Распознавание человеческой деятельности - использование модели глубокого обучения
Распознавание человеческой активности с помощью сенсоров смартфонов, таких как акселерометр, - одна из самых напряженных тем исследований. HAR - одна из проблем классификации временных рядов. В этом проекте были разработаны различные модели машинного обучения и глубокого обучения для получения наилучшего конечного результата. В той же последовательности мы можем использовать LSTM (долговременную память) модель рекуррентной нейронной сети (RNN) для распознавания различных действий людей, таких как стояние, подъем по лестнице и т. Д.
Модель LSTM - это тип рекуррентной нейронной сети, способной определять зависимость порядка обучения в задачах прогнозирования последовательности. Эта модель используется, поскольку она помогает запоминать значения через произвольные интервалы.
Набор данных распознавания человеческой деятельности можно загрузить по приведенной ниже ссылке: Набор данных HAR
Деятельность:
- Гулять пешком
- Вверх по лестнице
- Вниз по лестнице
- Сидя
- Стоя
Акселерометры определяют величину и направление надлежащего ускорения в виде векторной величины и могут использоваться для определения ориентации (из-за изменения направления веса). GyroScope сохраняет ориентацию вдоль оси, так что на ориентацию не влияет наклон или вращение крепления, в соответствии с сохранением углового момента.
Понимание набора данных:
- Оба датчика генерируют данные в трехмерном пространстве с течением времени.
('XYZ' представляет 3-осевые сигналы в направлениях X, Y и Z). - Доступные данные предварительно обрабатываются с применением шумовых фильтров, а затем дискретизируются в окнах фиксированной ширины, т. Е. Каждое окно имеет 128 показаний.
Данные по поезду и тесту были разделены как
Показания 80% добровольцев были взяты в качестве данных тренировки, а записи оставшихся 20% добровольцев были взяты для данных испытаний. Все данные находятся в папке, загруженной по указанной выше ссылке.
Фазы
- Выбор набора данных
- Загрузка набора данных на диск для работы в google colaboratory
- Очистка наборов данных и предварительная обработка данных
- Выбор модели и построение сетевой модели с глубоким изучением
- Экспорт в Android Studio.
IDE, используемая для этого проекта, - это Google Colaboratory, которая лучше всего подходит для проектов глубокого обучения. Фаза 1 была объяснена выше относительно того, откуда загружается набор данных. В этой последовательности, чтобы начать работу с проектом, откройте новую записную книжку в Google Colaboratory и сначала импортируйте все необходимые библиотеки.
import pandas as pdimport numpy as npimport pickleimport matplotlib.pyplot as pltfrom scipy import statsimport tensorflow as tfimport seaborn as snsfrom sklearn import metricsfrom sklearn.model_selection import train_test_split % matplotlib inline |
Фаза 2:
Он загружает набор данных в ноутбук, прежде чем это сделать, нам нужно установить ноутбук на диск, чтобы этот ноутбук сохранялся на нашем диске и извлекался при необходимости.
sns. set (style = "whitegrid" , palette = "muted" , font_scale = 1.5 )RANDOM_SEED = 42 from drive import google.colabdrive.mount( '/content/drive' ) |
Выход:
Вы увидите всплывающее окно, подобное показанному на скриншоте ниже, откройте ссылку, скопируйте код авторизации, вставьте его в строку кода авторизации и введите диск будет смонтирован.

Код: загрузка набора данных
from files import google.colabuploaded = files.upload() |
Теперь, переходя к этапу построения и обучения модели, нам нужно искать различные модели, которые могут помочь в построении модели с большей точностью. Здесь выбрана модель рекуррентной нейронной сети LSTM. На приведенном ниже изображении показано, как выглядят данные.
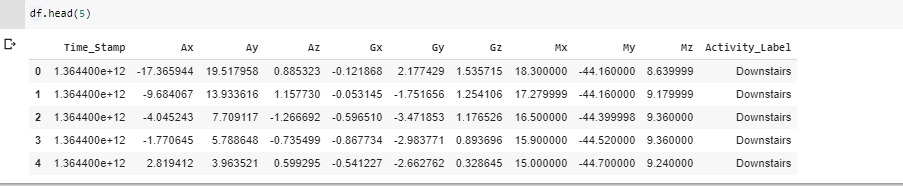
Фаза 3:
Все начинается с предварительной обработки данных. Это этап, на котором ~ 90% времени уходит на реальные проекты в области науки о данных. Здесь необработанные данные берутся и преобразуются в некоторые полезные и эффективные форматы.
Код: преобразование данных выполняется для нормализации данных
#transforming shapereshaped_segments = np.asarray( segments, dtype = np.float32).reshape( - 1 , N_time_steps, N_features) reshaped_segments.shape |
Код: разделение набора данных
X_train, X_test, Y_train, Y_test = train_test_split( reshaped_segments, labels, test_size = 0.2 , random_state = RANDOM_SEED) |
Размер теста принимается равным 20%, т.е. из общего числа записей 20% записей используются для проверки точности, а остальные используются для обучающей модели.
Количество классов = 6 (ходьба, сидение, стоя, бег, наверху и внизу)
Фаза 4: В этой фазовой модели выбрана LSTM-модель RNN.
