Введение в структуры данных
ЧТО ТАКОЕ ДАННЫЕ:
Данные — это набор различных чисел, символов и алфавитов для представления информации.
ЧТО ТАКОЕ СТРУКТУРА ДАННЫХ:
Структура данных — это группа элементов данных, обеспечивающая самый простой способ хранения и выполнения различных действий с данными компьютера. Структура данных — это особый способ организации данных в компьютере, обеспечивающий их эффективное использование. Идея состоит в том, чтобы уменьшить пространственную и временную сложность различных задач.
Выбор хорошей структуры данных позволяет эффективно выполнять множество критических операций. Эффективная структура данных также требует минимального объема памяти и времени выполнения для обработки структуры.
Структура данных также определила экземпляр ADT.ADT означает АБСТРАКТНЫЙ ТИП ДАННЫХ . Формально он определяется как триплет.[ D,F,A]
- D : Набор домена.
- F : набор операций.
- А : набор аксиом.
Тип структуры данных:
- Линейная структура данных
- Нелинейная структура данных.
Линейная структура данных:
- Элементы расположены в одном измерении, также известном как линейное измерение.
- Пример: списки, стек, очередь и т. д.
Нелинейная структура данных
- Элементы располагаются в измерениях один-многие, многие-один и многие-многие.
- Пример: дерево, график, таблица и т. д.
Структуры данных используются в различных областях, таких как:
- Операционная система
- Графика
- Компьютерный дизайн
- Блокчейн
- Генетика
- Обработка изображений
- Моделирование и т.д.
DSA – Self Paced Course
Advance your Software Engineering career by learning data structure and algorithms with GeeksforGeek’s most popular DSA course, curated by industry experts to help you get prepared for technical SDE interviews with top-notch companies like Amazon, Microsoft, Adobe and other top product-based giants. Master all the key topics of DSA like sorting, DP, searching, trees and more. Enrol now!
Ниже приведен обзор некоторых популярных структур данных:
1. Массив . Массив представляет собой набор элементов данных, хранящихся в смежных ячейках памяти. Идея состоит в том, чтобы хранить несколько элементов одного типа вместе. Это упрощает вычисление положения каждого элемента, просто добавляя смещение к базовому значению, т. е. местонахождению в памяти первого элемента массива (обычно обозначается именем массива).

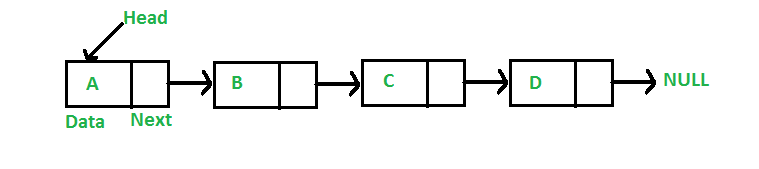
2. Связанные списки . Как и массивы, связанный список представляет собой линейную структуру данных. В отличие от массивов элементы связанного списка не хранятся в непрерывном месте; элементы связаны с помощью указателей.
3. Стек . Стек — это линейная структура данных, которая следует определенному порядку выполнения операций. Порядок может быть LIFO (последним пришел, первым ушел) или FILO (первый пришел последним). В стеке все операции вставки и удаления разрешены только на одном конце списка.

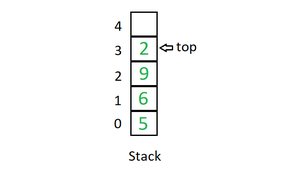
В основном в стеке выполняются следующие три основные операции:
- Initialize : сделать стек пустым.
- Push: добавляет элемент в стек. Если стек заполнен, говорят, что это состояние переполнения.
- Pop: Удаляет элемент из стека. Элементы извлекаются в порядке, обратном их перемещению. Если стек пуст, говорят, что это состояние Underflow.
- Peek or Top: возвращает верхний элемент стека.
- isEmpty: возвращает true, если стек пуст, иначе false.
4. Очередь . Как и стек, очередь представляет собой линейную структуру, которая следует определенному порядку выполнения операций. Порядок — «первым пришел — первым обслужен» (FIFO). В очередь элементы вставляются с одного конца и удаляются с другого конца. Хорошим примером очереди является любая очередь потребителей ресурса, в которой потребитель, пришедший первым, обслуживается первым. Разница между стеками и очередями заключается в удалении. В стеке мы удаляем последний добавленный элемент; в очереди мы удаляем элемент, добавленный последним.

