5 общих концепций проектирования системы для подготовки к интервью
В процессе собеседования по программной инженерии раунд проектирования системы стал стандартной частью собеседования. Основная цель этого раунда - проверить способность кандидата построить сложную и крупномасштабную систему. Из-за отсутствия опыта построения крупномасштабной системы многие инженеры испытывают трудности с этим раундом. На конструкторские задачи нет точного и стандартного ответа. Вы можете по-разному разговаривать с разными интервьюерами по одному и тому же вопросу. Из-за открытого характера этого раунда не только разработчики младшего и среднего уровня, но и опытные разработчики чувствуют себя некомфортно в этом раунде.

В этом раунде мало внимания уделяется кодированию. Интервьюер хочет знать, как вы спроектируете всю систему и как склеить их вместе. Если вы готовитесь к этому раунду, мы рекомендуем вам прочитать блог Как взломать раунд проектирования системы в интервью? . Вы должны знать некоторые важные концепции проектирования системы, прежде чем приступить к подготовке к какому-то конкретному вопросу. Мы собираемся охватить некоторые базовые концепции системного проектирования, чтобы создать прочную основу для решения проблем в этом раунде.
1. Балансировка нагрузки
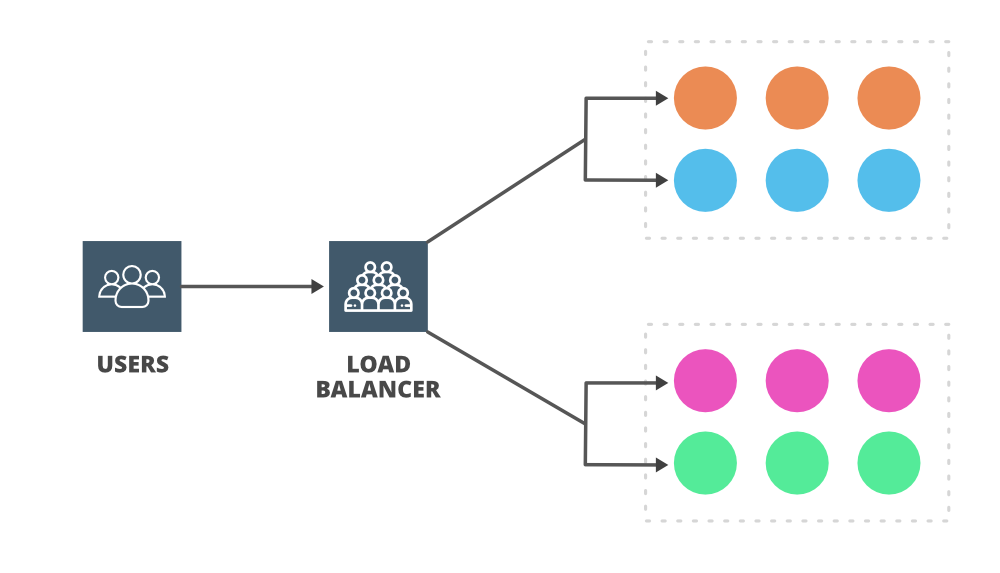
В системе сервер имеет определенную мощность для обработки нагрузки или запросов от пользователей. Если сервер получает одновременно много запросов, превышающих его мощность, пропускная способность сервера уменьшается, и он может замедлиться. Кроме того, это может быть неудачно (недоступно), если оно будет продолжаться в течение более длительного периода. Вы можете добавить больше серверов (горизонтальное масштабирование) и решить эту проблему, распределив количество запросов между этими серверами. Теперь вопрос в том, кто возьмет на себя ответственность за распределение запросов и балансировку нагрузки. Кто будет решать, какой запрос должен быть выделен какому серверу, чтобы облегчить нагрузку на один сервер? А вот и роль балансировщика нагрузки.
