YOLO: You Only Look Once - Обнаружение объектов в реальном времени
YOLO был предложен Джозефом Редмондом и др. в 2015 году. Было предложено решить проблемы, с которыми сталкивались модели распознавания объектов в то время, Fast R-CNN - одна из самых современных моделей того времени, но у нее есть свои проблемы, такие как эта сеть не может использоваться в реальном времени, потому что для прогнозирования изображения требуется 2-3 секунды и, следовательно, не может использоваться в реальном времени.
Архитектура: 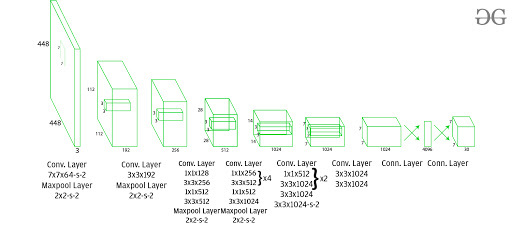
Эта архитектура принимает изображение в качестве входных данных и изменяет его размер до 448 * 448 , сохраняя то же соотношение сторон и выполняя заполнение. Затем это изображение передается в сеть CNN. Эта модель имеет 24 сверточных слоя, 4 слоя с максимальным объединением, за которыми следуют 2 полностью связанных слоя . Для уменьшения количества слоев (каналов) мы используем свертку 1 * 1 , за которой следует свертка 3 * 3. Обратите внимание, что последний слой YOLOv1 предсказывает кубический вывод. Это делается путем создания (1, 1470) из окончательного полностью связанного слоя и изменения его формы до размера (7, 7, 30) .
Эта архитектура использует Leaky ReLU в качестве функции активации во всей архитектуре, за исключением уровня, на котором используется функция линейной активации. Определение Leaky ReLU можно найти здесь. Нормализация партии также помогает упорядочить модель. С помощью пакетной нормализации мы можем удалить выпадение из модели без ее переобучения.
Обучение: ImageNet-1000 88% на ImageNet 2012 (9 вместо 24)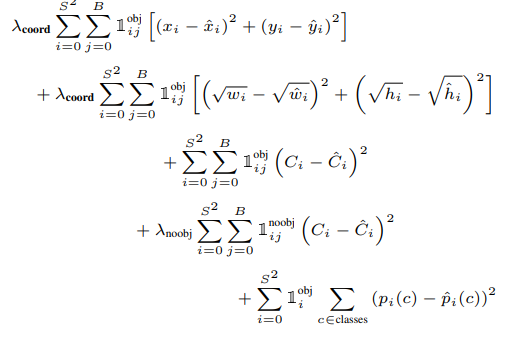
где, 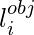 обозначает, присутствует ли объект в ячейке i .
обозначает, присутствует ли объект в ячейке i . 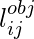 обозначает
обозначает 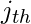 ограничивающая рамка, предназначенная для предсказания объекта в ячейке i .
ограничивающая рамка, предназначенная для предсказания объекта в ячейке i .
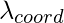 а также
а также 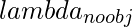 являются параметром регуляризации, необходимым для уравновешивания функции потерь.
являются параметром регуляризации, необходимым для уравновешивания функции потерь.
В этой модели мы берем 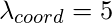 а также
а также 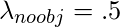
Первые две части приведенного выше уравнения потерь представляют собой среднеквадратичную ошибку локализации, а остальные три части представляют ошибку классификации. В ошибке локализации первый член вычисляет отклонение от ограничивающей рамки наземной истины. Второй член вычисляет квадратный корень из разницы между высотой и шириной ограничивающей рамки. Во втором члене мы извлекаем квадратный корень из ширины и высоты, потому что наша функция потерь должна учитывать отклонение с точки зрения размера ограничивающего прямоугольника. Для маленьких ограничивающих рамок небольшое отклонение должно быть более важным по сравнению с большими ограничивающими рамками.
