Python | Классификация изображений с использованием keras
Предварительное условие: классификатор изображений с использованием CNN
Классификация изображений - это метод классификации изображений по соответствующим классам категорий с использованием некоторого метода, например:
- Обучение небольшой сети с нуля
- Тонкая настройка верхних слоев модели с помощью VGG16
Давайте обсудим, как обучить модель с нуля и классифицировать данные, содержащие автомобили и самолеты.
Данные поезда: данные поезда содержат 200 изображений каждой машины и самолета, то есть всего их 400 изображений в наборе обучающих данных.
Тестовые данные: тестовые данные содержат 50 изображений каждой машины и самолета, т.е. всего их 100 изображений в наборе тестовых данных.
Чтобы загрузить полный набор данных, щелкните здесь.
Описание модели: Перед тем, как начать работу с моделью, сначала подготовьте набор данных и его расположение. Посмотрите на следующее изображение, приведенное ниже:
Для загрузки папок с наборами данных они должны быть созданы и предоставлены только в этом формате. Итак, давайте начнем с модели:
Для обучения модели нам не нужна большая высокопроизводительная машина и графические процессоры, мы также можем работать с процессорами. Во-первых, в данный код включены следующие библиотеки:
# Importing all necessary librariesfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.models import Sequentialfrom keras.layers import Conv2D, MaxPooling2Dfrom keras.layers import Activation, Dropout, Flatten, Densefrom keras import backend as K img_width, img_height = 224 , 224 |
Каждое изображение в наборе данных имеет размер 224 * 224.
train_data_dir = 'v_data/train'validation_data_dir = 'v_data/test'nb_train_samples = 400nb_validation_samples = 100epochs = 10batch_size = 16 |
Здесь train_data_dir - это каталог набора данных поезда. validation_data_dir - это каталог для данных проверки. nb_train_samples - общее количество образцов поездов. nb_validation_samples - общее количество проверочных образцов.
Проверка формата изображения:
if K.image_data_format() = = 'channels_first' : input_shape = ( 3 , img_width, img_height)else : input_shape = (img_width, img_height, 3 ) |
Эта часть предназначена для проверки формата данных, т.е. канал RGB идет первым или последним, поэтому, каким бы он ни был, модель сначала проверит, а затем форма ввода будет загружена соответствующим образом.
model = Sequential()model.add(Conv2D( 32 , ( 2 , 2 ), input_shape = input_shape))model.add(Activation( 'relu' ))model.add(MaxPooling2D(pool_size = ( 2 , 2 ))) model.add(Conv2D( 32 , ( 2 , 2 )))model.add(Activation( 'relu' ))model.add(MaxPooling2D(pool_size = ( 2 , 2 ))) model.add(Conv2D( 64 , ( 2 , 2 )))model.add(Activation( 'relu' ))model.add(MaxPooling2D(pool_size = ( 2 , 2 ))) model.add(Flatten())model.add(Dense( 64 ))model.add(Activation( 'relu' ))model.add(Dropout( 0.5 ))model.add(Dense( 1 ))model.add(Activation( 'sigmoid' )) |
О следующих терминах, использованных выше:
Conv2Dis the layer to convolve the image into multiple imagesActivationis the activation function.MaxPooling2Dis used to max pool the value from the given size matrix and same is used for the next 2 layers. then,Flattenis used to flatten the dimensions of the image obtained after convolving it.Denseis used to make this a fully connected model and is the hidden layer.Dropoutis used to avoid overfitting on the dataset.Denseis the output layer contains only one neuron which decide to which category image belongs.
Функция компиляции:
model. compile (loss = 'binary_crossentropy' , optimizer = 'rmsprop' , metrics = [ 'accuracy' ]) |
Здесь используется функция компиляции, которая включает использование потерь, оптимизаторов и показателей. Здесь используется функция потерь binary_crossentropy , а оптимизатор - rmsprop .
Используя DataGenerator:
train_datagen = ImageDataGenerator( rescale = 1. / 255 , shear_range = 0.2 , zoom_range = 0.2 , horizontal_flip = True ) test_datagen = ImageDataGenerator(rescale = 1. / 255 ) train_generator = train_datagen.flow_from_directory( train_data_dir, target_size = (img_width, img_height), batch_size = batch_size, class_mode = 'binary' ) validation_generator = test_datagen.flow_from_directory( validation_data_dir, target_size = (img_width, img_height), batch_size = batch_size, class_mode = 'binary' ) model.fit_generator( train_generator, steps_per_epoch = nb_train_samples / / batch_size, epochs = epochs, validation_data = validation_generator, validation_steps = nb_validation_samples / / batch_size) |
Теперь dataGenerator к фигуре компонента dataGenerator, в котором мы использовали:
ImageDataGeneratorthat rescales the image, applies shear in some range, zooms the image and does horizontal flipping with the image. This ImageDataGenerator includes all possible orientation of the image.train_datagen.flow_from_directoryis the function that is used to prepare data from the train_dataset directoryTarget_sizespecifies the target size of the image.test_datagen.flow_from_directoryis used to prepare test data for the model and all is similar as above.fit_generatoris used to fit the data into the model made above, other factors used aresteps_per_epochstells us about the number of times the model will execute for the training data.epochstells us the number of times model will be trained in forward and backward pass.validation_datais used to feed the validation/test data into the model.validation_stepsdenotes the number of validation/test samples.
