Преобразование изображения в изображение с помощью Pix2Pix
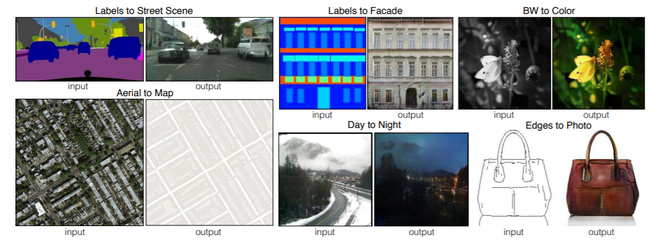
pix2pix был предложен исследователями из Калифорнийского университета в Беркли в 2017 году. Он использует условную генеративную состязательную сеть для выполнения задачи преобразования изображения в изображение (т. е. преобразования одного изображения в другое, таких фасадов в здания и карт Google в Google Планета Земля и т. д.
Архитектура :
Pix2pix использует в своей архитектуре условные генерирующие состязательные сети (условно-GAN). Причина этого в том, что даже если мы обучим модель с простой функцией потерь L1 / L2 для конкретной задачи преобразования изображения в изображение, это может не понять нюансов изображений.
Генератор:
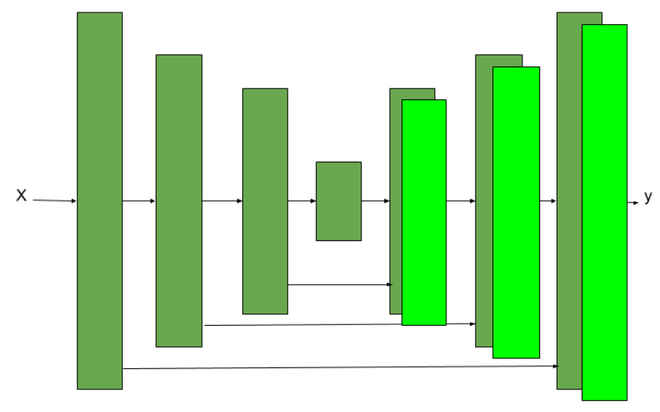
U-Net architecture
В генераторе использовалась архитектура U-Net. Она похожа на архитектуру кодировщика-декодера, за исключением использования пропускаемых соединений в архитектуре кодировщика-декодера. Использование skip-соединения делает это
- Архитектура кодировщика: кодировщик сеть Генератора сеть имеет семь сверточных блоков. Каждый сверточный блок имеет сверточный слой, за которым следует функция активации LeakyRelu (с наклоном 0,2 в документе). Каждый сверточный блок также имеет слой пакетной нормализации, за исключением первого сверточного слоя.
- Архитектура декодера: декодер сеть Генератора сеть имеет семь сверточных блоков транспонирования. Каждый сверточный блок с повышающей дискретизацией (Dconv) имеет уровень повышающей дискретизации, за которым следует сверточный слой, уровень пакетной нормализации и функция активации ReLU.
- Архитектура генератора содержит пропускаемые соединения между каждым слоем i и слоем n - i , где n - общее количество уровней. Каждое пропускаемое соединение просто объединяет все каналы на уровне i с каналами на уровне n - i.
Дискриминатор:
Патч-дискриминатор GAN
Дискриминатор использует архитектуру Patch GAN, которая также используется в архитектуре Style GAN. Эта архитектура PatchGAN содержит ряд сверточных блоков транспонирования. Эта архитектура PatchGAN берет часть изображения NxN и пытается определить, настоящая она или фальшивая. Этот дискриминатор применяется сверточно ко всему изображению, усредняя его для получения результата дискриминатора D.
Каждый блок дискриминатора содержит слой свертки, слой пакетной нормы и LeakyReLU. Этот дискриминатор получает два входа:
- Входное изображение и целевое изображение (которое дискриминатор должен классифицировать как реальный)
- Входное изображение и сгенерированное изображение (которое дискриминатор должен классифицировать как поддельный).
PatchGAN используется потому, что автор утверждает, что он сможет сохранить высокочастотные детали изображения с низкочастотными деталями, которые могут быть сфокусированы с помощью потери L1.
Потери в генераторе:
Потери генератора, используемые в статье, представляют собой линейную комбинацию потерь L1 между сгенерированным изображением, целевым изображением и потерями GAN, как мы определили выше.
