Параметры высокой доступности с Microsoft Windows Server 2008 Hyper-V
Зачем мне нужна высокая доступность?
Решения высокой доступности предоставляют способы управления как запланированными, так и незапланированными простоями. Некоторые примеры планового простоя включают установку обновлений операционной системы или приложений, требующих отключения сервера. Незапланированные простои могут быть вызваны простым отказом аппаратного компонента или потерей физических серверов из-за стихийного бедствия. В крупных масштабах построение стратегии высокой доступности включает в себя комплексное исследование всех взаимосвязанных компонентов, которые предоставляют пользователям доступ к услугам, и может потребовать внедрения более одного решения для достижения целевых показателей доступности.
В то время как виртуализация серверов предоставляет организациям решение для внедрения динамической, гибкой базовой инфраструктуры, которая сводит к минимуму количество развернутых физических серверов, увеличивает использование физических ресурсов и снижает долгосрочные эксплуатационные расходы, миграция нескольких физических серверов на общий хост виртуализации требует более широкой стратегии обеспечения высокой доступности, чем в традиционной инфраструктуре. Если один или несколько хостов виртуализации находятся в состоянии простоя, это может повлиять на большое количество пользователей, которые потеряют доступ к службам и приложениям, что приведет к потере производительности и финансовым последствиям для организации. На аппаратном уровне развертывание хостов виртуализации на платформах, которые содержат избыточные компоненты или компоненты с возможностью горячей замены (например, блоки питания, процессоры и память), снижает риск незапланированных простоев. В Windows Server 2008 также есть возможность использовать встроенную функцию отказоустойчивого кластера для управления как незапланированными, так и запланированными простоями хостов и гостей виртуализации.
Отказоустойчивая кластеризация Windows Server 2008
Отказоустойчивая кластеризация была компонентом серверных продуктов Microsoft Windows, начиная с NT 4.0. С тех пор компонент отказоустойчивого кластера претерпел значительные изменения, особенно с точки зрения простоты настройки и поддерживаемых приложений. Если вы используете Windows Server 2008 с Hyper-V в качестве платформы виртуализации, вы можете интегрировать отказоустойчивый кластер как часть своей стратегии обеспечения высокой доступности для виртуализированной инфраструктуры. Отказоустойчивый кластер Windows Server 2008 состоит как минимум из двух серверов (узлов), соединенных несколькими сетевыми каналами, один из которых позволяет отслеживать состояние каждого узла. Каждый узел отказоустойчивого кластера подключен к общему массиву хранения, например к сети хранения данных (SAN), и только один узел в кластере может одновременно владеть набором сетевых и дисковых ресурсов, связанных с приложением или службой. Что касается масштаба, отказоустойчивый кластер Windows Server 2008 может содержать до 16 узлов. Узлы контролируют друг друга, используя пульс сети, чтобы определить, отвечают ли узлы. Если узел перестает отвечать на запросы, приложение или служба, работающие на отказавшем узле кластера, будут перезапущены на другом узле кластера после того, как они станут владельцами ресурсов. Начиная с Windows Server 2008, географически распределенные (или растянутые) кластеры также могут быть реализованы без специального или специализированного оборудования. Это дает вам возможность реализовать отказоустойчивый кластер, который может управлять незапланированными простоями путем переключения на другой локальный узел в случае сбоя одного сервера или на узел в другом географическом регионе в случае более серьезного локального сбоя, такого как что может быть вызвано длительным отключением электроэнергии, стихийным бедствием или другой крупномасштабной проблемой.
Отказоустойчивая кластеризация Windows Server 2008 с Hyper-V
Использование отказоустойчивого кластера с Windows Server 2008 и Hyper-V дает возможность реализовать стратегию высокой доступности, которая может управлять как незапланированными, так и запланированными простоями в виртуализированной инфраструктуре. Существует два разных уровня, на которых вы можете реализовать отказоустойчивый кластер в среде Hyper-V: на уровне хоста виртуализации и на уровне гостевой операционной системы.
Вариант 1. Отказоустойчивый кластер гостевой операционной системы
Как показано на рис. 1, отказоустойчивый кластер гостевой операционной системы реализуется между двумя или более виртуальными машинами, работающими на отдельных хостах Hyper-V и подключенными к общей системе хранения. Чтобы реализовать этот вариант, на виртуальной машине необходимо запустить операционную систему, поддерживающую отказоустойчивую кластеризацию, например Windows Server 2003 R2 (до 8 узлов) или Windows Server 2008 Enterprise или Datacenter (до 16 узлов). Кроме того, приложение, которое вы собираетесь сделать высокодоступным, должно быть «поддерживающим кластер». Это означает, что приложение было разработано с определенными функциями, которые позволяют ему взаимодействовать со службой кластера и обеспечивают отработку отказа и перезапуск со всеми необходимыми ресурсами на другом узле кластера.
