SQL-запрос для поиска повторяющихся имен в таблице
Повторяющиеся записи в базе данных иногда могут быть проблематичными, поскольку они создают путаницу или могут генерировать неправильные выходные данные. Итак, лучше удалить все повторяющиеся записи из базы данных, так как это сэкономит наше время и место. Однако наилучшей практикой является наложение уникальных ограничений (ограничений первичного ключа) на таблицу, чтобы предотвратить это.
Эта ошибка может быть вызвана различными причинами, такими как:
- Недостатки приложения,
- Ошибка пользователя
- Плохой дизайн базы данных
- Или из-за какого-то неизвестного внешнего источника.
Итак, в этой статье мы собираемся найти повторяющиеся имена в таблице. Чтобы сделать этот запрос, нам нужно знать об операторе GROUP BY и агрегатных функциях (в частности, COUNT() ).
Мы рекомендуем вам сначала прочитать эту статью для лучшего понимания.
Чтобы найти повторяющиеся имена в таблице, мы должны выполнить следующие шаги:
- Определение критериев: Во- первых, вам нужно определить критерии для поиска повторяющихся имен. Возможно, вы захотите выполнить поиск в одном столбце или более.
- Напишите запрос: Затем просто напишите запрос, чтобы найти повторяющиеся имена.
Давайте начнем-
Предположим, вы работаете с базой данных веб-сайта электронной коммерции. Теперь некоторые имена пользователей сохраняются более одного раза, как и их идентификаторы электронной почты. Это приведет к ошибочным аналитическим результатам для веб-сайта электронной коммерции, поскольку повторное сохранение этих данных не требуется.
Теперь давайте сначала создадим нашу демонстрационную базу данных,
Шаг 1: Создание базы данных
Создайте новую базу данных с именем User_details, а затем используйте ее.
Запрос:
CREATE DATABASE User_details; USE User_details;
Выход:
Шаг 2: Определение таблицы
Создайте таблицу с именем Users1 и добавьте эти четыре столбца ID, Names, EmailId и Age.
Запрос:
CREATE Table Users1 (ID VARCHAR(20) Primary Key, Names VARCHAR(30), EmailId VARCHAR(30), Age INT);
Выход:
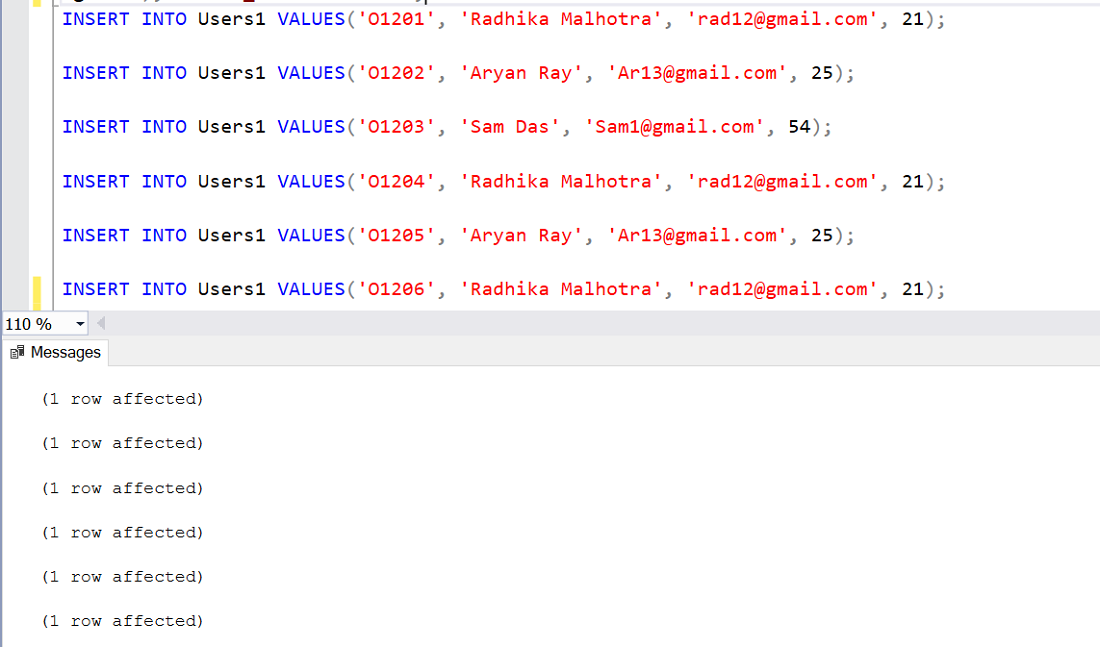
Шаг 3: Вставьте строки в таблицу и Вставьте эти шесть строк в таблицу.
Запрос:
INSERT INTO Users1 VALUES("O1201", "Radhika Malhotra", "rad12@gmail.com", 21);
INSERT INTO Users1 VALUES("O1202", "Aryan Ray", "Ar13@gmail.com", 25);
INSERT INTO Users1 VALUES("O1203", "Sam Das", "Sam1@gmail.com", 54);
INSERT INTO Users1 VALUES("O1204", "Radhika Malhotra", "rad12@gmail.com", 21);
INSERT INTO Users1 VALUES("O1205", "Aryan Ray", "Ar13@gmail.com", 25);
INSERT INTO Users1 VALUES("O1206", "Radhika Malhotra", "rad12@gmail.com", 21); Выход:
Шаг 4: Просмотр вставленных данных
Запустите эту команду, чтобы увидеть нашу таблицу.
Запрос:
SELECT * FROM Users1;
Выход:
Шаг 5: Теперь давайте сделаем наш запрос, чтобы найти повторяющиеся имена в этой таблице.
- Определение критериев: Здесь мы определяем критерии только для столбца Names, выбранного из таблицы Users1.
Запрос:
SELECT Names,COUNT(*) AS Occurrence FROM Users1 GROUP BY Names HAVING COUNT(*)>1;
Этот запрос прост. Здесь мы используем предложение GROUP BY для группировки одинаковых строк в столбце Names. Затем мы находим количество дубликатов в этом столбце с помощью функции COUNT() и показываем эти данные в новом столбце с именем Occurrence. Наличие предложения сохраняет только те группы, которые имеют более одного вхождения.
Выход:
Мы нашли повторяющиеся имена и их появление в нашей таблице. Эта информация может помочь нам удалить повторяющиеся строки из таблицы в будущем.