Введение в классификацию MultiLabel
Одной из наиболее часто используемых возможностей контролируемых методов машинного обучения является классификация контента, используемая во многих контекстах, например, определение положительного или отрицательного отзыва о ресторане или предположение о том, есть ли на изображении кошка или собака. Эту задачу можно разделить на три области: двоичную классификацию, многоклассовую классификацию и многозначную классификацию. В этой статье мы собираемся объяснить эти типы классификации и почему они отличаются друг от друга, а также покажем реальный сценарий, в котором можно использовать многозначную классификацию.
Различия между видами классификаций
- Бинарная классификация:
Он используется, когда существует только два различных класса и данные, которые мы хотим классифицировать, принадлежат исключительно к одному из этих классов, например, чтобы классифицировать сообщение о данном продукте как положительное или отрицательное; - Мультиклассовая классификация: используется, когда существует три или более классов и данные, которые мы хотим классифицировать, принадлежат исключительно к одному из этих классов, например, чтобы классифицировать, является ли семафор на изображении красным, желтым или зеленым;
- Классификация по разным ярлыкам:
Он используется, когда существует два или более классов, и данные, которые мы хотим классифицировать, могут принадлежать ни одному из классов или всем им одновременно, например, для классификации дорожных знаков, содержащихся на изображении.
Реальный сценарий многокомпонентной классификации
Проблема, которую мы рассмотрим в этом руководстве, - это извлечение аспекта отзывов о ресторанах из твиттера. В этом контексте автор текста может не упомянуть ни один или все аспекты заранее заданного списка, в нашем случае этот список состоит из пяти аспектов: обслуживание, еда, анекдоты, цена и атмосфера. Для обучения модели мы собираемся использовать набор данных, первоначально предложенный для конкурса в 2014 году на Международном семинаре по семантической оценке, он известен как SemEval-2014 и содержит данные об аспектах текста и его соответствующих полярностях для этого руководства. мы используем только данные об аспектах, более подробную информацию об исходном конкурсе и его данных можно найти на их сайте.
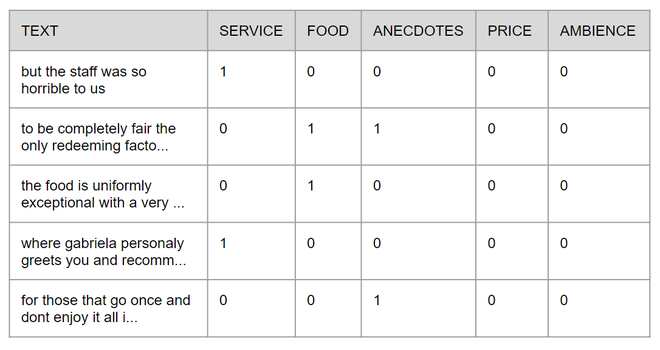
Для простоты в этом руководстве исходный файл XML был преобразован в файл CSV, который будет доступен на GitHub с полным кодом. Каждая строка состоит из текста и содержащихся в нем аспектов, наличие или отсутствие этих аспектов обозначается цифрами 1 и 0 соответственно, изображение ниже показывает, как выглядит таблица.
Первое, что нам нужно сделать, это импортировать необходимые библиотеки, все они находятся в фрагменте кода ниже, если вы знакомы с машинным обучением, вы, вероятно, узнаете некоторые из них.
Код: импорт библиотек
import pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.feature_extraction.text import TfidfVectorizerfrom skmultilearn.adapt import MLkNNfrom sklearn.metrics import hamming_loss, accuracy_score |
После этого мы должны импортировать тексты и правильно разделить их, чтобы обучить модель, однако сам необработанный текст не имеет большого значения для алгоритмов машинного обучения, по этой причине мы должны представлять их по-другому, их много различные формы для представления текста, здесь мы будем использовать простой, но очень мощный метод под названием TF-IDF, который расшифровывается как Term Frequency - Inverse Document Frequency, в двух словах, он используется для представления важности каждого слова внутри текстового корпуса, вы можете найти более подробную информацию о TF-IDF в этой невероятной статье. В приведенном ниже коде мы назначим набор текстов X и аспекты, содержащиеся в каждом тексте, y, чтобы преобразовать данные из текста строки в TF-IDF, мы создадим экземпляр класса TfidfVectorizer, используя функцию fit чтобы предоставить ему полный набор текстов, чтобы позже мы могли использовать этот класс для преобразования разделенных наборов, и, наконец, мы разделим данные между обучающими и тестовыми данными, используя 70% данных для обучения и оставив остальные для тестирования окончательную модель и преобразуйте каждый из этих наборов, используя преобразование функции из экземпляра TfidfVectorizer, который мы создали ранее.
Код:
aspects_df = pd.read_csv( 'semeval2014.csv' )X = aspects_df[ "text" ]y = np.asarray(aspects_df[aspects_df.columns[ 1 :]]) # initializing TfidfVectorizervetorizar = TfidfVectorizer(max_features = 3000 , max_df = 0.85 )# fitting the tf-idf on the given datavetorizar.fit(X) # splitting the data to training and testing data setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.30 , random_state = 42 ) # transforming the dataX_train_tfidf = vetorizar.transform(X_train)X_test_tfidf = vetorizar.transform(X_test) |
Теперь все настроено, и мы можем создать экземпляр модели и обучить ее! Для выполнения классификации по нескольким меткам можно использовать несколько подходов, одним из которых будет MLKnn, который является адаптацией известного алгоритма Knn, точно так же, как его предшественник MLKnn определяет классы цели на основе расстояния между ней и данными из учебная база, но при условии, что она может принадлежать ни к одному классу или ко всем классам.
