Разработка оболочки на базе Linux
Что такое оболочка?
Это видимая часть операционной системы, с которой взаимодействуют пользователи, пользователи взаимодействуют с операционной системой, предоставляя команды оболочке, которая, в свою очередь, интерпретирует эти команды и выполняет их.
На следующем изображении показан упрощенный процесс выполнения, в котором оболочка получает ввод,
передает его в лексический анализатор (будет подробно обсужден), который создаст токены, затем вывод лексического анализатора будет передан синтаксическому анализатору, который проверяет его на наличие синтаксических ошибок и выполняет назначенные семантические действия (это создает таблицу команд) , и, наконец, когда синтаксический анализатор достигнет определенной точки, таблица будет выполнена.
Оболочка будет реализована из трех компонентов, как показано на схеме архитектуры ниже:
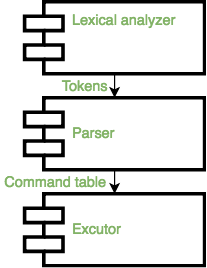
1. Лексический анализатор
Первая часть синтаксического анализа входных данных - это этап лексического анализа, на котором входные данные считываются посимвольно для формирования токенов, мы будем использовать команду под названием lex для создания нашего файла, в этом файле мы определим наш шаблон, за которым следует: имя токена лексический анализатор будет читать введенный символ за символом, и когда шаблон соответствует строке слева, он будет преобразован в строку справа.
бывший:
Ввод команды: ls -al
Синтаксический анализатор будет читать l, затем s формирует токен с именем WORD, затем он будет читать - и символы (al) и сформировать OPTION, вывод будет WORD OPTION, этот вывод будет передан синтаксическому анализатору для проверки наличия синтаксической ошибки.
1. “#” : IO
2. [ 1 ]?”>” : IO
3. “” : IO
5. [ 1]?”>>” : IO
6. [ 1-2]”>&”[1-2 ] : IOR
7. “|” : PIPE
8. “&” : AMPERSAND
9. [ ]”-“[a-zA-Z0-9]* : OPTION
10. [ ]”–“[a-zA-Z=a-zA-Z]* : OPTION2
11. \%=+’”()$/\_-.?*~a-zA-Z0-9]+ : WORD
Приведенная выше грамматика состоит из 11 токенов, которые эти токены образуют, когда ввод соответствует описанию токена.
Токен ввода-вывода состоит из символа # или символа '>', которому может предшествовать номер один (максимум один раз), или 'который мы представили как новый токен, заменяющий токен перенаправления ошибки, используется другая форма ввода-вывода'> > ', которому может предшествовать номер один (максимум один раз), и, наконец,'> & ', который является IOR, за которым может предшествовать и / или за ним может стоять один или два.
Знаки трубы и амперсанда формируются в '|' и '&' соответственно, токен опции формируется, когда перед дефисом ставится пробел, за которым следует любой буквенный символ или цифра.
Токен option2 формируется, когда есть два дефиса, которым предшествует пробел и за которыми следует любой буквенный символ.
Токен WORD может состоять из букв, цифр и следующих символов%, =, +, ', «, (,), $, /, _, -,.,?, *, ~
2. Парсер
После того, как токены были сформированы из ввода, токены передаются в виде потока синтаксическому анализатору, который анализирует ввод для обнаружения синтаксической ошибки и выполнения назначенных семантических действий. Парсер можно рассматривать как грамматику и синтаксис языка (который определяет, как наши команды будут выглядеть приемлемыми), мы будем использовать команду yacc для компиляции грамматики, мы построим грамматику как форму состояний, которые упрощает построение и развертывание грамматики.
Ниже приводится определение нашей грамматики:
1. q00: NEWLINE {return 0;} | cmd q1 q0 | error;
2. q0: NEWLINE {return 1;} | PIPE q00 {clrcont;};
3. q1: option q2 | option option q2 | arg_list q3 | io_modifier q4 | background q5 | io_descr q3 | /*empty*/ {InsertNode(); clrcont();};
4. q2: arg_list q3 | io_modifier q4 | io_descr q3 | background q5 | /*empty*/ {InsertNode(); clrcont();};
5. q3: io_modifier q4 | io_descr q3 | background q5 | /*empty*/ {InsertNode(); clrcont();};
6. q4: file q3 ;
7. cmd: WORD {cmad.cmd = yylval.str;};
8. arg_list: arg | arg arg_list;
9. arg: WORD {insertArgNode(yylval.str);};
10. file: WORD {io_red(yylval.str);};
11. io_modifier: IO {cmad.op=yylval.str;};
12. io_descr: IOR {cmad.op=yylval.str;};
13. option: OPTION {cmad.opt = yylval.str;} | OPTION2 {cmad.opt2 = yylval.str;};
14. background: AMPERSAND {bg = ‘1’;};
15. q5: /*empty*/{InsertNode(); clrcont();};
Вышеупомянутая грамматика определяет различные состояния процесса синтаксического анализа,
Синтаксический анализатор начинает с состояния q00 и выполняет синтаксический анализ до достижения одного из состояний q5, q3, q1, что происходит в обратном порядке из-за используемой техники синтаксического анализа (синтаксический анализ снизу вверх), грамматика уменьшает токены в зависимости от их местоположения, Word может быть сокращено до cmd, если оно появляется в начале, arg_list, если оно появляется после команды, file, если оно появляется после перенаправления, тогда предложение анализируется в соответствии с грамматикой, начиная с состояния q00 парсер переходит в состояние q1, читая cmd , в состоянии q1, если синтаксический анализатор читает опцию, предложение может иметь один из следующих аргументов, ввод-вывод или фон после, или не иметь ничего, если синтаксический анализатор читает аргументы, предложение может иметь перенаправление только после того, как синтаксический анализатор читает амперсанд, там должно быть ничего не будет после.
Затем процесс запускается снова, когда синтаксический анализатор читает канал, это позволяет нескольким простым командам соединяться конвейерами для формирования сложной команды.
Мы определяем простую команду как любую команду, которая состоит из команды, параметров, аргументов и / или перенаправления ввода-вывода.
Объединение нескольких простых команд с использованием конвейеров приводит к структуре, которую мы называем сложной командой.
Семантические действия, связанные с грамматикой, создают таблицу синтаксического анализа и присваивают значения команд структуре данных, которая после построения таблицы команд отправляется исполнителю.
Таблица команд состоит из строк простых команд, и эти строки формируются из сложной команды, соединенной трубами, простой записи команды, которая содержит имя команды, которая должна быть выполнена, параметров, которые являются параметрами, которые должны быть выполнены с командой, аргументов, которые содержат аргументы, которые должны быть переданы команде, стандартный вход (stdIn), который указывает место, из которого команда будет получать свои входные данные, по умолчанию это терминал, если не указано в команде, в противном случае стандартный выход (stdOut) указывает место, где команда выводит результат выполнения, и по умолчанию это терминал, стандартная ошибка (stdError) указывает место, где команда будет печатать сообщения об ошибках выполнения, и по умолчанию это терминал, если пользователь не перенаправит его.
Построенная грамматика допускает следующий синтаксис:

