Преобразование Бокса-Кокса с использованием Python
Представьте, что вы смотрите скачки и, как и в любой другой гонке, есть быстрые и медленные бегуны. Таким образом, логически говоря, лошадь, которая пришла первой, и быстрые лошади вместе с ней будут иметь одинаковую разницу во времени завершения, тогда как самые медленные будут иметь большую разницу во времени завершения.
Мы можем связать это с очень известным термином в статистике, называемым дисперсией, который относится к тому, насколько данные изменяются относительно среднего значения. Здесь, в нашем примере, существует несогласованная разница (гетероскедастичность) между быстрыми и медленными лошадьми, потому что будут небольшие различия для более короткого времени завершения и наоборот.
Следовательно, распределение наших данных не будет колоколообразным или нормально распределенным, так как с правой стороны будет более длинный хвост. Эти типы распределений следуют степенному закону или правилу 80-20, где относительное изменение одной величины изменяется в зависимости от степени другой.
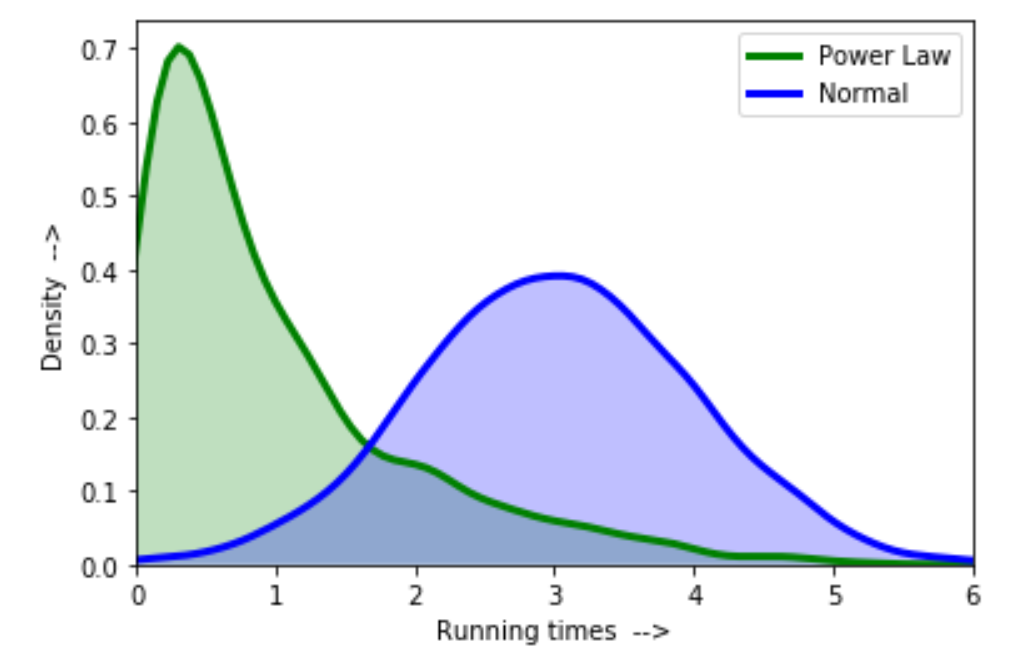
На приведенном выше графике мы можем видеть степенное распределение, которое достигает пика при коротком времени работы из-за небольшой дисперсии и тяжелого хвоста из-за более длительного времени работы. Эти степенные распределения используются в области физики, биологии, экономики и т. Д.
Итак, просто подумайте на секунду, что если эти распределения встречаются во многих областях, что, если мы могли бы преобразовать их в более удобное распределение, такое как нормальное распределение? Это сделало бы нашу жизнь намного проще. К счастью, у нас есть способ преобразовать степенное или любое нелинейное распределение в нормальное с помощью преобразования Бокса-Кокса.
Давайте интуитивно подумаем, что если бы мы сами сделали это преобразование, как бы мы поступили?
Из показанного выше рисунка ясно, что если бы мы каким-то образом могли увеличить изменчивость для левой части ненормального распределения, то есть пика, и уменьшить изменчивость на хвостах. Короче говоря, пытаясь переместить пик к центру, мы можем получить кривую, близкую к колоколообразной кривой.
Формально преобразование Бокса-Кокса определяется как способ преобразования ненормальных зависимых переменных в наших данных в нормальную форму, с помощью которой мы можем запускать гораздо больше тестов, чем могли бы.
Математика преобразования Бокса-Кокса
Как мы можем преобразовать наше интуитивное мышление в функцию математического преобразования? Все, что нам нужно - это логарифмическое преобразование. Когда логарифмическое преобразование применяется к ненормальному распределению, оно пытается расширить различия между меньшими значениями, потому что наклон для логарифмической функции более крутой для меньших значений, тогда как различия между большими значениями могут быть уменьшены, потому что для больших значений Распределение бревен имеет умеренный уклон. Это то, что мы думали сделать, верно?
Преобразование Бокса-Кокса заботится только о вычислении ценности 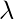 который варьируется от - 5 до 5. Значение считается лучшим, если он может аппроксимировать ненормальную кривую к нормальной кривой. Уравнение преобразования выглядит следующим образом:
который варьируется от - 5 до 5. Значение считается лучшим, если он может аппроксимировать ненормальную кривую к нормальной кривой. Уравнение преобразования выглядит следующим образом:
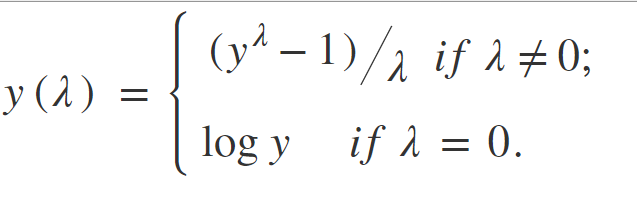
Эта функция требует, чтобы вход был положительным. Использование этой формулы вручную - очень трудоемкая задача, поэтому многие популярные библиотеки предоставляют эту функцию.
Выполнение
Пакет статистики SciPy предоставляет функцию, называемую boxcox для выполнения преобразования мощности box-cox, которая принимает исходные ненормальные данные в качестве входных и возвращает подогнанные данные вместе со значением лямбда, которое использовалось для соответствия ненормального распределения нормальному распределению.
Ниже приведен код того же.
Пример:
# Python3 code to show Box-cox Transformation# of non-normal data # import modulesimport numpy as npfrom scipy import stats # plotting modulesimport seaborn as snsimport matplotlib.pyplot as plt # generate non-normal data (exponential)original_data = np.random.exponential(size = 1000 ) # transform training data & save lambda valuefitted_data, fitted_lambda = stats.boxcox(original_data) # creating axes to draw plotsfig, ax = plt.subplots( 1 , 2 ) # plotting the original data(non-normal) and# fitted data (normal)sns.distplot(original_data, hist = False , kde = True , kde_kws = { 'shade' : True , 'linewidth' : 2 }, label = "Non-Normal" , color = "green" , ax = ax[ 0 ]) sns.distplot(fitted_data, hist = False , kde = True , kde_kws = { 'shade' : True , 'linewidth' : 2 }, label = "Normal" , color = "green" , ax = ax[ 1 ]) # adding legends to the subplotsplt.legend(loc = "upper right" ) # rescaling the subplotsfig.set_figheight( 5 )fig.set_figwidth( 10 ) print (f "Lambda value used for Transformation: {fitted_lambda}" ) |
Выход:
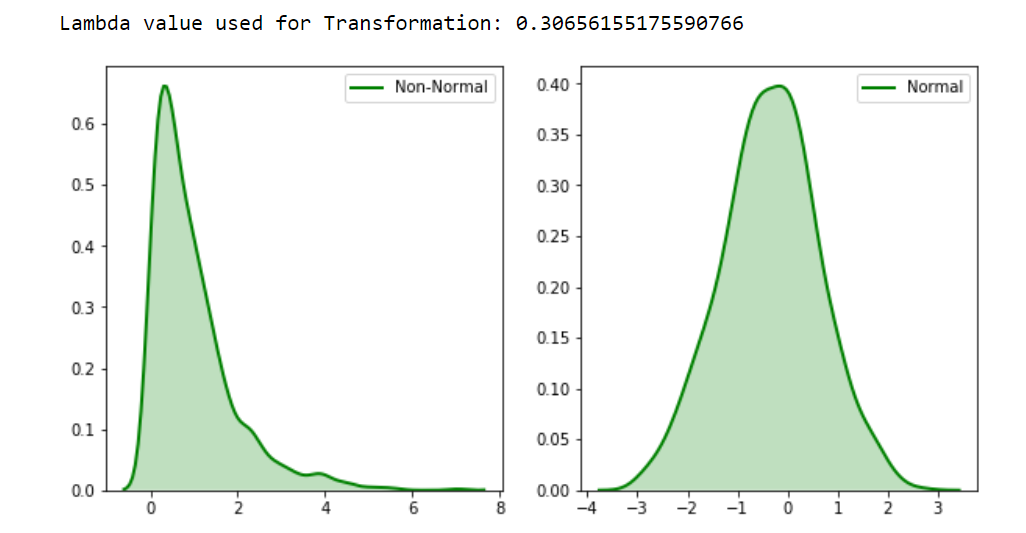
Мы видим, что ненормальное распределение было преобразовано в нормальное или довольно близкое к нормальному с помощью SciPy.stats.boxcox() .
Бокс-кокс всегда работает?
Ответ - НЕТ . Box-cox не гарантирует нормальности, потому что он никогда не проверяет нормальность, которая необходима для защиты от дурака, правильно ли он преобразовал ненормальное распределение или нет. Он проверяет только наименьшее стандартное отклонение.
Следовательно, абсолютно необходимо всегда проверять преобразованные данные на нормальность с помощью вероятностного графика.