Задача балансировщика нагрузки - распределять трафик между множеством различных серверов, чтобы помочь с пропускной способностью, производительностью, задержкой и масштабируемостью. Вы можете поставить балансировщик нагрузки перед клиентами (он также может быть вставлен в другие места), а затем балансировщик нагрузки направит входящий запрос на несколько веб-серверов. Короче говоря, балансировщики нагрузки - это менеджеры трафика, которые берут на себя ответственность за доступность и пропускную способность системы. Nginx, Cisco, TP-Link, Barracuda, Citrix, Elastic Load Balancing от AWS… это некоторые популярные балансировщики нагрузки, доступные на рынке.
2. Кеширование
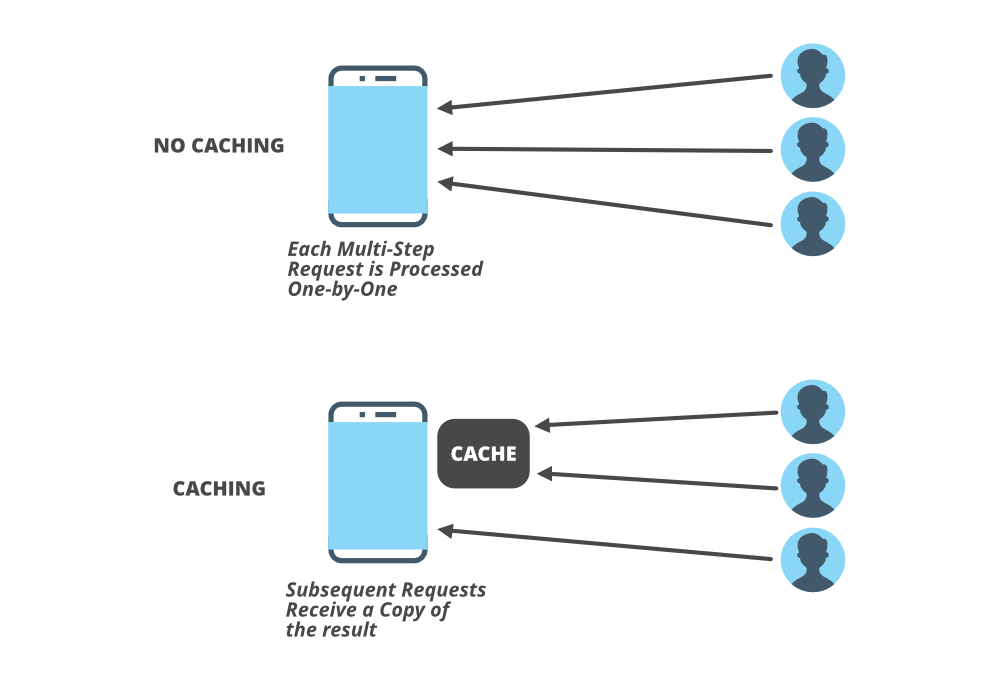
Мы говорили о нагрузке на серверы в разделе балансировки нагрузки, но вам нужно знать одну вещь: обычно ваш веб-сервер не выходит из строя первым, на самом деле, довольно часто это ваш сервер базы данных, который может испытывать высокие нагрузки для многих пишет или читает операции. Довольно часто мы обращаемся к базе данных по различным запросам и соединениям, что снижает производительность системы. Для обработки этих запросов и большого количества операций чтения и записи кэширование - лучший метод.
Вы ходите в ближайший магазин за предметами первой необходимости каждый раз, когда вам что-то нужно на кухне? абсолютно нет. Вместо того, чтобы посещать ближайший магазин каждый раз, когда мы хотим купить и хранить что-нибудь в нашем холодильнике и кухонном шкафу. Это кеширование. Время приготовления сокращается, если продукты уже есть в вашем холодильнике. Это экономит много времени. То же самое происходит в системе. Доступ к данным из первичной памяти (RAM) происходит быстрее, чем доступ к данным из вторичной памяти (диска). Используя технику кэширования, вы можете повысить производительность вашей системы.