Потеря классификации состоит из трех членов, первый член вычисляет сумму квадратов ошибок между прогнозируемой оценкой достоверности и основной истинностью для каждого ограничивающего прямоугольника в каждой ячейке. Точно так же второй член вычисляет среднеквадратичную сумму ячеек, которые не содержат ограничивающего прямоугольника, и параметр регуляризации используется, чтобы уменьшить эту потерю. Третий член вычисляет сумму квадратов ошибок классов, принадлежащих этим ячейкам сетки.
Обнаружение:
Эта архитектура делит изображение на сетку размером S * S. Если центр ограничивающей рамки объекта находится в этой сетке, то эта сетка отвечает за обнаружение этого объекта. Каждая сетка предсказывает ограничивающие прямоугольники с их оценкой достоверности. Каждая оценка достоверности показывает, насколько точно прогнозируемая граница содержит объект и насколько точно прогнозируются координаты ограничивающей рамки относительно. предсказание наземной истины.
Изображение YOLO (разделено на сетку S * S)
Во время тестирования мы умножаем условные вероятности классов и прогнозы достоверности отдельных ящиков. Мы определяем нашу оценку уверенности следующим образом:
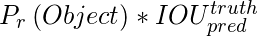
Обратите внимание: оценка достоверности должна быть равна 0, если в сетке нет объекта. Если на изображении присутствует объект, показатель достоверности должен быть равен IoU между полями истинности и предсказанными полями. Каждый ограничивающий прямоугольник состоит из 5 прогнозов: (x, y, w, h) и оценки достоверности. Координаты (x, y) представляют центр прямоугольника относительно границ ячейки сетки. Координаты h, w представляют высоту и ширину ограничивающего прямоугольника относительно (x, y) . Оценка достоверности представляет присутствие объекта в ограничивающей рамке.
YOLO single Grid Bounding box-Box
Это приводит к подобной комбинации ограничивающих рамок из каждой сетки.
Комбинация ограничивающего прямоугольника YOLO
Каждая сетка также предсказывает вероятность условного класса C, P r (Class i | Object).
Карта условной вероятности YOLO
Эта вероятность была условной, исходя из наличия объекта в ячейке сетки. Независимо от количества ячеек каждая ячейка сетки предсказывает только один набор вероятностей класса. Это предсказание кодируется в трехмерном тензоре размера S * S * (5 * B + C).
Теперь мы умножаем условные вероятности классов и прогнозы уверенности отдельных ящиков,
Карта функций вывода YOLO
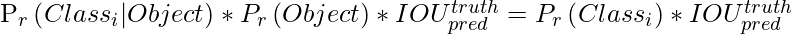
Результат теста YOLO
что дает нам оценки достоверности для каждого класса. Эти оценки кодируют как вероятность появления этого класса в поле, так и то, насколько хорошо предсказанное поле соответствует объекту. Затем, после того как мы применим немаксимальное подавление, чтобы предсказать окончательный результат ввода
YOLO очень быстр во время тестирования, потому что он использует только одну архитектуру CNN для прогнозирования результатов, а класс определяется таким образом, что он рассматривает классификацию как проблему регрессии.
Полученные результаты:
Простой YOLO имеет карту 63,4% при обучении на VOC 2007 и 2012, быстрый YOLO, который почти в 3 раза быстрее по генерации результатов, имеет карту 52%. Это ниже, чем у лучшей полученной модели Fast R-CNN (71% mAP), а также достигнутого R-CNN (66% mAP) . Однако он превосходит другие детекторы реального времени, такие как (DPMv5 33% mAP) по точности.
Преимущества YOLO:
- Обрабатывайте кадры со скоростью от 45 кадров в секунду (большая сеть) до 150 кадров в секунду (меньшая сеть), что лучше, чем в режиме реального времени.
- Сеть способна лучше обобщать изображение.
Недостатки YOLO:
- Сравнительно низкий уровень отзыва и большая ошибка локализации по сравнению с Faster R_CNN.
- С трудом обнаруживает близкие объекты, поскольку каждая сетка может предлагать только 2 ограничивающих прямоугольника.
- С трудом обнаруживает мелкие предметы.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.