Наши убытки будут:
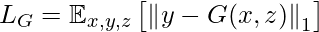
Таким образом, наши общие потери для генератора
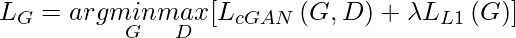
Потеря дискриминатора
Потеря дискриминатора принимает два входа: реальное изображение и сгенерированное изображение:
- real_loss - это сигмовидная кросс-энтропийная потеря реальных изображений и массива из них (поскольку это реальные изображения).
- created_loss - сигмоидальная кросс-энтропийная потеря сгенерированных изображений и массив нулей (поскольку это поддельные изображения)
- Общий убыток - это сумма real_loss и generated_loss.
Реализация:
- Сначала мы загружаем и предварительно обрабатываем набор данных изображения. Мы будем использовать набор данных CMP Facade, предоставленный Чешским техническим университетом и обработанный авторами статьи pix2pix. Мы предварительно обработаем набор данных перед обучением.
Код:
# import necessary packagesimport tensorflow as tf import ostime import from matplotlib import pyplot as pltfrom display import IPython# install tenosrboard ! pip install -U tensorboard # download datasetURL = " https://people.eecs.berkeley.edu/ ~tinghuiz / projects / pix2pix / datasets / facades.tar.gz" path_to_zip = tf.keras.utils.get_file( 'facades.tar.gz' , origin = URL, extract = True ) PATH = os.path.join(os.path.dirname(path_to_zip), 'facades/' ) # Define Training variableBUFFER_SIZE = 400BATCH_SIZE = 1IMG_WIDTH = 256IMG_HEIGHT = 256 # load the images from datasetdef load(image_file): image = tf.io.read_file(image_file) image = tf.image.decode_jpeg(image) w = tf.shape(image)[ 1 ] w = w / / 2 real_image = image[:, :w, :] input_image = image[:, w:, :] input_image = tf.cast(input_image, tf.float32) real_image = tf.cast(real_image, tf.float32) return input_image, real_image # resize the images to provided width and hightdef resize(input_image, real_image, height, width): input_image = tf.image.resize(input_image, [height, width], method = tf.image.ResizeMethod.NEAREST_NEIGHBOR) real_image = tf.image.resize(real_image, [height, width], method = tf.image.ResizeMethod.NEAREST_NEIGHBOR) return input_image, real_image """function to stack (input, real) images and apply random crop on them to cropto (256, 256)"""def random_crop(input_image, real_image): stacked_image = tf.stack([input_image, real_image], axis = 0 ) cropped_image = tf.image.random_crop( stacked_image, size = [ 2 , IMG_HEIGHT, IMG_WIDTH, 3 ]) return cropped_image[ 0 ], cropped_image[ 1 ] """Before training, we need to perform random jittering on the datasetAccording to the paper, this random jittering contains 3 steps --> Resize the image to bigger size --> Random crop the image to target size of model --> Random Flip on the images """ @tf .function()def random_jitter(input_image, real_image): # resizing to 286 x 286 x 3 input_image, real_image = resize(input_image, real_image, 286 , 286 ) # randomly cropping to 256 x 256 x 3 input_image, real_image = random_crop(input_image, real_image) if tf.random.uniform(()) > 0.5 : # random mirroring input_image = tf.image.flip_left_right(input_image) real_image = tf.image.flip_left_right(real_image) return input_image, real_image |
- Теперь мы загружаем обучающие и тестовые данные, используя функцию, которую мы определили выше.
Код:
# function to Load image from train data"""On train data, we performed random jitter and normalize,but since we don't need any augmentation on test_data, we just resize it"""def load_image_train(image_file): input_image, real_image = load(image_file) input_image, real_image = random_jitter(input_image, real_image) input_image, real_image = normalize(input_image, real_image) return input_image, real_image# function to Load images from test datadef load_image_test(image_file): input_image, real_image = load(image_file) input_image, real_image = resize(input_image, real_image, IMG_HEIGHT, IMG_WIDTH) input_image, real_image = normalize(input_image, real_image) return input_image, real_image # apply the above load_images_train function on train datatrain_dataset = tf.data.Dataset.list_files(PATH + 'train/*.jpg' )train_dataset = train_dataset. map (load_image_train, num_parallel_calls = tf.data.experimental.AUTOTUNE)train_dataset = train_dataset.shuffle(BUFFER_SIZE)train_dataset = train_dataset.batch(BATCH_SIZE) # apply the above load_images_test function on test datatest_dataset = tf.data.Dataset.list_files(PATH + 'test/*.jpg' )test_dataset = test_dataset. map (load_image_test)test_dataset = test_dataset.batch(BATCH_SIZE) |
- После обработки данных мы пишем код для архитектуры генератора. Этот блок генератора содержит 2 части блока кодера и блока декодера. Блок кодера содержит блок свертки с понижающей дискретизацией, а блок декодера содержит блок свертки с транспонированием с повышением дискретизации.
