Обработка данных в Python
Data Wrangling - это процесс сбора, сбора и преобразования необработанных данных в другой формат для лучшего понимания, принятия решений, доступа и анализа за меньшее время. Data Wrangling также известен как Data Munging.

Важность обработки данных
Data Wrangling - очень важный шаг. В следующем примере его важность объясняется следующим образом:
Сайт по продаже книг хочет показывать самые продаваемые книги из разных доменов в соответствии с предпочтениями пользователей. Например, новый пользователь ищет мотивационные книги, а затем хочет показать те мотивационные книги, которые продаются больше всего или имеют высокий рейтинг и т. Д.
Но на их сайте много необработанных данных от разных пользователей. Здесь используется концепция Data Munging или Data Wrangling. Как мы знаем, система не обрабатывает данные. Этим процессом занимаются специалисты по анализу данных. Итак, Data Scientist будет обрабатывать данные таким образом, что они будут отсортировать те мотивационные книги, которые продаются больше или имеют высокие рейтинги, или пользователи покупают эту книгу вместе с этим пакетом Книг и т. Д. На основе этого новый пользователь будет сделать выбор. Это объяснит важность обработки данных.
Обработка данных в Python
Data Wrangling - важная тема для науки о данных и анализа данных. Pandas Framework Python используется для обработки данных. Pandas - это библиотека с открытым исходным кодом, специально разработанная для анализа данных и науки о данных. Такие процессы, как сортировка или фильтрация данных, группировка данных и т. Д.
Обработка данных в Python имеет дело со следующими функциями:
- Исследование данных: в этом процессе данные изучаются, анализируются и понимаются путем визуализации представлений данных.
- Работа с пропущенными значениями: большинство наборов данных, содержащих огромное количество данных, содержат пропущенные значения NaN, о них необходимо позаботиться. заменив их на среднее значение, режим, наиболее частое значение столбца или просто отбросив строку, имеющую значение NaN.
- Изменение формы данных: в этом процессе данные обрабатываются в соответствии с требованиями, при этом можно добавлять новые данные или изменять уже существующие.
- Фильтрация данных: иногда наборы данных состоят из нежелательных строк или столбцов, которые необходимо удалить или отфильтровать.
- Другое: после работы с необработанным набором данных с указанными выше функциями мы получаем эффективный набор данных в соответствии с нашими требованиями, а затем его можно использовать для необходимых целей, таких как анализ данных, машинное обучение, визуализация данных, обучение модели и т. Д.
Ниже приведен пример, который реализует вышеуказанные функции в необработанном наборе данных:
- Исследование данных , здесь мы назначаем данные, а затем визуализируем данные в табличном формате.
Python3
# Import pandas packageimport pandas as pd # Assign datadata = { 'Name' : [ 'Jai' , 'Princi' , 'Gaurav' , 'Anuj' , 'Ravi' , 'Natasha' , 'Riya' ], 'Age' : [ 17 , 17 , 18 , 17 , 18 , 17 , 17 ], 'Gender' : [ 'M' , 'F' , 'M' , 'M' , 'M' , 'F' , 'F' ], 'Marks' : [ 90 , 76 , 'NaN' , 74 , 65 , 'NaN' , 71 ]} # Convert into DataFramedf = pd.DataFrame(data) # Display datadf |
Выход:
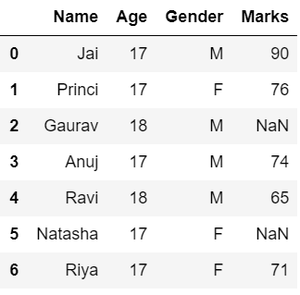
- Что касается пропущенных значений , как мы видим из предыдущего вывода, в столбце MARKS присутствуют значения NaN, о которых нужно позаботиться, заменив их средним значением столбца.
Python3
# Compute averagec = avg = 0for ele in df[ 'Marks' ]: if str (ele).isnumeric(): c + = 1 avg + = eleavg / = c # Replace missing valuesdf = df.replace(to_replace = "NaN" , value = avg) # Display datadf |
Выход:
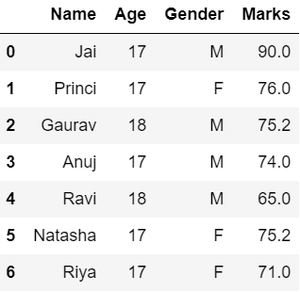
- Изменив форму данных в столбце «ПОЛ» , мы можем изменить форму данных, разделив их на разные числа.