Код:
# using Multi-label kNN classifiermlknn_classifier = MLkNN()mlknn_classifier.fit(X_train_tfidf, y_train) |
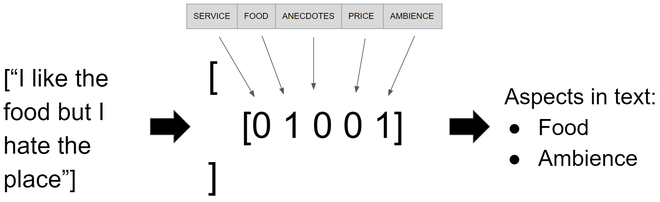
После обучения модели мы можем запустить небольшой тест и увидеть, как она работает с любым предложением. Я буду использовать предложение « Мне нравится еда, но я ненавижу это место», но не стесняйтесь использовать любые предложения, которые вам нравятся. Как и в случае с обучающими и тестовыми данными, нам нужно преобразовать вектор новых предложений в TF-IDF и после этого использовать функцию прогнозирования из экземпляра модели, которая предоставит нам разреженную матрицу, которую можно преобразовать в массив с функция toarray, возвращающая массив массивов, где каждый элемент в каждом массиве предполагает наличие аспекта, как показано на изображении 2.
Код:
new_sentences = [ "I like the food but I hate the place" ]new_sentence_tfidf = vetorizar.transform(new_sentences) predicted_sentences = mlknn_classifier.predict(new_sentence_tfidf)print (predicted_sentences.toarray()) |
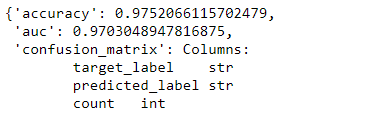
Теперь нам нужно выполнить одну из самых важных частей конвейера машинного обучения - тестирование. В этой части есть некоторые существенные отличия от мультиклассовых задач, например, мы не можем использовать точность таким же образом, потому что одно единственное предсказание подразумевает множество классов одновременно, как в гипотетическом сценарии, показанном на изображении 3, обратите внимание, что при использовании точности только предсказания, которые в точности равны истинным меткам, считаются правильным предсказанием, таким образом, точность составляет 0,25, что означает, что если вы пытаетесь предсказать аспекты 100 предложений только в 25 из них, наличие и отсутствие всех аспекты будут правильно предсказаны в то же время.
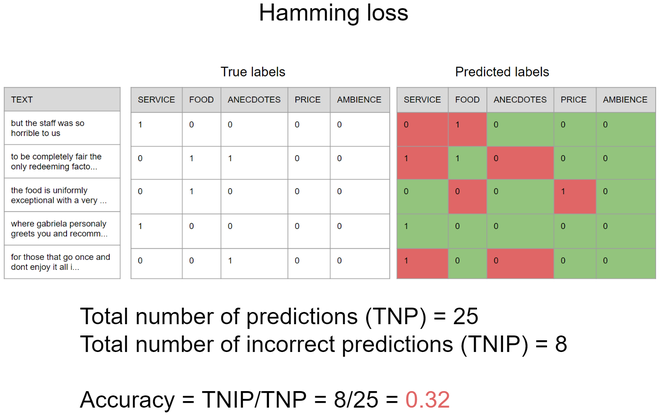
С другой стороны, есть более подходящая метрика, которая может использоваться для измерения того, насколько хорошо модель предсказывает наличие каждого аспекта независимо, эта метрика называется потерями Хэмминга, и она равна количеству неверных предсказаний, деленному на общее количество прогнозов, где выходные данные модели могут содержать один или несколько прогнозов, следующее изображение, которое использует тот же сценарий, что и последний пример, иллюстрирует, как это работает, важно отметить, что маловероятная точность в потере Хэмминга, чем меньше результат тем лучше модель. Таким образом, потеря Хэмминга в данном случае составляет 0,32, что означает, что если вы пытаетесь предсказать аспекты 100 предложений, модель неверно предскажет около 32% независимых аспектов.
Хотя вторая метрика кажется более подходящей для подобных задач, важно помнить, что все проблемы машинного обучения отличаются друг от друга, поэтому каждая из них может комбинировать разные наборы метрик, чтобы лучше понять производительность модели, как всегда. , нет серебряной пули. Чтобы использовать их, мы собираемся использовать модуль метрик из sklearn, который берет прогноз, выполненный моделью с использованием тестовых данных, и сравнивает с истинными метками.
Код:
predicted = mlknn_classifier.predict(X_test_tfidf) print (accuracy_score(y_test, predicted))print (hamming_loss(y_test, predicted)) |
Так что теперь, если все в порядке с точностью около 0,47 и потерей Хэмминга около 0,16 !
Внимание компьютерщик! Укрепите свои основы с помощью Базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.