Если вам нужно часто полагаться на определенный фрагмент данных, кешируйте данные и извлекайте их быстрее из памяти, а не с диска. Этот процесс снижает нагрузку на внутренние серверы. Кэширование помогает уменьшить количество обращений к базе данных по сети. Некоторыми популярными сервисами кеширования являются Memcache, Redis и Cassandra. Многие веб-сайты используют CDN (сеть доставки контента), которая представляет собой глобальную сеть серверов. CDN кэширует файлы статических ресурсов, такие как изображения, javascript, HTML или CSS, и это делает доступ пользователей очень быстрым. Вы можете добавить кэширование на клиенте (например, хранилище браузера), между клиентом и сервером (например, CDN) или на самом сервере.
3. Прокси
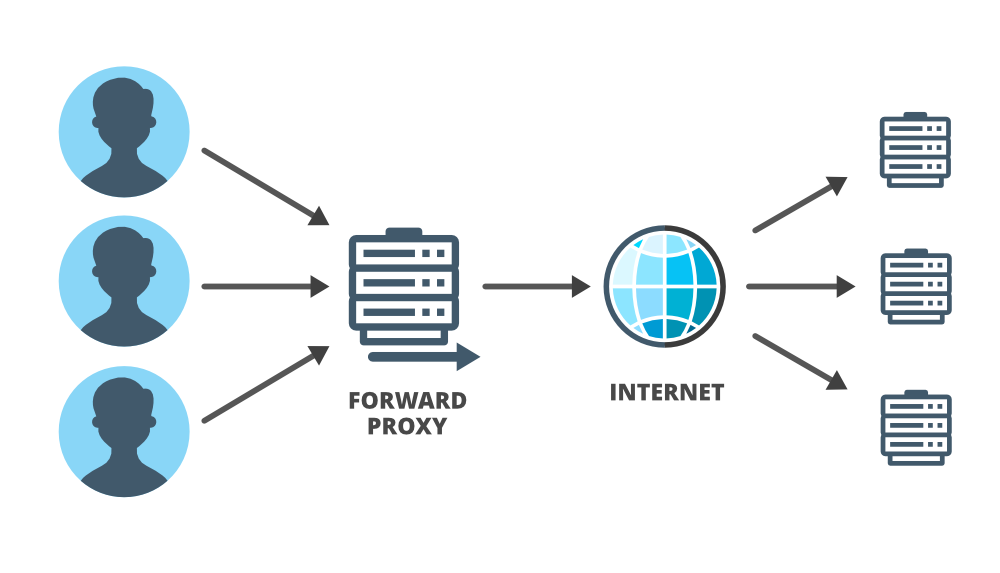
Довольно часто вы могли видеть на своем компьютере какое-либо уведомление о добавлении и настройке прокси-серверов, но что именно такое прокси-серверы и как они работают? Обычно прокси-серверы представляют собой некоторый фрагмент кода или промежуточную часть оборудования / программного обеспечения, которая находится между клиентом и другим сервером. Он может находиться на локальном компьютере пользователя или в любом месте между клиентами и конечными серверами. Прокси-сервер получает запросы от клиента и передает их исходным серверам, а затем пересылает полученный ответ от сервера клиенту-источнику. В некоторых случаях, когда сервер получает запрос, IP-адрес не связан с клиентом, а принадлежит прокси-серверу. Это происходит, когда прокси-сервер скрывает личность клиента.
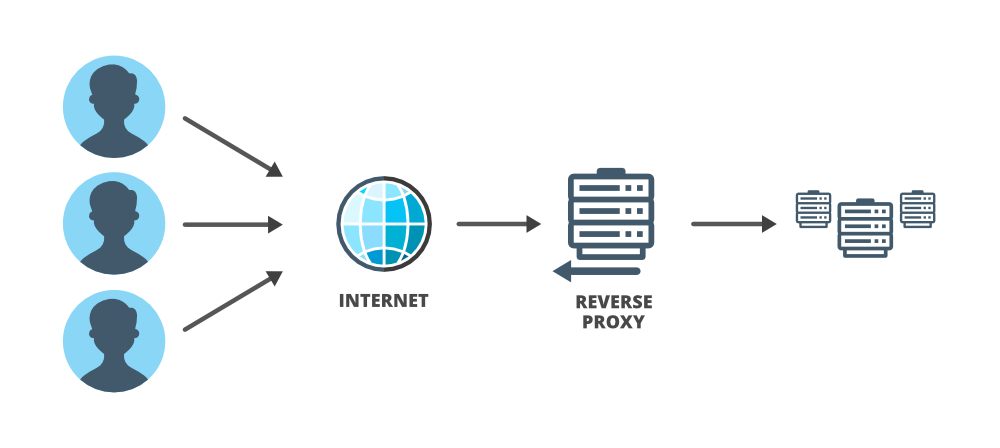
Обычно, когда люди используют термин «прокси», они имеют в виду «прямой прокси». «Прямой прокси» предназначен для помощи пользователям и действует от имени (заменяет) клиента при взаимодействии между клиентом и сервером. Он пересылает запросы пользователя и действует как его личный представитель. В системе, особенно в сложных системах, прокси очень полезны, особенно полезны «обратные прокси». «Обратные прокси» - это противоположность «прямого прокси». Обратный прокси действует от имени сервера и предназначен для помощи серверам.
В «прямом прокси-сервере» сервер не будет знать, что запрос и ответ направляются через прокси, а в обратном прокси-сервере клиент не будет знать, что запрос и ответ проходят через прокси. «Обратному прокси-серверу» можно поручить множество задач, чтобы помочь главному серверу, и он может действовать как привратник, проверяющий, балансировщик нагрузки и универсальный помощник.
Обычно прокси-серверы используются для обработки запросов, фильтрации запросов или запросов в журнал, а иногда и для преобразования запросов (путем добавления / удаления заголовков, шифрования / дешифрования или сжатия). Он помогает координировать запросы от нескольких серверов и может использоваться для оптимизации трафика запросов с точки зрения всей системы.
Прямой прокси:
Обратный прокси:
4. Теорема CAP.
CAP означает согласованность, доступность и допуск на разделы . Теорема утверждает, что вы не можете достичь всех свойств на лучшем уровне в одной базе данных, поскольку между элементами есть естественные компромиссы. Вы можете выбрать только два из трех одновременно, и это полностью зависит от ваших приоритетов в зависимости от ваших требований. Например, если ваша система должна быть доступной и устойчивой к разделам, вы должны быть готовы принять некоторую задержку в своих требованиях к согласованности. Традиционные реляционные базы данных естественным образом подходят для стороны CA, тогда как механизмы нереляционных баз данных в основном удовлетворяют требованиям AP и CP .