Python3
# Categorize genderdf["Gender"] = df["Gender"].map({"M": 0, "F": 1, }).astype(float) # Display datadf |
Выход:
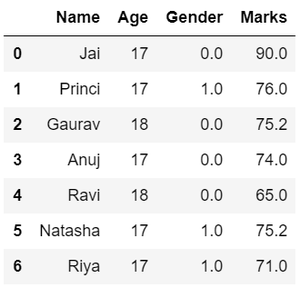
- Фильтрация данных. Предположим, есть требование о подробностях, касающихся имени, пола и оценок студентов, набравших наибольшее количество баллов. Здесь нам нужно удалить некоторые ненужные данные.
Python3
# Filter top scoring studentsdf = df[df[ 'Marks' ] > = 75 ] # Remove age rowdf = df.drop([ 'Age' ], axis = 1 ) # Display datadf |
Выход:
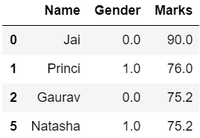
Таким образом, мы наконец получили эффективный набор данных, который в дальнейшем можно использовать для различных целей.
Теперь, когда мы знаем основы обработки данных. Ниже мы обсудим различные операции, с помощью которых мы можем выполнять обработку данных:
Обработка данных с помощью операции слияния
Операция слияния используется для слияния необработанных данных в желаемый формат.
Синтаксис:
pd.merge (кадр_данных1, кадр_данных2, on = "поле")
Здесь поле - это имя столбца, которое похоже на оба фрейма данных.
Например: предположим, что у учителя есть два типа данных, первый тип данных состоит из сведений об учащихся, а второй тип данных состоит из статуса незавершенных платежей, который берется из бухгалтерии. Таким образом, Учитель будет использовать здесь операцию слияния, чтобы объединить данные и придать им смысл. Так что учитель легко проанализирует это, и это также сократит время и усилия Учителя от ручного слияния.
ПЕРВЫЙ ТИП ДАННЫХ:
Python3
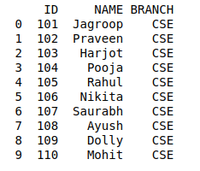
# import moduleimport pandas as pd # creating DataFrame for Student Detailsdetails = pd.DataFrame({ 'ID' : [ 101 , 102 , 103 , 104 , 105 , 106 , 107 , 108 , 109 , 110 ], 'NAME' : [ 'Jagroop' , 'Praveen' , 'Harjot' , 'Pooja' , 'Rahul' , 'Nikita' , 'Saurabh' , 'Ayush' , 'Dolly' , "Mohit" ], 'BRANCH' : [ 'CSE' , 'CSE' , 'CSE' , 'CSE' , 'CSE' , 'CSE' , 'CSE' , 'CSE' , 'CSE' , 'CSE' ]}) # printing detailsprint (details) |
Выход:
ВТОРОЙ ТИП ДАННЫХ
Python3
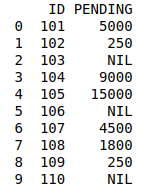
# Import moduleimport pandas as pd # Creating Dataframe for Fees_Statusfees_status = pd.DataFrame( { 'ID' : [ 101 , 102 , 103 , 104 , 105 , 106 , 107 , 108 , 109 , 110 ], 'PENDING' : [ '5000' , '250' , 'NIL' , '9000' , '15000' , 'NIL' , '4500' , '1800' , '250' , 'NIL' ]}) # Printing fees_statusprint (fees_status) |
Выход:
ИЗМЕНЕНИЕ ДАННЫХ ПРИ ИСПОЛЬЗОВАНИИ ОПЕРАЦИИ ОБЪЕДИНЕНИЯ:
Python3
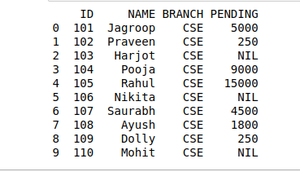
# Import moduleimport pandas as pd # Creating Dataframedetails = pd.DataFrame({ 'ID' : [ 101 , 102 , 103 , 104 , 105 , 106 , 107 , 108 , 109 , 110 ], 'NAME' : [ 'Jagroop' , 'Praveen' , 'Harjot' , 'Pooja' , 'Rahul' , 'Nikita' , 'Saurabh' , 'Ayush' , 'Dolly' , "Mohit" ], 'BRANCH' : [ 'CSE' , 'CSE' , 'CSE' , 'CSE' , 'CSE' , 'CSE' , 'CSE' , 'CSE' , 'CSE' , 'CSE' ]}) # Creating Dataframefees_status = pd.DataFrame( { 'ID' : [ 101 , 102 , 103 , 104 , 105 , 106 , 107 , 108 , 109 , 110 ], 'PENDING' : [ '5000' , '250' , 'NIL' , '9000' , '15000' , 'NIL' , '4500' , '1800' , '250' , 'NIL' ]}) # Merging Dataframeprint (pd.merge(details, fees_status, on = 'ID' )) |
Выход:
Преобразование данных с использованием метода группировки
Метод группировки в анализе данных используется для получения результатов с точки зрения различных групп, взятых из больших данных. Этот метод панд используется для группировки исходных данных из большого набора данных.
