Введение в опорные векторные машины (SVM)
Что такое машины опорных векторов?
Машина опорных векторов (SVM) - это относительно простой алгоритм машинного обучения с учителем, используемый для классификации и / или регрессии. Он более предпочтителен для классификации, но иногда также очень полезен для регрессии. По сути, SVM находит гиперплоскость, которая создает границу между типами данных. В двумерном пространстве эта гиперплоскость представляет собой не что иное, как линию.
В SVM мы отображаем каждый элемент данных в наборе данных в N-мерном пространстве, где N - количество функций / атрибутов в данных. Затем найдите оптимальную гиперплоскость для разделения данных. Таким образом, вы должны понимать, что по своей сути SVM может выполнять только двоичную классификацию (т. Е. Выбирать между двумя классами). Однако есть различные методы, которые можно использовать для решения мультиклассовых задач.
Машина опорных векторов для задач с несколькими классами
Чтобы выполнить SVM на мультиклассовых задачах, мы можем создать двоичный классификатор для каждого класса данных. Два результата каждого классификатора будут:
- Точка данных принадлежит этому классу ИЛИ
- Точка данных не принадлежит к этому классу.
Например, в классе фруктов для выполнения мультиклассовой классификации мы можем создать двоичный классификатор для каждого фрукта. Например, класс «манго» будет иметь двоичный классификатор, чтобы предсказать, ЯВЛЯЕТСЯ ли он манго ИЛИ это НЕ манго. Классификатор с наивысшим баллом выбирается как результат SVM.
SVM для сложных (нелинейно разделимых)
SVM очень хорошо работает без каких-либо модификаций для линейно разделимых данных. Линейно разделяемые данные - это любые данные, которые могут быть нанесены на график и могут быть разделены на классы с помощью прямой линии.
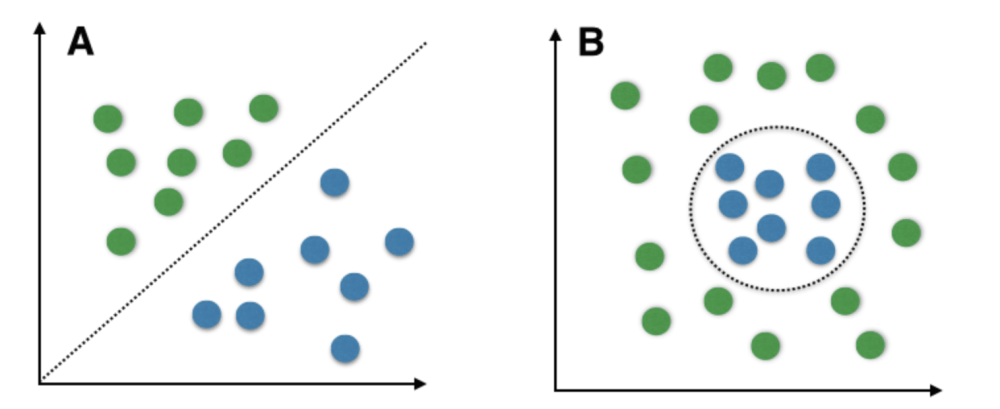
A: линейно разделяемые данные B: нелинейно разделяемые данные
Мы используем Kernelized SVM для нелинейно разделяемых данных. Скажем, у нас есть некоторые нелинейно разделимые данные в одном измерении. Мы можем преобразовать эти данные в двумерные, и данные станут линейно разделенными в двух измерениях. Это делается путем сопоставления каждой одномерной точки данных с соответствующей двумерной упорядоченной парой.
Таким образом, для любых нелинейно разделяемых данных в любом измерении мы можем просто отобразить данные в более высокое измерение, а затем сделать их линейно разделяемыми. Это очень мощная и общая трансформация.
Ядро - это не что иное, как мера сходства между точками данных. Функция ядра в SVM с ядром сообщает вам, что с учетом двух точек данных в исходном пространстве функций, каково сходство между точками во вновь преобразованном пространстве функций.
Доступны различные функции ядра, но две из них очень популярны:
- Ядро радиальной базисной функции (RBF): Сходство между двумя точками в преобразованном пространстве признаков является экспоненциально убывающей функцией расстояния между векторами и исходным пространством ввода, как показано ниже. RBF - это ядро по умолчанию, используемое в SVM.
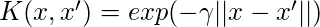
- Полиномиальное ядро: Полиномиальное ядро принимает дополнительный параметр, «степень», который контролирует сложность модели и вычислительные затраты на преобразование.
Очень интересным фактом является то, что SVM на самом деле не должна выполнять это фактическое преобразование точек данных в новое многомерное пространство функций. Это называется трюком с ядром.
Уловка ядра:
Внутри ядра SVM может вычислять эти сложные преобразования только в терминах вычислений подобия между парами точек в пространстве признаков более высокой размерности, где преобразованное представление признаков является неявным.
Эта функция подобия, которая математически представляет собой своего рода сложное скалярное произведение, на самом деле является ядром SVM с ядром. Это делает практичным применение SVM, когда базовое пространство функций является сложным или даже бесконечномерным. Сам трюк с ядром довольно сложен и выходит за рамки этой статьи.
Важные параметры в ядре SVC (классификатор опорных векторов)
- Ядро : ядро выбирается на основе типа данных, а также типа преобразования. По умолчанию ядром является ядро радиальной базовой функции (RBF).
- Гамма : этот параметр определяет, насколько сильно влияние одного обучающего примера достигает во время преобразования, что, в свою очередь, влияет на то, насколько тесно границы решения заканчиваются окружающими точками во входном пространстве. Если значение гаммы невелико, точки, расположенные дальше друг от друга, считаются похожими. Таким образом, больше точек сгруппированы вместе и имеют более плавные границы принятия решения (могут быть менее точными). Большие значения гаммы приводят к тому, что точки располагаются ближе друг к другу (может вызвать переоснащение).
- Параметр «C» : этот параметр управляет степенью регуляризации, применяемой к данным. Большие значения C означают низкую регуляризацию, что, в свою очередь, приводит к очень хорошему соответствию обучающих данных (может вызвать переобучение). Более низкие значения C означают более высокую регуляризацию, что делает модель более терпимой к ошибкам (может привести к более низкой точности).
Плюсы Kernelized SVM:
- Они очень хорошо работают с различными наборами данных.
- Они универсальны: можно указать различные функции ядра или определить собственные ядра для определенных типов данных.
- Они хорошо работают как с данными высокой, так и с низкой размерностью.
Минусы Kernelized SVM:
- Эффективность (время работы и использование памяти) уменьшается по мере увеличения размера обучающей выборки.
- Требуется тщательная нормализация входных данных и настройка параметров.
- Не обеспечивает прямой оценки вероятности.
- Трудно объяснить, почему был сделан прогноз.
ЗАКЛЮЧЕНИЕ
Теперь, когда вы знаете основы работы SVM, вы можете перейти по следующей ссылке, чтобы узнать, как реализовать SVM для классификации элементов с помощью Python:
https://www.geeksforgeeks.org/classifying-data-using-support-vector-machinessvms-in-python/
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.