Пакет Snakebite Python для Hadoop HDFS
Предварительные требования: Hadoop и HDFS
Snakebite - очень популярный пакет Python, который позволяет пользователям получать доступ к HDFS с помощью какой-либо программы с приложением Python. Пакет Snakebite Python разработан Spotify. Snakebite также предоставляет клиентскую библиотеку Python. Сообщения protobuf используются клиентской библиотекой snakebite для прямого взаимодействия с NameNode, в котором хранятся все метаданные. Все права доступа к файлам, журналы, место, где создаются блоки данных, относятся к метаданным. Интерфейс командной строки, то есть интерфейс командной строки, также доступен в этом пакете snakebite python, который основан на клиентской библиотеке.
Давайте обсудим, как установить и настроить пакет snakebite для HDFS.
Требование:
- Python 2 и python-protobuf 2.4.1 или выше требуются для snakebite.
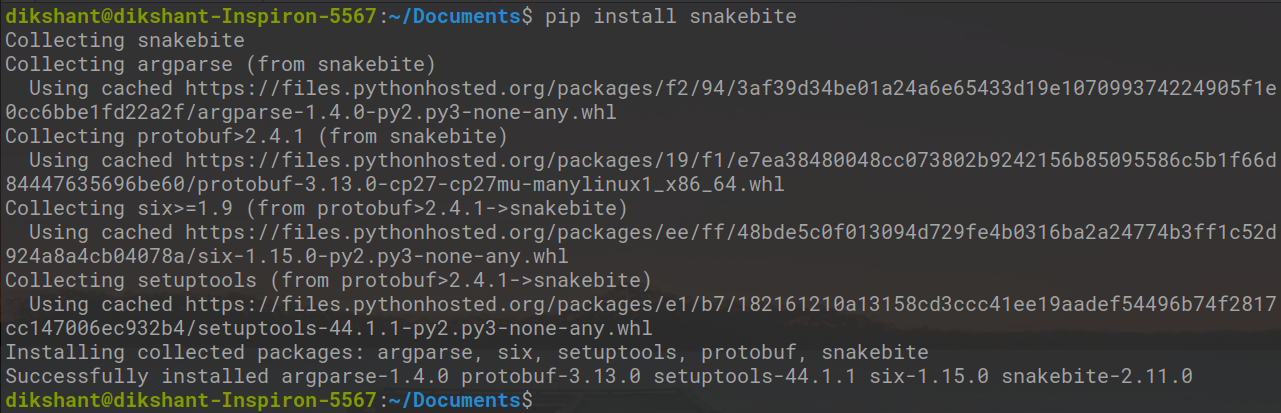
Библиотеку snakebite можно легко установить с помощью pip .
# Make sure you have pip for python version 2 otherwise you will face error while importing module pip install snakebite
У нас уже есть укус змеи, поэтому требование выполнено.
Клиентская библиотека
Клиентская библиотека построена с использованием Python и использует протокол Hadoop RPC и сообщения protobuf для связи с NameNode, который обрабатывает все метаданные кластера. С помощью этой клиентской библиотеки приложения Python взаимодействуют напрямую с HDFS, то есть с распределенной файловой системой Hadoop, без подключения к dfs hdfs с помощью системный вызов.
Давайте напишем одну простую программу на Python, чтобы понять, как работает пакет python snakebite.
Задача: составить список всего содержимого корневого каталога HDFS с помощью клиентской библиотеки Snakebite.
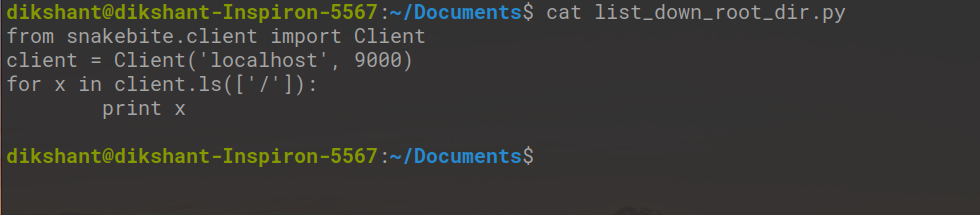
Шаг 1. Создайте файл python с именем list_down_root_dir.py в желаемом месте в системе.
cd Documents / # Изменение каталога на документы (вы можете выбрать в соответствии с вашими требованиями) трогать list_down_root_dir.py Команда # touch используется для создания файла в среде Linux.

Step2: Write the below code in the list_down_root_dir.py python file.
Python
# importing the packagefrom snakebite.client import Client# the below line create client connection to the HDFS NameNodeclient = Client("localhost", 9000)# the loop iterate in root directory to list all the content for x in client.ls(["/"]): print x |
Описание метода Client ():
Метод Client () может принимать все перечисленные ниже аргументы:
- host (строка): IP-адрес NameNode.
- port (int): RPC-порт Namenode.
Мы можем проверить хост и порт по умолчанию в файле core-site.xml. Мы также можем настроить его в соответствии с нашими потребностями.
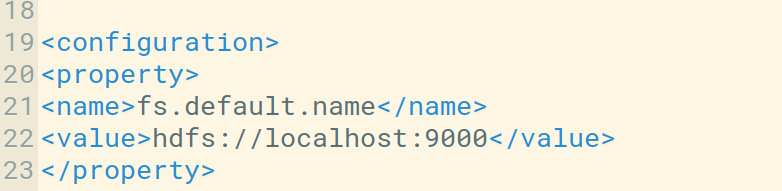
- hadoop_version (int): версия протокола Hadoop (по умолчанию: 9)
- use_trash (логическое значение): использовать корзину при удалении файлов.