Это позволяет команде с параметрами, аргументами, перенаправлением ввода-вывода и быть фоновым процессом (&). команда с любой из предыдущих - это простая команда, когда мы соединяем несколько простых команд, мы формируем сложную команду.
Во время синтаксического анализа команды наш синтаксический анализатор сохраняет детали команды в нашей таблице для передачи ее исполнителю.
Мы выбрали таблицу в качестве структуры данных, нам нужно сохранить следующую информацию о каждой команде: Command, Option, Option2, Arguments, StdIn, StdOut, StdError.
Например:
ls –al | sort -r
Эта команда приведет к следующей таблице (каждая строка представляет собой простую команду, сама таблица представляет собой сложную команду).

3. исполнитель
После построения таблицы команд исполнитель отвечает за создание процесса для каждой команды в таблице и при необходимости обрабатывает любое перенаправление.
Исполнитель выполняет итерацию по таблице, чтобы выполнить каждую простую команду и подключить ее к следующей при каждой записи в таблице (простая команда), исполнитель приказывает передать команду, параметр и аргументы в функцию execvp, которая заменяет текущий вызывающий процесс. с вызываемым, функция execvp в качестве первого параметра получает имя файла, который должен быть выполнен, и массив с завершающим нулем, содержащий параметры (если есть), за которыми следуют аргументы.
Но до того, как execvp вызывается, Executor обрабатывает перенаправление в оболочке, если команде предшествует команда, это означает, что перед ней есть канал, и, таким образом, ввод команды настроен на получение из предыдущего канала, тогда команда проверяется на наличие любое перенаправление ввода, которое, если существует, перезаписывает ввод из предыдущего канала, если команде не предшествует команда, тогда нет конвейера (простая команда), в противном случае (более одной простой команды) вывод команды отправляется следующей в таблице, команда затем проверяется на перенаправление вывода, если перенаправление ввода есть, ввод из назначенного файла перезаписывает ввод от предыдущей команды.
После того, как перенаправление было обработано, команда проверяется на наличие флага фона, который указывает, должна ли оболочка дождаться завершения выполнения команды или отправить процесс для выполнения в фоновом режиме, чтобы исполнитель выполнил команду, которую он должен создать образ оболочки для выполнения, исполнитель разветвляет текущий процесс (оболочку) и выполняет команду на дочернем элементе этой вилки.
Исполнитель начинает с выполнения первой строки, устанавливая вывод команды на стандартный вывод, затем перезаписывая вывод в конвейер, чтобы быть полученным второй командой, после того, как первая команда (ls –al) выполняет вторую команду. начинает выполнение, назначая ввод для чтения из стандартного ввода сначала, затем, поскольку команде предшествует другой, ввод настроен на получение из канала, и поскольку команда не содержит перенаправления ввода (из файла) стандартный ввод для команды останется из конвейера, стандартный вывод команды будет на экране, затем команда проверяется, должна ли она отправлять свой вывод следующей команде, в этом случае это последняя команда, поэтому вывод не будет перезаписан конвейером, но поскольку команда имеет перенаправление вывода в файл, файл будет перезаписывать стандартный вывод.
Выполнение следующей команды
ls –al | sort –r> файл
Таблица, которую строит парсер, будет выглядеть так:

Код исполнителя будет перебирать эту таблицу и выполнять шаги, упомянутые выше, и очищать все, когда команда завершается, чтобы быть готовым к приему следующей команды.
Вниманию читателя! Не переставай учиться сейчас. Ознакомьтесь со всеми важными концепциями теории CS для собеседований по SDE с помощью курса теории CS по доступной для студентов цене и будьте готовы к работе в отрасли.