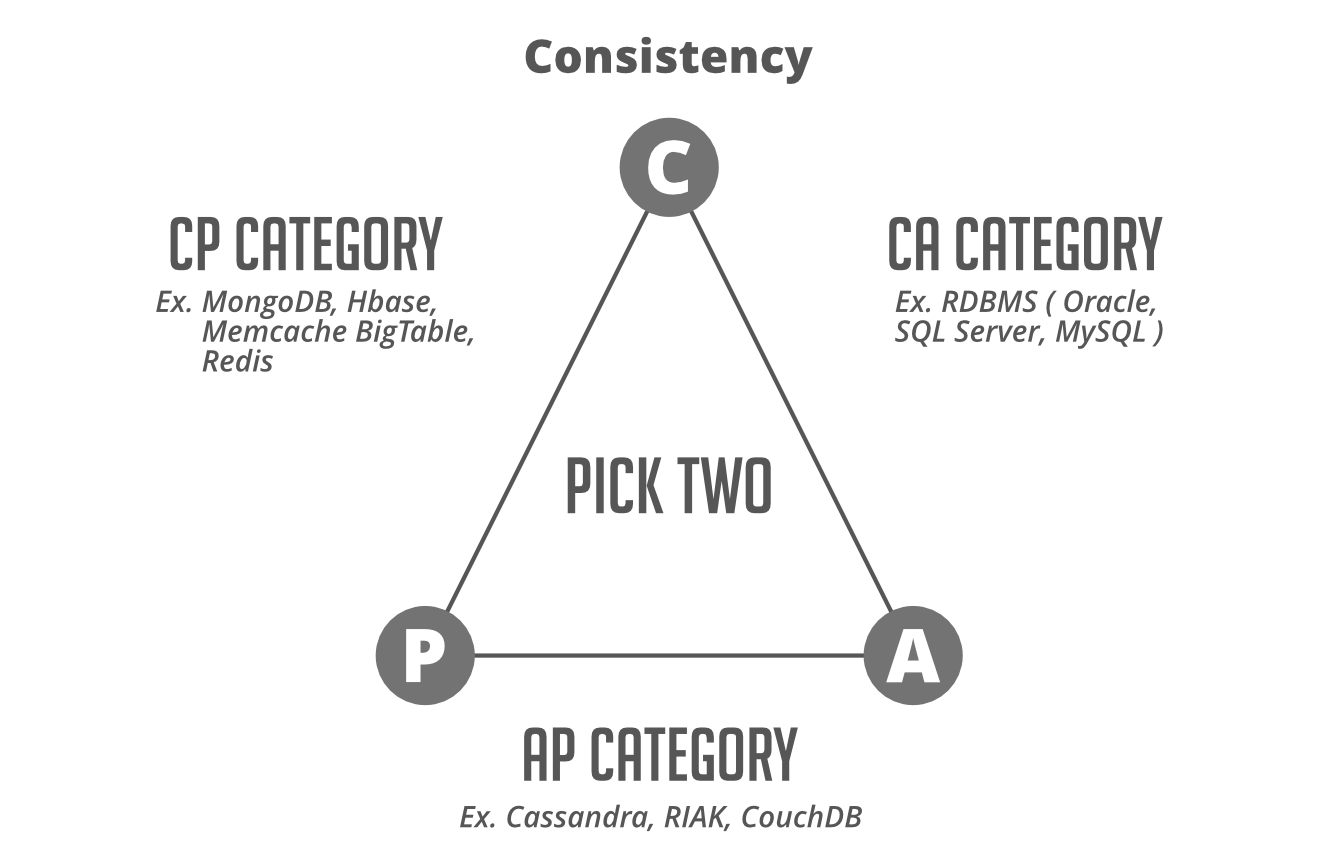
- Согласованность означает, что любой запрос на чтение вернет самую последнюю запись. Согласованность данных обычно является «сильной» для баз данных SQL, а для базы данных NoSQL согласованность может быть любой, от «возможной» до «сильной».
- Доступность означает, что неотвечающий узел должен ответить в разумные сроки. Не каждое приложение должно работать 24/7 с доступностью 99,999%, но, скорее всего, вы предпочтете базу данных с более высокой доступностью.
- Устойчивость к разделению означает, что система будет продолжать работать, несмотря на сбои сети или узла.
Помните об этой теореме CAP на собеседовании по проектированию системы. Принимайте решение в зависимости от типа заявки и ваших приоритетов. Действительно ли нормально, если ваша система выйдет из строя на несколько секунд или несколько минут, если нет, то доступность должна быть вашей главной заботой? Если вы имеете дело с чем-то с реальной транзакционной информацией, например с биржевой транзакцией или финансовыми транзакциями, вы можете превыше всего ценить согласованность. Постарайтесь выбрать технологию, которая лучше всего подходит для тех компромиссов, на которые вы хотите пойти.
Примечание. Системы CA не определены для распределенных систем. Однако в случае установки с одним узлом вы можете получить возможности CA. Кроме того, распределенные системы должны поддерживать устойчивость к разделам из-за сбоев в сети. Следовательно, вы выбираете согласованность или доступность, т. Е. Создаете систему CP или AP.
5. Базы данных
На собеседовании по проектированию системы нередко просят разработать схему базы данных о том, какие таблицы вы можете использовать? как будет выглядеть первичный ключ и каковы ваши индексы. Вам также необходимо выбрать различные типы решений для хранения данных (реляционные или нереляционные), разработанные для разных сценариев использования. Мы собираемся обсудить некоторые важные концепции баз данных, которые часто используются при проектировании систем.
