Download')# plot the upload barsbar_upload=plt.bar(index+bar_width, final_upload_speeds,bar_width, alpha=opacity, color='g',label='Upload')# title of the graphplt.title('Avg. Download/Upload speed for '+str(CONST_OPERATOR))# the x-axis labelplt.xlabel('States')# the y-axis labelplt.ylabel('Average Speeds in Kbps')# the label below each of the bars,# corresponding to the statesplt.xticks(index+bar_width, final_states, rotation=90)# draw the legendplt.legend()# make the graph layout tightplt.tight_layout()# show the graphplt.show()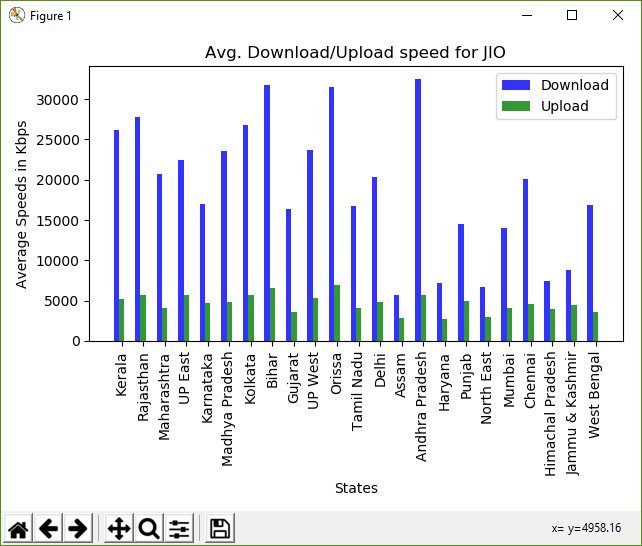
Гистограмма рассчитанных скоростей
Сравнение данных за два месяца -
Давайте также возьмем данные за другой месяц и построим их вместе, чтобы увидеть разницу в скорости передачи данных.
В этом примере набор данных предыдущего месяца будет таким же sept18_publish.csv, а набор данных следующего месяца - oct18_publish.csv.
Нам просто нужно повторить те же шаги снова. Прочтите данные за другой месяц. Отфильтруйте его до последующих фреймов данных, а затем нанесите на график немного другим методом. Во время построения столбцов мы увеличим 3-й и 4-й столбцы (соответствующие загрузке и скачиванию второго файла) в 2 и 3 раза ширины столбца, чтобы они находились в правильном положении.
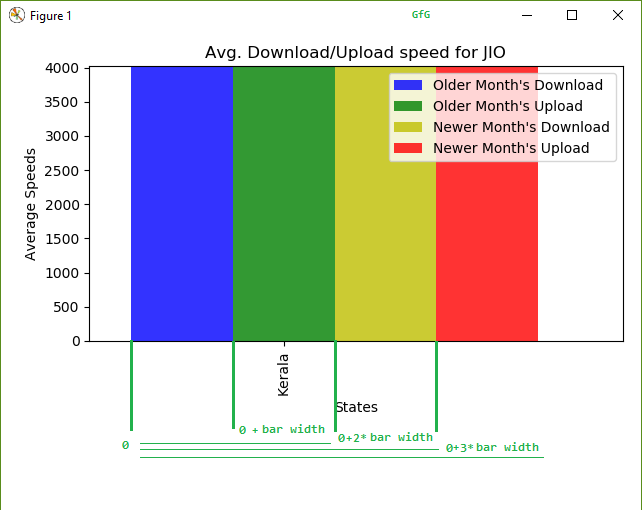
Логика смещения при построении 4 столбцов
Ниже представлена реализация для сравнения данных за 2 месяца:
importpandas as pdimportnumpy as npimportmatplotlib.pyplot as plttimeimport# older month# newer monthCONST_OPERATOR='JIO'CONST_STATE='Delhi'CONST_TECHNOLOGY='4G'# read file with Pandas and store as Dataframedf=pd.read_csv(DATASET_FILENAME)df2=pd.read_csv(DATASET_FILENAME2)# assign column namesdf.columns=['Service Provider','Technology','Test Type','Data Speed','Signal Strength','State']df2.columns=['Service Provider','Technology','Test Type','Data Speed','Signal Strength','State']# find and display the unique statesstates=df['State'].unique()print('STATES Found: ', states)# find and display the unique operatorsoperators=df['Service Provider'].unique()print('OPERATORS Found: ', operators)# define listsfinal_download_speeds=[]final_upload_speeds=[]final_download_speeds_second=[]final_upload_speeds_second=[]final_states=[]final_operators=[]# assign column names to the datadf.columns=['Service Provider','Technology','Test Type','Data Speed','Signal Strength','State']df2.columns=['Service Provider','Technology','Test Type','Data Speed','Signal Strength','State']print(' Comparing data for'+str(CONST_OPERATOR))filtered=df[(df['Service Provider']==CONST_OPERATOR)& (df['Technology']==CONST_TECHNOLOGY)]filtered2=df2[(df2['Service Provider']==CONST_OPERATOR)& (df2['Technology']==CONST_TECHNOLOGY)]forstateinstates:base=filtered[filtered['State']==state]# calculate mean of download speedsavg_down=base[base['Test Type']=='download']['Data Speed'].mean()# calculate mean of upload speedsavg_up=base[base['Test Type']=='upload']['Data Speed'].mean()base2=filtered2[filtered2['State']==state]# calculate mean of download speedsavg_down2=base2[base2['Test Type']=='download']['Data Speed'].mean()# calculate mean of upload speedsavg_up2=base2[base2['Test Type']=='upload']['Data Speed'].mean()# discard values if mean is not a number(nan)# and append only the needed speedsif(pd.isnull(avg_down)orpd.isnull(avg_up)orpd.isnull(avg_down2)orpd.isnull(avg_up2)):avg_down=0avg_up=0avg_down2=0avg_up2=0else:final_states.append(state)final_download_speeds.append(avg_down)final_upload_speeds.append(avg_up)final_download_speeds_second.append(avg_down2)final_upload_speeds_second.append(avg_up2)print('Older: '+str(state)+' -- Download: '+str('%.2f'%avg_down)+' Upload: '+str('%.2f'%avg_up))print('Newer: '+str(state)+' -- Download: '+str('%.2f'%avg_down2)+' Upload: '+str('%.2f'%avg_up2))# plot bargraphfig, ax=plt.subplots()index=np.arange(len(final_states))bar_width=0.2opacity=0.8rects1=plt.bar(index, final_download_speeds,bar_width, alpha=opacity, color='b',label='Older Month's Download')rects2=plt.bar(index+bar_width, final_upload_speeds,bar_width, alpha=opacity, color='g',label='Older Month's Upload')rects3=plt.bar(index+2*bar_width, final_download_speeds_second,bar_width, alpha=opacity, color='y',label='Newer Month's Download')rects4=plt.bar(index+3*bar_width, final_upload_speeds_second,bar_width, alpha=opacity, color='r',label='Newer Month's Upload')plt.xlabel('States')plt.ylabel('Average Speeds')plt.title('Avg. Download/Upload speed for '+str(CONST_OPERATOR))plt.xticks(index+bar_width, final_states, rotation=90)plt.legend()plt.tight_layout()plt.show()Выход:
ШТАТЫ Найдено: ['Керала' Раджастан 'Махараштра' ВВЕРХ Востока 'Карнатака нан 'Мадхья-Прадеш' Калькутта 'Бихар' Гуджарат 'UP West' Орисса ' 'Тамил Наду' Дели 'Ассам' Андхра-Прадеш 'Харьяна' Пенджаб 'Северо-восток' Мумбаи 'Ченнаи' Химачал-Прадеш 'Джамму и Кашмир' 'Западная Бенгалия'] ОПЕРАТОРЫ Найдено: ['IDEA' 'JIO' 'AIRTEL' 'VODAFONE' 'CELLONE']
Сравнение данных для JIO Раньше: Kerala - Загрузить: 26129.27 Загрузить: 5193.46 Новее: Kerala - Загрузить: 18917.46 Загрузить: 4290.13 Раньше: Rajasthan - Загрузить: 27784.86 Загрузить: 5736.18 Новее: Rajasthan - Загрузить: 13973.66 Загрузить: 4721.17 Ранее: Maharashtra - Загрузить: 20707.88 Загрузить: 4130.46 Новее: Maharashtra - Загрузить: 26285.47 Загрузить: 5848.77 Раньше: UP East - Загрузить: 22451.35 Загрузить: 5727.95 Новее: UP East - Загрузить: 24368.81 Загрузить: 6101.20 Раньше: Karnataka - Загрузить: 16950.36 Загрузить: 4720.68 Новее: Karnataka - Загрузить: 33521.31 Загрузить: 5871.38 Раньше: Мадхья-Прадеш - Загрузка: 23594.85 Загрузка: 4802.89 Новее: Мадхья-Прадеш - Загрузка: 16614.49 Загрузка: 4135.70 Раньше: Kolkata - Загрузить: 26747.80 Загрузить: 5655.55 Новее: Kolkata - Загрузить: 23761.85 Загрузить: 5153.29 Раньше: Bihar - Загрузить: 31730.54 Загрузить: 6599.45 Новее: Bihar - Загрузка: 34196.09 Загрузка: 5215.58 Раньше: Gujarat - Загрузить: 16377.43 Загрузить: 3642.89 Новее: Gujarat - Загрузить: 9557.90 Загрузить: 2684.55 Раньше: UP West - Загрузить: 23720.82 Загрузить: 5280.46 Новее: UP West - Загрузить: 35035.84 Загрузить: 5797.93 Раньше: Orissa - Загрузить: 31502.05 Загрузить: 6895.46 Новее: Orissa - Загрузка: 31826.96 Загрузка: 6968.59 Раньше: Tamil Nadu - Загрузить: 16689.28 Загрузить: 4107.44 Новее: Tamil Nadu - Загрузить: 27306.54 Загрузить: 5537.58 Раньше: Delhi - Загрузить: 20308.30 Загрузить: 4877.40 Новее: Delhi - Загрузить: 25198.16 Загрузить: 6228.81 Раньше: Assam - Загрузить: 5653.49 Загрузить: 2864.47 Новее: Assam - Загрузить: 5243.34 Загрузить: 2676.69 Ранее: Andhra Pradesh - Загрузить: 32444.07 Загрузить: 5755.95 Новее: Andhra Pradesh - Загрузить: 19898.16 Загрузить: 4002.25 Раньше: Haryana - Скачать: 7170.63 Загружать: 2680.02 Новее: Haryana - Загрузить: 8496.27 Загрузить: 2862.61 Раньше: Punjab - Загрузить: 14454.45 Загрузить: 4981.15 Новее: Punjab - Загрузить: 17960.28 Загрузить: 4885.83 Раньше: North East - Загрузить: 6702.29 Загрузить: 2966.84 Новее: North East - Загрузить: 6008.06 Загрузить: 3052.87 Раньше: Mumbai - Загрузить: 14070.97 Загрузить: 4118.21 Новее: Mumbai - Загрузить: 26898.04 Загрузить: 5539.71 Раньше: Chennai - Загрузить: 20054.47 Загрузить: 4602.35 Новее: Chennai - Загрузить: 36086.70 Загрузить: 6675.70 Раньше: Химачал-Прадеш - Загрузка: 7436.99 Загрузка: 4020.09 Новее: Himachal Pradesh - Загрузить: 9277.45 Загрузить: 4622.25 Ранее: Jammu & Kashmir - Загрузить: 8759.20 Загрузить: 4418.21 Новее: Jammu & Kashmir - Загрузить: 9290.38 Загрузить: 4533.08 Раньше: West Bengal - Загрузить: 16821.17 Загрузить: 3628.78 Новее: West Bengal - Загрузить: 9763.05 Загрузить: 2627.28
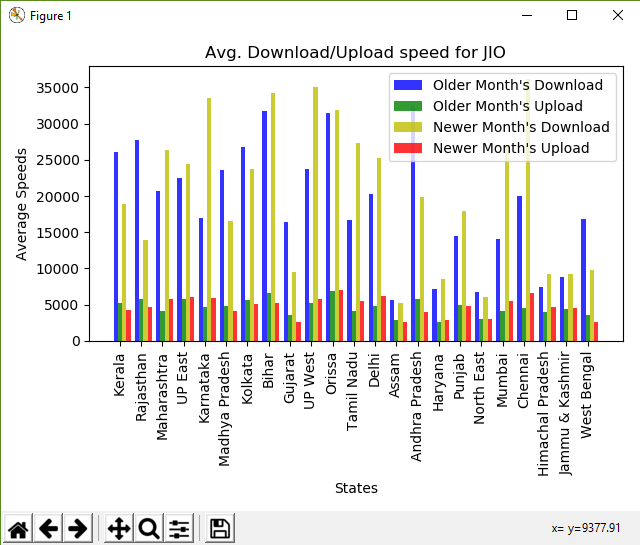
Гистограмма вывода
Мы только что научились анализировать некоторые данные из реального мира и делать из них интересные наблюдения. Но обратите внимание, что не все данные будут так хорошо отформатированы и с ними легко работать, Pandas позволяет невероятно легко работать с такими наборами данных.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.