- Effective_use (строка): эффективный пользователь для операций HDFS (пользователь по умолчанию - текущий пользователь).
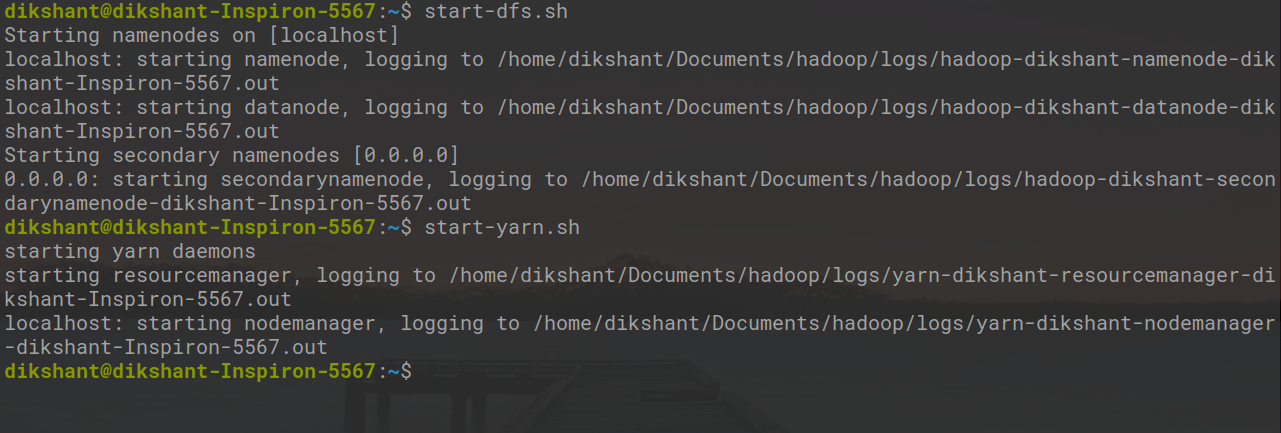
Шаг 3: Запустите Hadoop Daemon с помощью приведенной ниже команды .
start-dfs.sh // запускаем ваш namenode datanode и вторичный namenode start-yarn.sh // запускаем Resourcemanager и nodemanager
Шаг 4: Запустите файл list_down_root_dir.py и посмотрите на результат.
python list_down_root_dir.py
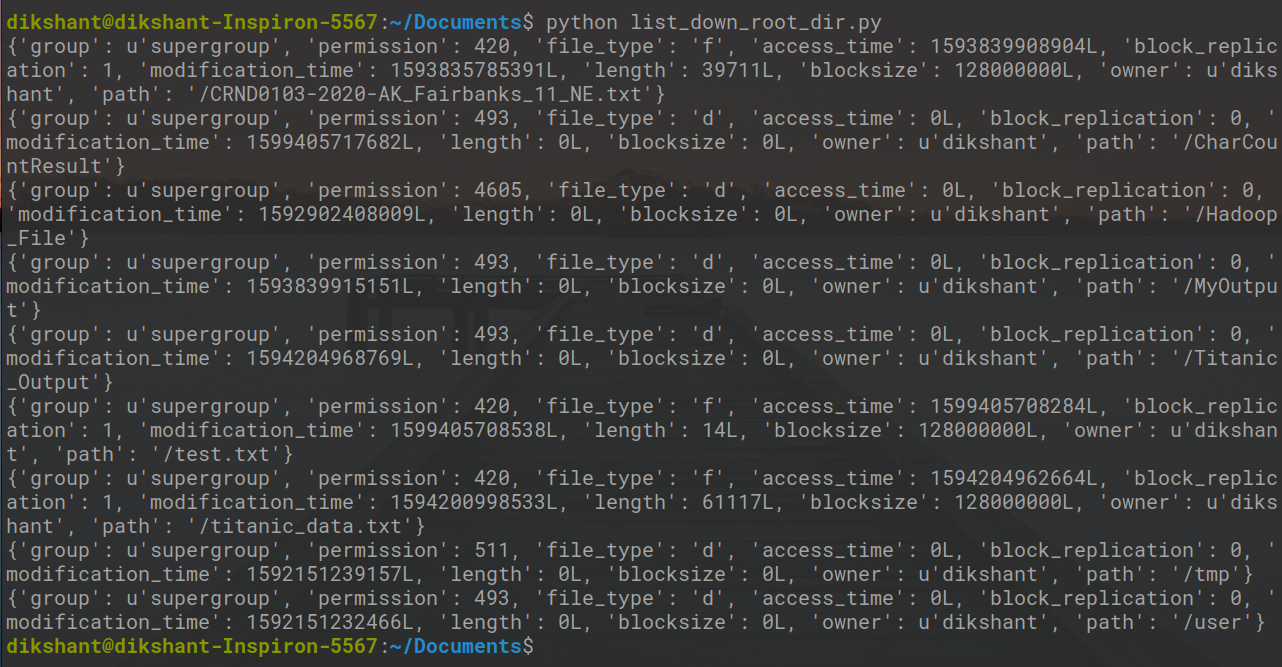
На изображении выше вы можете увидеть весь контент, доступный в корневом каталоге моей HDFS.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.