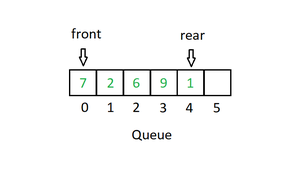
В основном над очередью выполняются следующие четыре основные операции:
- Enqueue: Добавляет элемент в очередь. Если очередь заполнена, то говорят, что это состояние переполнения.
- Dequeue: удаляет элемент из очереди. Элементы выталкиваются в том же порядке, в котором они выдвигаются. Если очередь пуста, говорят, что это состояние Underflow.
- Спереди: получить передний элемент из очереди.
- Сзади: получить последний элемент из очереди.
5. Двоичное дерево . В отличие от массивов, связанных списков, стека и очередей, которые представляют собой линейные структуры данных, деревья представляют собой иерархические структуры данных. Двоичное дерево — это древовидная структура данных, в которой каждый узел имеет не более двух дочерних элементов, которые называются левым дочерним элементом и правым дочерним элементом. Реализуется в основном с помощью Links.
Двоичное дерево представлено указателем на самый верхний узел в дереве. Если дерево пусто, то значение root равно NULL. Узел двоичного дерева содержит следующие части.
1. Data 2. Pointer to left child 3. Pointer to the right child
6. Двоичное дерево поиска. Двоичное дерево поиска — это двоичное дерево со следующими дополнительными свойствами:
- Левая часть корневого узла содержит меньше ключей, чем ключ корневого узла.
- Правая часть корневого узла содержит ключи, большие, чем ключ корневого узла.
- В двоичном дереве нет повторяющихся ключей.
Бинарное дерево, имеющее следующие свойства, известно как бинарное дерево поиска (BST).
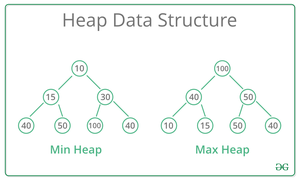
7. Куча . Куча — это специальная структура данных на основе дерева, в которой дерево является полным двоичным деревом. Как правило, кучи могут быть двух типов:
- Max-Heap: в Max-Heap ключ, присутствующий в корневом узле, должен быть наибольшим среди ключей, присутствующих во всех его дочерних узлах. Одно и то же свойство должно быть рекурсивно истинным для всех поддеревьев в этом двоичном дереве.
- Min-Heap: в Min-Heap ключ, присутствующий в корневом узле, должен быть минимальным среди ключей, присутствующих во всех его дочерних элементах. Одно и то же свойство должно быть рекурсивно истинным для всех поддеревьев в этом двоичном дереве.
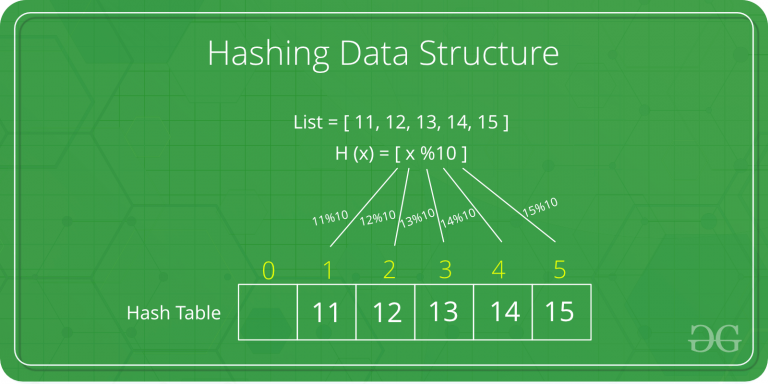
8. Хеширование структуры данных. Хеширование — это важная структура данных, предназначенная для использования специальной функции, называемой хеш-функцией, которая используется для сопоставления заданного значения с определенным ключом для более быстрого доступа к элементам. Эффективность отображения зависит от эффективности используемой хеш-функции.
Пусть хэш-функция H(x) сопоставляет значение x с индексом x%10 в массиве. Например, если список значений равен [11, 12, 13, 14, 15], он будет храниться в позициях {1, 2, 3, 4, 5} в массиве или хеш-таблице соответственно.
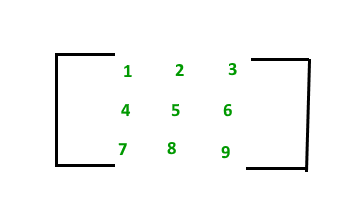
9. Матрица . Матрица представляет собой набор чисел, расположенных в порядке строк и столбцов. Элементы матрицы необходимо заключать в круглые скобки или скобки.
