Оценка переменной | набор 2
Опубликовано: 25 Июля, 2021
Предпосылка: оценка переменной | набор 1
Термины, относящиеся к показателям изменчивости:
-> Отклонение -> Дисперсия -> Стандартное отклонение -> Среднее абсолютное отклонение -> Меадианское абсолютное отклонение -> Статистика заказов -> Диапазон -> Процентиль -> Межквартильный диапазон
- Среднее абсолютное отклонение: среднее абсолютное отклонение, дисперсия и стандартное отклонение (обсуждаемые в предыдущем разделе) не устойчивы к экстремальным значениям и выбросам. Мы усредняем сумму отклонений от медианы.
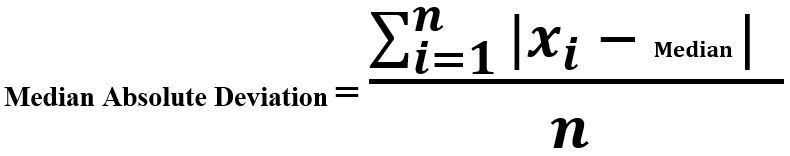
Пример :Последовательность: [2, 4, 6, 8] Среднее = 5 Отклонение от среднего значения = [-3, -1, 1, 3] Среднее абсолютное отклонение = (3 + 1 + 1 + 3) / 4
# Median Absolute Deviationimportnumpy as npdefmad(data):returnnp.median(np.absolute(data-np.median(data)))Sequence=[2,4,10,6,8,11]print("Median Absolute Deviation : ", mad(Sequence))Выход :
Среднее абсолютное отклонение: 3,0
- Статистика по порядку: этот подход к измерению изменчивости основан на разбросе ранжированных (отсортированных) данных.
- Диапазон: это самое основное измерение, относящееся к статистике заказов. Это разница между наибольшим и наименьшим значением набора данных. Хорошо знать разброс данных, но он очень чувствителен к выбросам. Мы можем улучшить его, отказавшись от крайних значений.
Пример :Последовательность: [2, 30, 50, 46, 37, 91] Здесь 2 и 91 - выбросы Диапазон = 91 - 2 = 89 Диапазон без выбросов = 50 - 30 = 20
- Процентиль: это очень хороший показатель для измерения изменчивости данных, избегая выбросов. P- й процентиль в данных - это такое значение, что, по крайней мере, значения P% или меньше меньше, чем оно, и, по крайней мере, значения (100 - P)% больше, чем P.
Медиана - это 50-й процентиль данных.
Пример :Последовательность: [2, 30, 50, 46, 37, 91] Сортировано: [2, 30, 37, 46, 50, 91] 50-й процентиль = (37 + 46) / 2 = 41,5
Код -
# Percentileimportnumpy as npSequence=[2,30,50,46,37,91]print("50th Percentile : ", np.percentile(Sequence,50))print("60th Percentile : ", np.percentile(Sequence,60))Выход :
50-й процентиль: 41,5 60-й процентиль: 46,0
- Межквартильный диапазон (IQR): работает для ранжированных (отсортированных данных). Данные разделяются на 3 квартиля - Q1 (25- й процентиль), Q2 (50- й процентиль) и Q3 (75- й процентиль). Межквартильный диапазон - это разница между Q3 и Q1.
Пример :
Последовательность: [2, 30, 50, 46, 37, 91] Q1 (25- й процентиль): 31,75 Второй квартал (50- й процентиль): 41,5 III квартал (75- й процентиль): 49 IQR = Q3 - Q1 = 17,25
Код - 1
# Inter-Quartile Rangeimportnumpy as npfromscipy.statsimportiqrSequence=[2,30,50,46,37,91]print("IQR : ", iqr(Sequence))Выход :
IQR: 17,25
Код - 2
importnumpy as np# Inter-Quartile Rangeiqr=np.subtract(*np.percentile(Sequence, [75,25]))print(" IQR : ", iqr)Выход :
IQR: 17,25
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.