Удаление файлов в HDFS с помощью Python Snakebite
Предварительное условие: установка Hadoop, HDFS
Python Snakebite - очень популярная библиотека Python, которую мы можем использовать для связи с HDFS. Используя клиентскую библиотеку Python, предоставляемую пакетом Snakebite, мы можем легко написать код Python, работающий в HDFS. Он использует сообщения protobuf для прямой связи с NameNode. Клиентская библиотека python напрямую работает с HDFS без системного вызова hdfs dfs. Snakebite не поддерживает python3 .
Удаление файлов и каталогов
В Python Snakebite есть метод с именем delete (), с помощью которого мы можем легко удалить несколько файлов или каталогов, доступных в нашей HDFS. Мы будем использовать клиентскую библиотеку Python для выполнения удаления. Итак, начнем с практического использования.
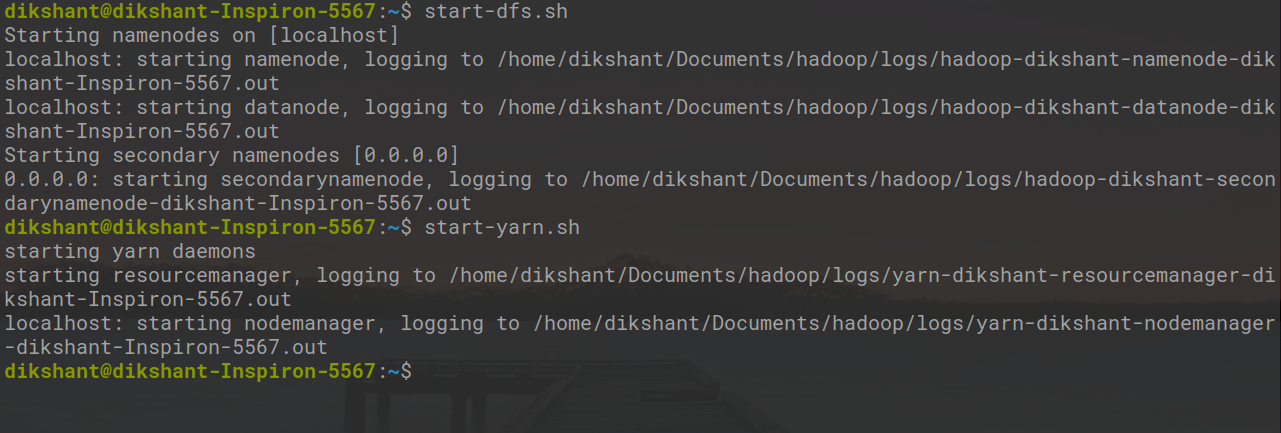
Все демоны Hadoop должны быть запущены. Вы можете запустить демоны Hadoop с помощью следующей команды.
start-dfs.sh // start your namenode datanode and secondary namenode start-yarn.sh // start resourcemanager and nodemanager
Задача: Рекурсивное удаление файлов и каталогов, доступных в HDFS (в моем случае я удаляю каталоги «/ demo / demo1» и «/ demo2»).
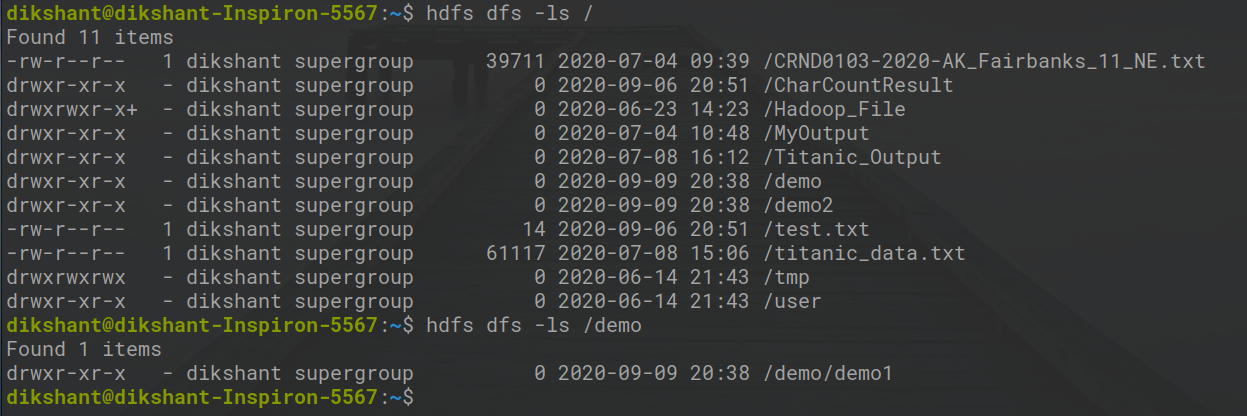
Шаг 1: Давайте посмотрим на файлы и каталог, доступные в HDFS, с помощью приведенной ниже команды.
hdfs dfs -ls /
В приведенной выше команде hdfs dfs используется, в частности, для связи с распределенной файловой системой Hadoop. ' -ls /' используется для вывода списка файлов, находящихся в корневом каталоге. Мы также можем вручную проверить файлы, доступные в HDFS.
Шаг 2: Создайте файл в вашем локальном каталоге с именем remove_directory.py в желаемом месте.
cd Documents / # Изменение каталога на документы (вы можете выбрать в соответствии с вашими требованиями) touch remove_directory.py # команда touch используется для создания файла в среде Linux.

Шаг 3. Напишите приведенный ниже код в файл python remove_directory.py.
Python
# importing the packagefrom snakebite.client import Client # the below line create client connection to the HDFS NameNodeclient = Client("localhost", 9000) # The /demo/demo1 and /demo2 directory"s will be removed from HDFS for p in client.delete(["/demo", "/demo2"], recurse=True): print p |
В приведенной выше программе recurse = True указано, что каталог будет удален рекурсивно, что означает, что если каталог не пуст и содержит некоторые подкаталоги, эти подкаталоги также будут удалены. В нашем случае сначала будет удален / demo1, затем будет удален каталог / demo.
Описание метода Client ():
Метод Client () может принимать все перечисленные ниже аргументы:
- host (строка): IP-адрес NameNode.
- port (int): RPC-порт Namenode.
- hadoop_version (int): версия протокола Hadoop (по умолчанию: 9)
- use_trash (логическое): использовать корзину при удалении файлов.
- Effective_use (строка): эффективный пользователь для операций HDFS (пользователь по умолчанию - текущий пользователь).

В случае, если имя файла, которое мы указываем, не будет найдено, метод delete () выдаст исключение FileNotFoundException . Если каталог содержит какой-либо подкаталог, а рекурсивный = True не упоминается, DirectoryException будет сгенерирован методом delete ().
Шаг 4: Запустите файл remove_directory.py и посмотрите на результат.
python remove_directory.py // это рекурсивно удалит каталог, как указано в аргументе delete ()

На изображении выше «результат»: True означает, что мы успешно удалили каталог.
Шаг 5: Мы можем проверить, удалены ли каталоги или нет, либо вручную, либо с помощью приведенной ниже команды.
hdfs dfs -ls /
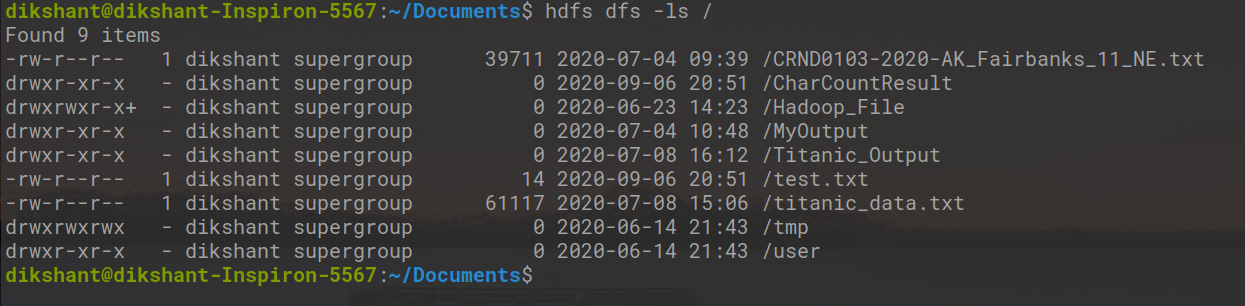
Теперь мы видим, что / demo и / demo2 больше не доступны в HDFS.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.