- Индексирование баз данных: индексы баз данных обычно представляют собой структуру данных, которая облегчает быстрый поиск в базах данных .. но как? давайте разберемся на примере. Предположим, у вас есть таблица базы данных с 200 миллионами строк, и эта таблица используется для поиска одного или двух значений в каждой записи. Теперь, если вам нужно получить значение из определенной строки, вам нужно выполнить итерацию по таблице, что может занять много времени, особенно если это последняя запись в таблице. Мы можем использовать индексацию для такого рода проблем.
По сути, индексирование - это способ сортировки нескольких записей по нескольким полям. Когда вы добавляете индекс в таблицу на поле, он создает другую структуру данных, которая содержит значение поля и указатель на запись, к которой оно относится. Эта структура индекса затем сортируется, что позволяет выполнять двоичный поиск по ней. Если у вас есть 200 миллионов записей в таблице с именами и возрастом, и вы хотите получить списки людей, принадлежащих к возрастной группе, вам необходимо добавить индекс по атрибуту возраста в базу данных. Подробнее об этой теме читайте по ссылке Индексирование в базе данных. - Репликация: что произойдет, если ваша база данных будет обрабатывать такую большую нагрузку? В определенный момент произойдет сбой, и вся ваша система перестанет работать, потому что все запросы зависят от данных на серверах. Чтобы избежать такого рода сбоев, мы используем репликацию, которая просто означает дублирование вашей базы данных (ведущее устройство) и позволяет выполнять только операции чтения на этих репликах (ведомых устройствах) вашей базы данных. Репликация решает проблему доступности в вашей системе и обеспечивает избыточность базы данных в случае ее выхода из строя. Вы создали реплику (подчиненную) своей базы данных, но как вы извлекаете данные из исходной (главной) базы данных? как бы вы синхронизировали данные между репликами, если они предназначены для одних и тех же данных?
