Понимание типов средств | Комплект 1
Опубликовано: 25 Июля, 2021
Это одно из важнейших понятий статистики, важнейший предмет для изучения машинного обучения.
- Среднее арифметическое: это математическое ожидание дискретного набора чисел или среднего.
Обозначается X̂ , произносится как «x-bar». Это сумма всех дискретных значений в наборе, деленная на общее количество значений в наборе.
Формула для вычисления среднего из n значений - x 1 , x 2 ,… .. x n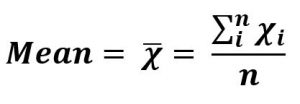
Пример -Последовательность = {1, 5, 6, 4, 4} Сумма = 20 n, Всего значений = 5 Среднее арифметическое = 20/5 = 4Код -
# Arithmetic Meanstatisticsimport# discrete set of numbersdata1=[1,5,6,4,4]x=statistics.mean(data1)# Meanprint("Mean is :", x)Выход :
Среднее значение: 4
- Усеченное среднее: на среднее арифметическое влияют выбросы (экстремальные значения) в данных. Таким образом, усеченное среднее значение используется во время предварительной обработки, когда мы обрабатываем такие данные в машинном обучении.
Это арифметика, имеющая вариацию, то есть она вычисляется путем отбрасывания фиксированного количества отсортированных значений с каждого конца последовательности данных, а затем вычисляется среднее (среднее) оставшихся значений.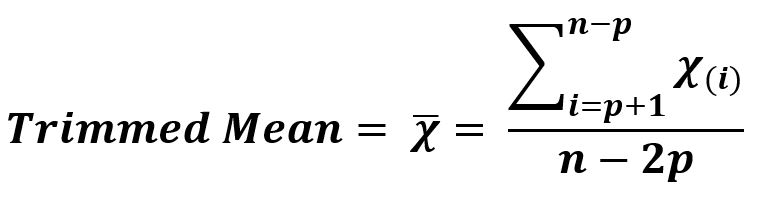
Пример -
Последовательность = {0, 2, 1, 3} р = 0,25 Оставшийся секвемс = {2, 1} n, Всего значений = 2 Среднее = 3/2 = 1,5Код -
# Trimmed Meanfromscipyimportstats# discrete set of numbersdata=[0,2,1,3]x=stats.trim_mean(data,0.25)# Meanprint("Trimmed Mean is :", x)Выход :
Среднее усеченное значение: 1,5
- Средневзвешенное значение: среднее арифметическое или усеченное среднее значение придает одинаковую важность всем задействованным параметрам. Но всякий раз, когда мы работаем с предсказаниями машинного обучения, существует вероятность того, что некоторые значения параметров имеют большее значение, чем другие, поэтому мы присваиваем значениям таких параметров большие веса. Кроме того, может быть вероятность, что наш набор данных имеет сильно изменяющееся значение параметра, поэтому мы присваиваем меньшие веса значениям таких параметров.
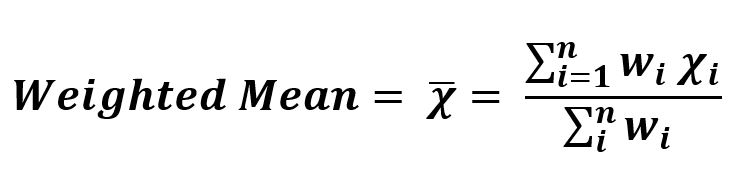
Пример -Последовательность = [0, 2, 1, 3] Вес = [1, 0, 1, 1] Сумма (Вес * последовательность) = 0 * 1 + 2 * 0 + 1 * 1 + 3 * 1 Сумма (Вес) = 3 Средневзвешенное значение = 4/3 = 1,3333333333333333
Код 1 -
# Weighted Meanimportnumpy as np# discrete set of numbersdata=[0,2,1,3]x=np.average(data, weights=[1,0,1,1])# Meanprint("Weighted Mean is :", x)Выход 1:
Средневзвешенное значение: 1,3333333333333333
Код 2 -
# Weighted Meandata=[0,2,1,3]weights=[1,0,1,1]x=sum(data[i]*weights[i]foriinrange(len(data)))/sum(weights)print("Weighted Mean is :", x)Выход 2:
Средневзвешенное значение: 1,3333333333333333
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.