Код: Модель здания
def create_LSTM_model(inputs): W = { 'hidden' : tf.Variable(tf.random_normal([N_features, N_hidden_units])), 'output' : tf.Variable(tf.random_normal([N_hidden_units, N_classes])) } biases = { 'hidden' : tf.Variable(tf.random_normal([N_hidden_units], mean = 0.1 )), 'output' : tf.Variable(tf.random_normal([N_classes])) } X = tf.transpose(inputs, [ 1 , 0 , 2 ]) X = tf.reshape(X, [ - 1 , N_features]) hidden = tf.nn.relu(tf.matmul(X, W[ 'hidden' ]) + biases[ 'hidden' ]) hidden = tf.split(hidden, N_time_steps, 0 ) lstm_layers = [tf.contrib.rnn.BasicLSTMCell( N_hidden_units, forget_bias = 1.0 ) for _ in range ( 2 )] lstm_layers = tf.contrib.rnn.MultiRNNCell(lstm_layers) outputs, _ = tf.contrib.rnn.static_rnn(lstm_layers, hidden, dtype = tf.float32) lstm_last_output = outputs[ - 1 ] return tf.matmul(lstm_last_output, W[ 'output' ]) + biases[ 'output' ] |
Код: выполнение оптимизации с использованием AdamOptimizer для изменения значений потерь относительно переменных, чтобы повысить точность и уменьшить потери.
L2_LOSS = 0.0015l2 = L2_LOSS * sum (tf.nn.l2_loss(tf_var) for tf_var in tf.trainable_variables())loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits( logits = pred_y, labels = Y)) + l2 Learning_rate = 0.0025optimizer = tf.train.AdamOptimizer(learning_rate = Learning_rate).minimize(loss)correct_pred = tf.equal(tf.argmax(pred_softmax , 1 ), tf.argmax(Y, 1 ))accuracy = tf.reduce_mean(tf.cast(correct_pred, dtype = tf.float32)) |
Код: выполнение 50 итераций обучения модели для достижения максимальной точности и снижения потерь.
# epochs is number of iterations performed in model training.N_epochs = 50batch_size = 1024 saver = tf.train.Saver()history = dict (train_loss = [], train_acc = [], test_loss = [], test_acc = [])sess = tf.InteractiveSession()sess.run(tf.global_variables_initializer())train_count = len (X_train) for i in range ( 1 , N_epochs + 1 ): for start, end in zip ( range ( 0 , train_count, batch_size), range (batch_size, train_count + 1 , batch_size)): sess.run(optimizer, feed_dict = {X: X_train[start:end], Y: Y_train[start:end]}) _, acc_train, loss_train = sess.run([pred_softmax, accuracy, loss], feed_dict = { X: X_train, Y: Y_train}) _, acc_test, loss_test = sess.run([pred_softmax, accuracy, loss], feed_dict = { X: X_test, Y: Y_test}) history[ 'train_loss' ].append(loss_train) history[ 'train_acc' ].append(acc_train) history[ 'test_loss' ].append(loss_test) history[ 'test_acc' ].append(acc_test) if (i ! = 1 and i % 10 ! = 0 ): print (f 'epoch: {i} test_accuracy:{acc_test} loss:{loss_test}' )predictions, acc_final, loss_final = sess.run([pred_softmax, accuracy, loss], feed_dict = {X: X_test, Y: Y_test})print ()print (f 'final results : accuracy : {acc_final} loss : {loss_final}' ) |
Выход:
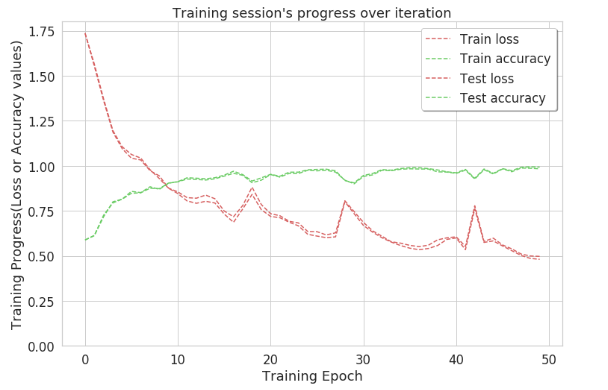
Таким образом, при таком подходе точность достигает ~ 1 на 50-й итерации. Это указывает на то, что большинство этикеток четко идентифицируются при таком подходе. Для точного подсчета правильно идентифицированных действий создается матрица путаницы.
Код: График точности
plt.figure(figsize = ( 12 , 8 )) plt.plot(np.array(history[ 'train_loss' ]), "r--" , label = "Train loss" )plt.plot(np.array(history[ 'train_acc' ]), "g--" , label = "Train accuracy" ) plt.plot(np.array(history[ 'test_loss' ]), "r--" , label = "Test loss" )plt.plot(np.array(history[ 'test_acc' ]), "g--" , label = "Test accuracy" ) plt.title( "Training session's progress over iteration" )plt.legend(loc = 'upper right' , shadow = True )plt.ylabel( 'Training Progress(Loss or Accuracy values)' )plt.xlabel( 'Training Epoch' )plt.ylim( 0 ) plt.show() |
Матрица неточностей: матрица неточностей - это не что иное, как 2D-матрица, в отличие от нее, помогающая рассчитать точное количество правильно идентифицированных действий. Другими словами, он описывает производительность модели классификации на наборе тестовых данных.
Код: матрица путаницы
max_test = np.argmax(Y_test, axis = 1 )max_predictions = np.argmax(predictions, axis = 1 )confusion_matrix = metrics.confusion_matrix(max_test, max_predictions) plt.figure(figsize = ( 16 , 14 ))sns.heatmap(confusion_matrix, xticklabels = LABELS, yticklabels = LABELS, annot = True , fmt = "d" )plt.title( "Confusion Matrix" )plt.xlabel( 'Predicted_label' )plt.ylabel( 'True Label' )plt.show() |
Это полное описание проекта на данный момент. Его можно построить с использованием таких моделей, как CNN, или моделей машинного обучения, таких как KNN.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.

- Глубокое обучение
- Машинное обучение
- Python
- Машинное обучение