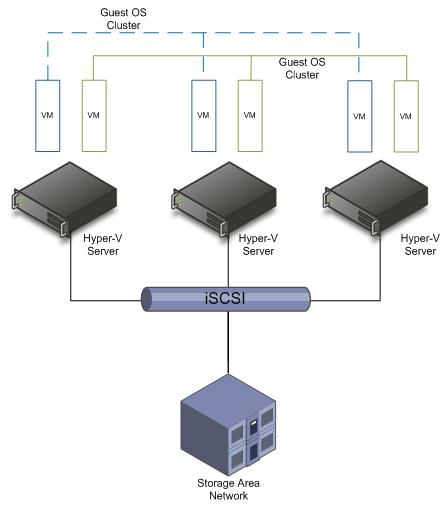
Рис. 1. Отказоустойчивый кластер гостевой операционной системы
Если вы планируете отказоустойчивый кластер гостевой операционной системы, iSCSI является единственным протоколом доступа к общему хранилищу, который поддерживается для этой конфигурации. Протокол iSCSI позволяет передавать и получать данные блочного хранилища по сети TCP/IP. Чтобы использовать iSCSI и максимизировать производительность, необходимо выделить виртуальный сетевой адаптер на каждой виртуальной машине для связи iSCSI. Вы также должны выделить одну или несколько физических сетевых карт и настроить отдельные виртуальные сети на каждом хосте Hyper-V для доступа к хранилищу iSCSI. Вам потребуется установить инициатор iSCSI на каждой виртуальной машине для доступа к целям на основе iSCSI в общем хранилище. Инициатор iSCSI — это программный компонент, который обеспечивает подключение хоста Windows к внешнему массиву хранения iSCSI по сети TCP/IP. Важно отметить, что эта конфигурация не поддерживает прямое подключение цели iSCSI к виртуальной машине в качестве загрузочного устройства. Инициатор Microsoft iSCSI входит в состав Windows Server 2008, но его необходимо загрузить для Windows Server 2003 и более ранних версий.
Отказоустойчивый кластер гостевой операционной системы поддерживает плановые и незапланированные простои приложений, поддерживающих кластер. Фактически эта конфигурация будет управлять незапланированными простоями, вызванными сбоем или сбоем, происходящим внутри виртуальной машины, а также сбоем или сбоем, происходящим на уровне хост-платформы Hyper-V.
Вариант 2. Отказоустойчивый кластер узла Hyper-V
Второй вариант отказоустойчивого кластера состоит из двух или более серверов Windows Server 2008 с установленной ролью Hyper-V, каждый из которых настроен как узел кластера и подключен к общей системе хранения. Отказоустойчивый кластер узла Hyper-V показан на рис. 2. Эта конфигурация кластера позволяет достичь высокой доступности для приложений, не поддерживающих кластер, работающих на виртуальных машинах, и поддерживает запланированные и незапланированные простои узлов Hyper-V. Напротив, сбой или сбой гостевой операционной системы или приложения не приведет к аварийному переключению.
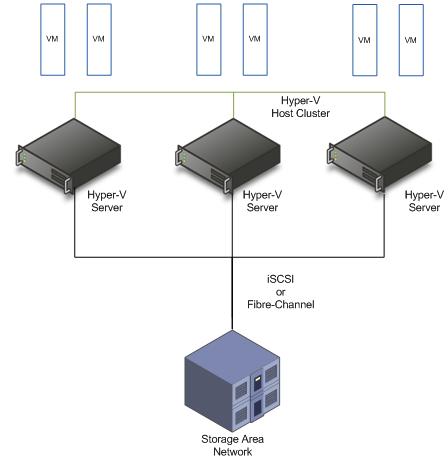
Рис. 2. Отказоустойчивый кластер узла Hyper-V
Одним из преимуществ отказоустойчивого кластера узла Hyper-V является то, что вы не ограничены использованием iSCSI для подключения к общей системе хранения. В этой конфигурации вы можете использовать подключенное общее хранилище iSCSI или Fibre-Channel, даже файловый сервер, использующий протоколы CIFS или SMB. Существует довольно много различных конфигураций хранилища, которые вы можете настроить в этом сценарии в зависимости от требований вашей среды. Эти конфигурации будут рассмотрены в следующей статье.
Запланированный и незапланированный процесс аварийного переключения
В запланированном сценарии аварийного переключения, основанном на необходимости выполнения обслуживания узла Hyper-V или перераспределения нагрузки между узлами Hyper-V посредством быстрой миграции виртуальной машины, процесс миграции может происходить без потери данных и с минимальным обслуживанием. прерывание. Для этого виртуальная машина помещается в сохраненное состояние, в результате чего активная память и состояние процессора записываются на диск, а обработка приостанавливается. По сути, право собственности на ресурсы хранения передается целевому узлу кластера, активная память и состояние процессора загружаются, и обработка возобновляется. В зависимости от базового хранилища и размера перезагружаемых данных состояния весь процесс может занять несколько секунд.
В случае незапланированного аварийного переключения, вызванного аппаратной проблемой или другой непредвиденной проблемой, происходит сбой узла Hyper-V вместе со всеми виртуальными машинами. Поскольку виртуальные машины аварийно завершают работу до того, как состояние может быть сохранено, в процессе миграции теряются данные в активной памяти. Однако, поскольку узел Hyper-V является частью отказоустойчивого кластера, право собственности на ресурсы хранения будет передано другому узлу кластера, а виртуальные машины будут перезапущены на этом узле Hyper-V.
Вывод
В этой статье вы узнали, почему важно пересмотреть свою стратегию обеспечения высокой доступности при переходе от физической к виртуализированной инфраструктуре. В частности, вы узнали, как можно использовать Hyper-V в сочетании с технологией отказоустойчивого кластера в Windows Server 2008 для создания решений высокой доступности как для кластерных, так и для некластерных приложений, работающих на виртуальных машинах. Эти решения способны управлять как запланированными, так и незапланированными сценариями простоя, так что у вас есть возможность выполнять обслуживание хоста Hyper-V, перераспределять нагрузку между хостами Hyper-V и устранять сбои физических серверов, сводя к минимуму сбои в работе критически важных приложений и служб.