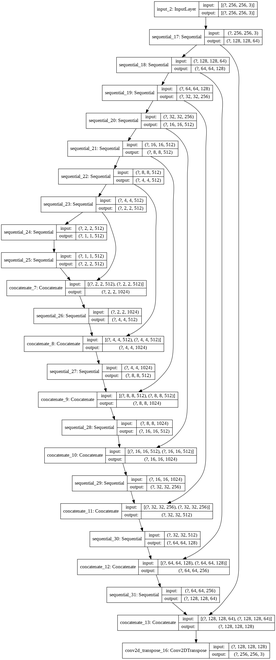
Генераторная архитектура
- Теперь мы определяем нашу архитектуру дискриминатора. Архитектура дискриминатора использует модель PatchGAN. Для этой архитектуры мы можем использовать указанный выше блок свертки с понижающей дискретизацией. Потеря дискриминатора представляет собой сумму реальных потерь (сигмоидная кросс-энтропия, ч / б реальное изображение и массив единиц) и генерируемых потерь (сигмоидная кросс-энтропия, ч / б сгенерированное изображение и массив нулей).
Код:
# code for discriminator architecture"""FOr more details look into architecture section"""def Discriminator(): initializer = tf.random_normal_initializer( 0. , 0.02 ) inp = tf.keras.layers. Input (shape = [ 256 , 256 , 3 ], name = 'input_image' ) tar = tf.keras.layers. Input (shape = [ 256 , 256 , 3 ], name = 'target_image' ) x = tf.keras.layers.concatenate([inp, tar]) # (batch_size, 256, 256, channels * 2) down1 = downsample( 64 , 4 , False )(x) # (batch_size, 128, 128, 64) down2 = downsample( 128 , 4 )(down1) # (batch_size, 64, 64, 128) down3 = downsample( 256 , 4 )(down2) # (batch_size, 32, 32, 256) zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (batch_size, 34, 34, 256) conv = tf.keras.layers.Conv2D( 512 , 4 , strides = 1 , kernel_initializer = initializer, use_bias = False )(zero_pad1) # (batch_size, 31, 31, 512) batchnorm1 = tf.keras.layers.BatchNormalization()(conv) leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1) zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (batch_size, 33, 33, 512) last = tf.keras.layers.Conv2D( 1 , 4 , strides = 1 , kernel_initializer = initializer)(zero_pad2) # (batch_size, 30, 30, 1) return tf.keras.Model(inputs = [inp, tar], outputs = last) # define discriminator loss functiondisc_ce_loss = tf.keras.losses.BinaryCrossentropy(from_logits = True )def discriminator_loss(disc_real_output, disc_generated_output): real_loss = disc_ce_loss(tf.ones_like(disc_real_output), disc_real_output) generated_loss = disc_ce_loss(tf.zeros_like(disc_generated_output), disc_generated_output) total_disc_loss = real_loss + generated_loss return total_disc_loss discriminator = Discriminator()tf.keras.utils.plot_model(discriminator, show_shapes = True ) |
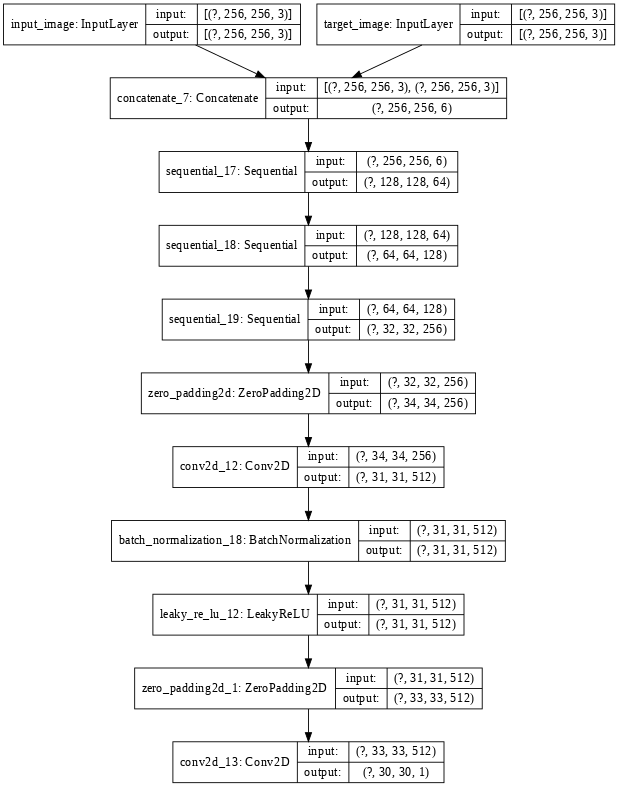
Дискриминаторная архитектура
- На этом этапе мы определяем оптимизаторы и контрольные точки. Мы будем использовать оптимизатор Adam в дискриминаторе обоих генераторов.
Код:
# define generator and discriminator architecturegenerator_optimizer = tf.keras.optimizers.Adam( 2e - 4 , beta_1 = 0.5 )discriminator_optimizer = tf.keras.optimizers.Adam( 2e - 4 , beta_1 = 0.5 ) # Create the model checkpointcheckpoint_dir = './train_checkpoints'checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt" )checkpoint = tf.train.Checkpoint(generator_optimizer = generator_optimizer, discriminator_optimizer = discriminator_optimizer, generator = generator, discriminator = discriminator) |
- Теперь мы определяем процедуру обучения. Процедура обучения состоит из следующих этапов:
- Для каждого примера ввода мы передали изображение в качестве ввода в генератор, чтобы получить сгенерированное изображение.
- Дискриминатор получает input_image и сгенерированное изображение в качестве первого входа. Второй вход - это input_image и target_image.
- Далее рассчитываем генератор и потери дискриминатора.
- Затем мы вычисляем градиенты потерь как для генератора, так и для переменных дискриминатора (входных данных) и применяем их к оптимизатору.
Код:
# Define training procedureEPOCHS = 30 datetime importlog_dir = "logs/" summary_writer = tf.summary.create_file_writer( log_dir + "fit/" + datetime.datetime.now().strftime( "% Y % m % d-% H % M % S" )) @tf .functiondef train_step(input_image, target, epoch): with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape: gen_output = generator(input_image, training = True ) disc_real_output = discriminator([input_image, target], training = True ) disc_generated_output = discriminator([input_image, gen_output], training = True ) gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target) disc_loss = discriminator_loss(disc_real_output, disc_generated_output) generator_gradients = gen_tape.gradient(gen_total_loss, generator.trainable_variables) discriminator_gradients = disc_tape.gradient(disc_loss, discriminator.trainable_variables) generator_optimizer.apply_gradients( zip (generator_gradients, generator.trainable_variables)) discriminator_optimizer.apply_gradients( zip (discriminator_gradients, discriminator.trainable_variables)) with summary_writer.as_default(): tf.summary.scalar( 'gen_total_loss' , gen_total_loss, step = epoch) tf.summary.scalar( 'gen_gan_loss' , gen_gan_loss, step = epoch) tf.summary.scalar( 'gen_l1_loss' , gen_l1_loss, step = epoch) tf.summary.scalar( 'disc_loss' , disc_loss, step = epoch) def fit(train_ds, epochs, test_ds): for epoch in range (epochs): % time for example_input, example_target in test_ds.take( 1 ): generate_images(generator, example_input, example_target) print ( "Epoch: " , epoch) # Train for n, (input_image, target) in train_ds. enumerate (): train_step(input_image, target, epoch) print () # saving (checkpoint) the model every 10 epochs if (epoch + 1 ) % 10 = = 0 : checkpoint.save(file_prefix = checkpoint_prefix) checkpoint.save(file_prefix = checkpoint_prefix)fit(train_dataset, EPOCHS, test_dataset) |
- Теперь мы используем генератор обученной модели на тестовых данных для генерации изображений.
Код:
# code to plot resultsdef generate_images(model, test_input, tar): prediction = model(test_input, training = True ) plt.figure(figsize = ( 15 , 15 )) display_list = [test_input[ 0 ], tar[ 0 ], prediction[ 0 ]] title = [ 'Input Image' , 'Ground Truth' , 'Predicted Image' ] for i in range ( 3 ): plt.subplot( 1 , 3 , i + 1 ) plt.title(title[i]) # getting the pixel values between [0, 1] to plot it. plt.imshow(display_list[i] * 0.5 + 0.5 ) plt.axis( 'off' ) plt.show() for inputs, tar in test_dataset.take( 5 ): generate_images(generator, inputs, tar) |


Полученные результаты
Использованная литература:
- Бумага Pix2Pix
- Реализация TensorFlow на Pix2pix
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.