Вы можете выбрать синхронный (одновременно с внесением изменений в основную базу данных) или асинхронный подход в зависимости от ваших потребностей. Если это асинхронно, вам, возможно, придется принять некоторые несогласованные данные, потому что изменения в главной базе данных могут не отражаться в подчиненной базе до того, как она выйдет из строя. Если вам нужно, чтобы состояние между двумя базами данных было согласованным, репликация должна быть быстрой, и вы можете использовать синхронный подход. Также необходимо убедиться, что в случае сбоя операции записи в реплику операция записи в основную базу данных также завершится сбоем (атомарность).

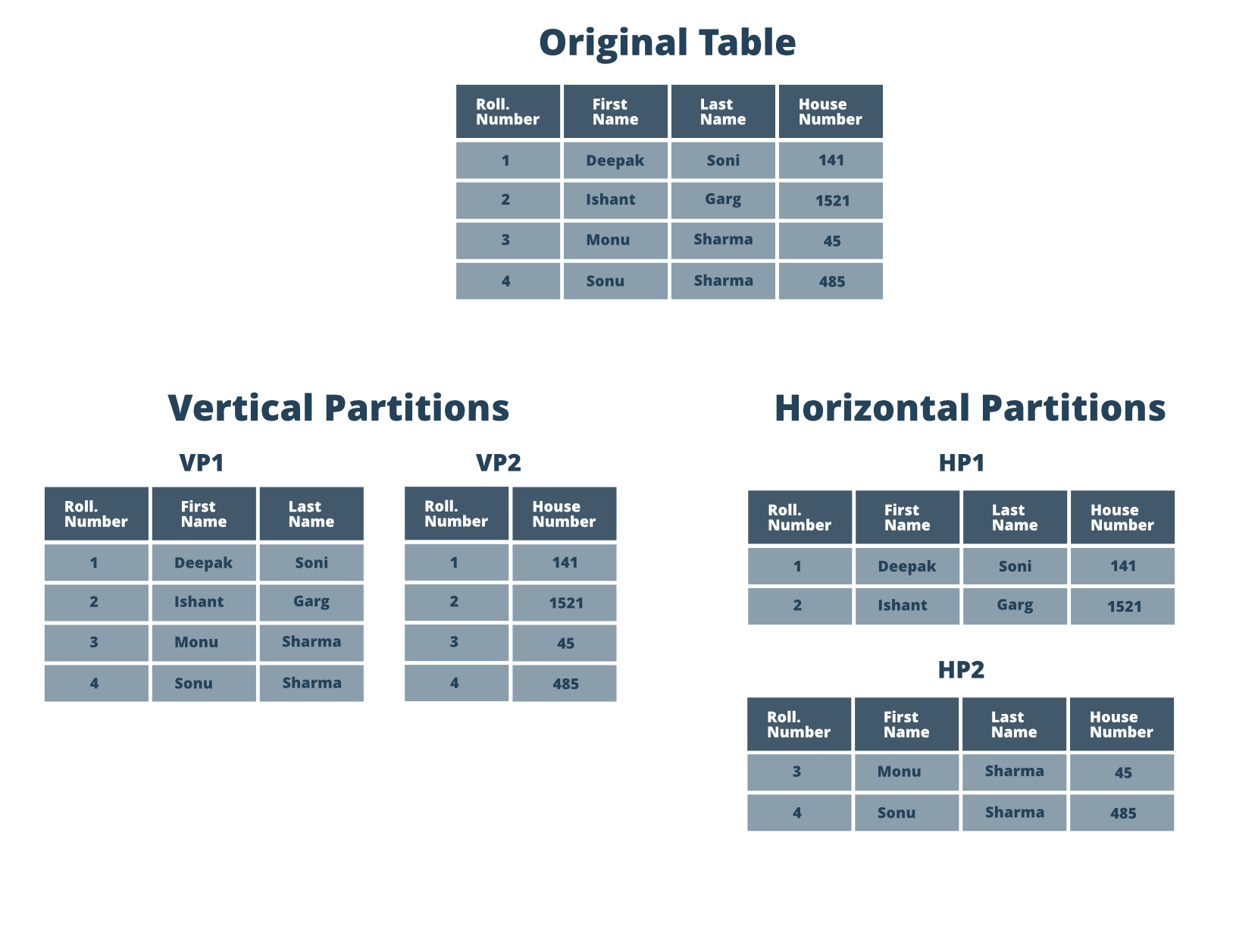
- Шардинг или разделение данных: репликация данных решает проблему доступности, но не решает проблемы с пропускной способностью и задержкой (скоростью). В таких случаях вам необходимо сегментировать вашу базу данных, что просто означает «разбиение на части» или разделение ваших записей данных и хранение этих записей на нескольких машинах. Таким образом, сегментирование данных разбивает вашу огромную базу данных на более мелкие. Возьмем пример твиттера, где выполняется много записей. Чтобы справиться с этим случаем, вы можете использовать сегментирование базы данных, когда вы разделяете базу данных на несколько основных баз данных.
Существует два основных способа сегментирования базы данных - горизонтальное и вертикальное. При вертикальном сегментировании вы берете каждую таблицу и помещаете каждую таблицу в новую машину. Итак, если у вас есть таблица пользователей, таблица твитов, таблица комментариев, таблица поддержки пользователей, то каждая из них будет на разных машинах. А что, если у вас есть одна таблица твитов, и она очень большая? В этом случае вы можете использовать горизонтальное сегментирование, когда вы берете одну таблицу и разделяете ее между несколькими машинами. Вы можете взять какой-то ключ, например ID пользователя, и разбить данные на части, а затем распределить данные по разным машинам. Таким образом, горизонтальное разделение зависит от одного ключа, который является атрибутом данных, которые вы храните для разделения данных.
Вниманию читателя! Не переставай учиться сейчас. Получите все важные концепции системного дизайна с отраслевыми экспертами. Присоединяйтесь к курсу проектирования систем, чтобы посещать живые занятия.