model.save_weights( 'model_saved.h5' ) |
Наконец-то мы также можем сохранить модель.
Ниже представлена полная реализация:
# importing librariesfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.models import Sequentialfrom keras.layers import Conv2D, MaxPooling2Dfrom keras.layers import Activation, Dropout, Flatten, Densefrom keras import backend as K img_width, img_height = 224 , 224 train_data_dir = 'v_data/train'validation_data_dir = 'v_data/test'nb_train_samples = 400nb_validation_samples = 100epochs = 10batch_size = 16 if K.image_data_format() = = 'channels_first' : input_shape = ( 3 , img_width, img_height)else : input_shape = (img_width, img_height, 3 ) model = Sequential()model.add(Conv2D( 32 , ( 2 , 2 ), input_shape = input_shape))model.add(Activation( 'relu' ))model.add(MaxPooling2D(pool_size = ( 2 , 2 ))) model.add(Conv2D( 32 , ( 2 , 2 )))model.add(Activation( 'relu' ))model.add(MaxPooling2D(pool_size = ( 2 , 2 ))) model.add(Conv2D( 64 , ( 2 , 2 )))model.add(Activation( 'relu' ))model.add(MaxPooling2D(pool_size = ( 2 , 2 ))) model.add(Flatten())model.add(Dense( 64 ))model.add(Activation( 'relu' ))model.add(Dropout( 0.5 ))model.add(Dense( 1 ))model.add(Activation( 'sigmoid' )) model. compile (loss = 'binary_crossentropy' , optimizer = 'rmsprop' , metrics = [ 'accuracy' ]) train_datagen = ImageDataGenerator( rescale = 1. / 255 , shear_range = 0.2 , zoom_range = 0.2 , horizontal_flip = True ) test_datagen = ImageDataGenerator(rescale = 1. / 255 ) train_generator = train_datagen.flow_from_directory(train_data_dir, target_size = (img_width, img_height), batch_size = batch_size, class_mode = 'binary' ) validation_generator = test_datagen.flow_from_directory( validation_data_dir, target_size = (img_width, img_height), batch_size = batch_size, class_mode = 'binary' ) model.fit_generator(train_generator, steps_per_epoch = nb_train_samples / / batch_size, epochs = epochs, validation_data = validation_generator, validation_steps = nb_validation_samples / / batch_size) model.save_weights( 'model_saved.h5' ) |
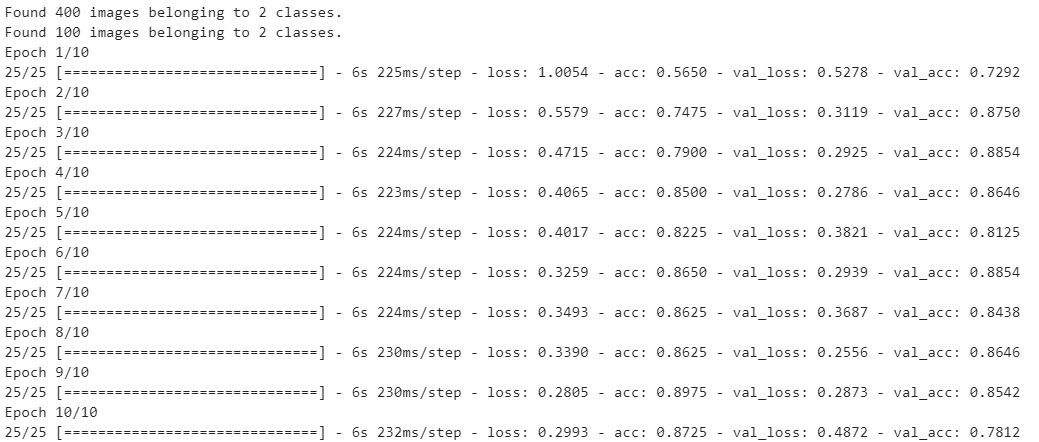
Выход: