Стратегия One-vs-Rest для мультиклассовой классификации
Предварительное условие: начало работы с классификацией /
Классификация, пожалуй, самая распространенная задача машинного обучения. Прежде чем мы перейдем к тому, что такое классификаторы One-vs-Rest (OVR) и как они работают, вы можете перейти по ссылке ниже и получить краткий обзор того, что такое классификация и чем она полезна.
В общем, существует два типа алгоритмов классификации:
- Алгоритмы двоичной классификации.
- Алгоритмы многоклассовой классификации.
Бинарная классификация - это когда мы должны классифицировать объекты на две группы. Обычно эти две группы состоят из «Истина» и «Ложь». Например, с учетом определенного набора характеристик здоровья задача двоичной классификации может заключаться в том, чтобы определить, болен ли человек диабетом или нет.
С другой стороны, в мультиклассовой классификации существует более двух классов. Например, с учетом набора атрибутов фруктов, таких как форма и цвет, задача классификации по нескольким классам будет заключаться в определении типа фруктов.
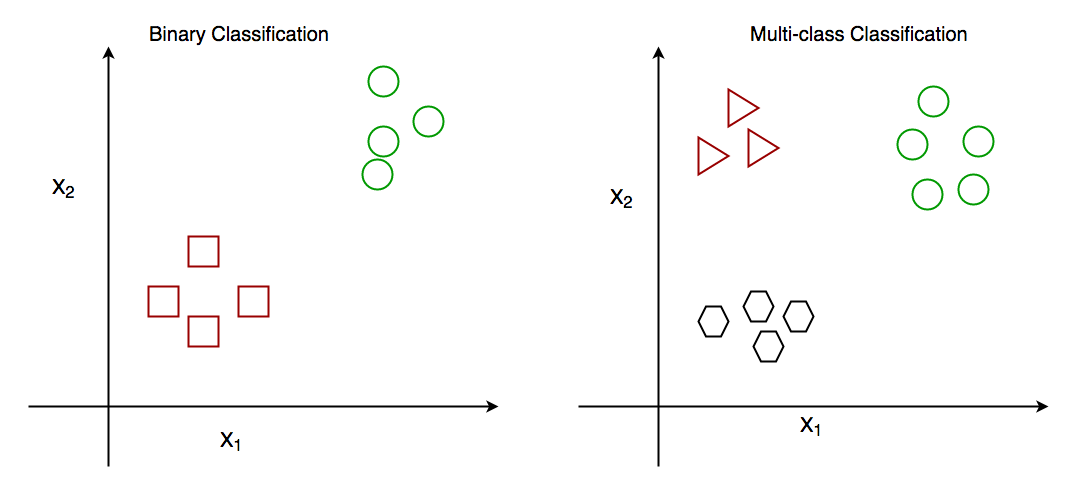
Итак, теперь, когда у вас есть представление о том, как работают двоичная и мультиклассовая классификация, давайте перейдем к использованию эвристического метода one-vs-rest.
Метод One-vs-Rest (OVR) :
Многие популярные алгоритмы классификации изначально были разработаны для задач двоичной классификации. Эти алгоритмы включают:
- Логистическая регрессия
- Машины опорных векторов (SVM)
- Модели персептронов
и многое другое.
Таким образом, эти популярные алгоритмы классификации нельзя напрямую использовать для задач классификации нескольких классов. Доступны некоторые эвристические методы, которые могут разбить задачи многоклассовой классификации на множество различных задач двоичной классификации. Чтобы понять, как это работает, давайте рассмотрим пример : скажем, задача классификации состоит в том, чтобы разделить различные фрукты на три типа фруктов: банан, апельсин или яблоко. Теперь это явно проблема классификации нескольких классов. Если вы хотите использовать алгоритм двоичной классификации, например, SVM. Ниже показано, как с этим справиться метод One-vs-Rest:
Поскольку в задаче классификации существует три класса, метод One-vs-Rest разделит эту проблему на три задачи двоичной классификации:
- Проблема 1. Банан или [Апельсин, Яблоко]
- Проблема 2: апельсин против [банана, яблока]
- Проблема 3: Apple против [банана, апельсина]
Поэтому вместо того, чтобы решать его как (Banana vs Orange vs Apple), он решается с использованием трех задач двоичной классификации, как показано выше.
Основным недостатком этого метода является необходимость создания множества моделей. Для задачи с несколькими классами с n количеством классов необходимо создать n моделей, что может замедлить весь процесс. Однако это очень полезно для наборов данных, имеющих небольшое количество классов, где мы хотим использовать такую модель, как SVM или логистическая регрессия.
Реализация метода One-vs-Rest с использованием Python3
Библиотека Python scikit-learn предлагает метод OneVsRestClassifier (оценка, *, n_jobs = None) для реализации этого метода. Для этой реализации мы будем использовать популярный набор данных Wine, чтобы определять происхождение вин по химическим атрибутам. Мы можем направить этот набор данных с помощью scikit-learn. Чтобы узнать больше об этом наборе данных, вы можете использовать ссылку ниже: Wine Dataset
Мы будем использовать машину опорных векторов, которая представляет собой алгоритм двоичной классификации, и использовать его с эвристикой One-vs-Rest для выполнения мультиклассовой классификации.
Чтобы оценить нашу модель, мы увидим оценку точности набора тестов и отчет о классификации модели.
from sklearn.datasets import load_winefrom sklearn.multiclass import OneVsRestClassifierfrom sklearn.svm import SVCfrom sklearn.metrics import accuracy_score, classification_reportfrom sklearn.model_selection import train_test_splitwarnings import '''We are ignoring warnings because of a peculiar fact about thisdataset. The 3rd label, 'Label2' is never predicted and so the pythoninterpreter throws a warning. However, this can safely be ignored becausewe are not concerned if a certain label is predicted or not'''warnings.filterwarnings( 'ignore' ) # Loading the datasetdataset = load_wine()X = dataset.datay = dataset.target # Splitting the dataset into training and testing setsX_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.1 , random_state = 13 ) # Creating the SVM modelmodel = OneVsRestClassifier(SVC()) # Fitting the model with training datamodel.fit(X_train, y_train) # Making a prediction on the test setprediction = model.predict(X_test) # Evaluating the modelprint (f"Test Set Accuracy : {accuracy_score( y_test, prediction) * 100 } %
")print (f"Classification Report :
{classification_report( y_test, prediction)}") |
Выход:
Точность тестового набора: 66,66666666666666%
Классификационный отчет:
точный отзыв поддержка f1-score
0 0,62 1,00 0,77 5
1 0,70 0,88 0,78 8
микро средн 0,67 0,92 0,77 13
макрос ср. 0,66 0,94 0,77 13
средневзвешенная 0,67 0,92 0,77 13
Мы получаем точность тестового набора примерно 66,667%. Это неплохо для этого набора данных. Этот набор данных печально известен тем, что его сложно классифицировать, а точность теста составляет 62,4 ± 0,4%. Итак, наш результат на самом деле неплохой.
Заключение:
Теперь, когда вы знаете, как использовать эвристический метод One-vs-Rest для выполнения мультиклассовой классификации с бинарными классификаторами, вы можете попробовать использовать его в следующий раз, когда вам нужно будет выполнить некоторую задачу классификации мультиклассов.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.