Рассчитайте MSE для случайного леса в R, используя пакет randomForest
Random Forest — это контролируемый алгоритм машинного обучения. Это ансамблевый алгоритм, который использует подход начальной агрегации в фоновом режиме для прогнозирования.
To learn more about random forest regression in R Programming Language refer to the below article –
Random Forest Approach for Regression in R Programming
Поскольку мы знаем, что алгоритм случайного леса можно использовать для прогнозирования как непрерывных значений (регрессия), так и дискретных значений (классификация). В этой статье мы собираемся прочитать о том, как мы можем вычислить среднеквадратичную ошибку для модели случайного леса, построенной с использованием библиотека randomForest в R.
Среднеквадратическая ошибка — это показатель оценки, который используется для вычисления среднеквадратичной разницы между фактическим значением и прогнозируемым значением. MSE — это неотрицательное значение, которое показывает, насколько близка линия регрессии к фактическому набору точек данных. Для оценки эффективности регрессионной модели мы используем среднеквадратичную ошибку (MSE). Чем ближе значение MSE к 0, тем лучше будет прогноз. Математическое уравнение для среднеквадратичной ошибки имеет вид:
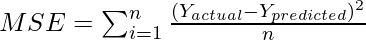
В целях создания модели набор данных, который мы здесь используем, взят из задачи искусственного интеллекта по прогнозированию энергии электростанции Dockship.
В этой задаче нам нужно предсказать почасовую выработку энергии электростанцией. PE — это целевой столбец в нашем наборе данных. Чтобы узнать больше о наборе данных, перейдите на панель задач по соответствующей ссылке, опубликованной выше.
Рассчитайте MSE для случайного леса в R, используя пакет randomForest
Шаг 1: На первом этапе мы будем импортировать необходимые библиотеки, которые будем использовать в нашей программе.
R
# Importing the required libraries library("readr")library("randomForest") |
Здесь мы импортировали две библиотеки с именами «readr» и «randomForest», первая помогает нам читать и загружать данные из файла CSV в среду, а вторая используется для создания модели случайного леса.
Шаг 2: Мы начнем загружать набор данных в нашу среду, используя функцию read_csv(), доступную в библиотеке «readr».
R
# specifying the pathpath <- "/power_plant_energy_prediction/TRAIN.csv" # reading contents of csv filecontent <- read_csv(path) print(content) |
Выход:
Шаг 3: Чтобы создать модель машинного обучения, нам нужно обучить модель на тренировочном наборе, а затем мы проверим производительность нашей модели на проверочном наборе. Следовательно, мы разделим набор данных на обучающий набор с именем train_set и набор для проверки с именем val_set. Весь набор данных содержит 8000 строк, мы будем использовать первые 7000 строк в train_set для обучения, а остальные 1000 строк — для проверки.
R
# Splitting data for training # and validation purposetrain_set <- content[1:7000,]val_set <- tail(content, -7000) |
Шаг 4: Теперь мы будем использовать функцию randomForest(), доступную в пакете randomForest, для создания модели случайного леса. Мы используем train_set для обучения нашей модели, где PE является нашей целевой функцией. Модель создана с использованием 100 деревьев в учебных целях.
R
rf_model <- randomForest(PE~., data=train_set, ntree=100, importance=TRUE) |
Шаг 5: Теперь мы будем использовать нашу обученную модель случайного леса для прогнозирования выходных значений для нашего проверочного набора, что можно сделать с помощью функции predict() путем передачи объекта обученной модели, т. е. rf_model, и проверочного набора, т. е. val_set. Прогнозируемые значения хранятся внутри переменной EnergyPred.
R
EnergyPred <- predict(rf_model, val_set) |
Шаг 6: На этом этапе мы будем оценивать производительность нашей модели, вычисляя среднеквадратичную ошибку между нашими фактическими и прогнозируемыми значениями с использованием модели. Это можно сделать как:
R
print(mean((EnergyPred-val_set$PE)^2)) |
Выход:
12:26536
Сгенерированный результат равен 12,26536 , что относительно близко к 0. Таким образом, мы можем сказать, что наша модель имеет достойную производительность на проверочном наборе. Мы даже можем улучшить производительность нашей модели случайного леса, настроив гиперпараметры, которые помогают уменьшить переобучение и, таким образом, повысить производительность модели.