Ниже показана матрица из 9 элементов.
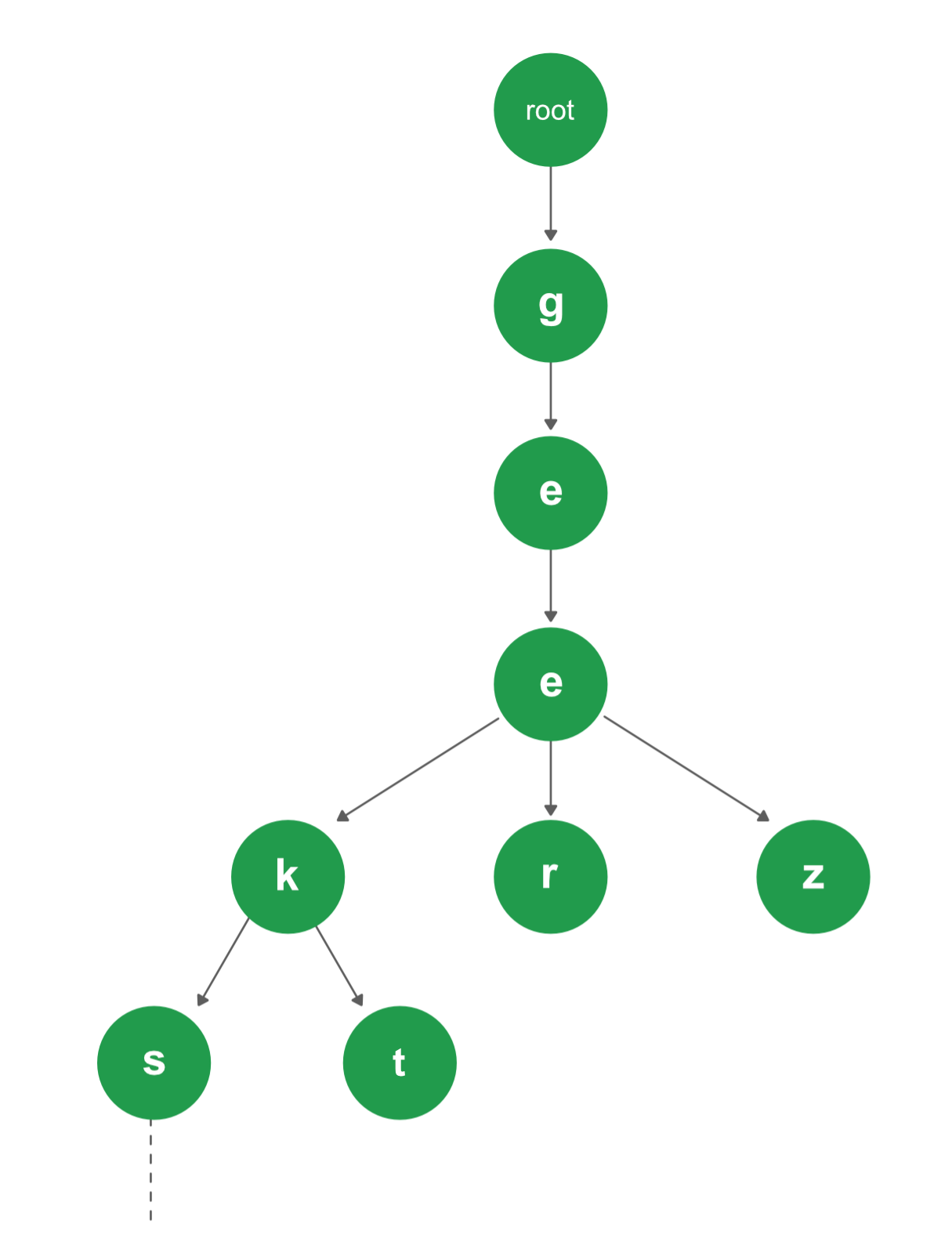
10. Trie : Trie — это эффективная структура данных Trie val для получения информации. Используя Trie, сложность поиска можно довести до оптимального предела (длина ключа). Если мы храним ключи в бинарном дереве поиска, для хорошо сбалансированного BST потребуется время, пропорциональное M * log N, где M — максимальная длина строки, а N — количество ключей в дереве. Используя Trie, мы можем искать ключ за время O(M). Однако штраф связан с требованиями к хранилищу Trie.