Пример: существует компания по продаже автомобилей, и эта компания имеет разные бренды различных компаний по производству автомобилей, таких как Maruti, Toyota, Mahindra, Ford и т. Д., И имеет данные о продаже разных автомобилей в разные годы. Таким образом, Компания хочет обрабатывать только те данные, по которым автомобили были проданы в течение 2010 года. Для этой проблемы мы используем другой метод борьбы, а именно метод groupby ().
ДАННЫЕ О ПРОДАЖЕ АВТОМОБИЛЕЙ:
Python3
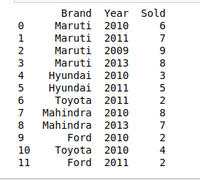
# Import moduleimport pandas as pd # Creating Datacar_selling_data = { 'Brand' : [ 'Maruti' , 'Maruti' , 'Maruti' , 'Maruti' , 'Hyundai' , 'Hyundai' , 'Toyota' , 'Mahindra' , 'Mahindra' , 'Ford' , 'Toyota' , 'Ford' ], 'Year' : [ 2010 , 2011 , 2009 , 2013 , 2010 , 2011 , 2011 , 2010 , 2013 , 2010 , 2010 , 2011 ], 'Sold' : [ 6 , 7 , 9 , 8 , 3 , 5 , 2 , 8 , 7 , 2 , 4 , 2 ]} # Creating Dataframe of car_selling_datadf = pd.DataFrame(car_selling_data) # printing Dataframeprint (df) |
Выход:
ДАННЫЕ ЗА 2010 ГОД:
Python3
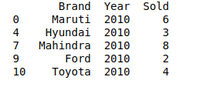
# Import mdouleimport pandas as pd # Creating Datacar_selling_data = { 'Brand' : [ 'Maruti' , 'Maruti' , 'Maruti' , 'Maruti' , 'Hyundai' , 'Hyundai' , 'Toyota' , 'Mahindra' , 'Mahindra' , 'Ford' , 'Toyota' , 'Ford' ], 'Year' : [ 2010 , 2011 , 2009 , 2013 , 2010 , 2011 , 2011 , 2010 , 2013 , 2010 , 2010 , 2011 ], 'Sold' : [ 6 , 7 , 9 , 8 , 3 , 5 , 2 , 8 , 7 , 2 , 4 , 2 ]} # Creating Dataframe for Provided Datadf = pd.DataFrame(car_selling_data) # Group the data when year = 2010grouped = df.groupby( 'Year' )print (grouped.get_group( 2010 )) |
Выход:
Преодоление данных путем удаления дублирования
Метод Pandas duplicates () помогает нам удалить повторяющиеся значения из больших данных. Важной частью Data Wrangling является удаление повторяющихся значений из большого набора данных.
Синтаксис:
DataFrame.duplicated (подмножество = Нет, сохранить = 'первый')
Здесь подмножество - это значение столбца, из которого мы хотим удалить повторяющееся значение.
В общем , у нас есть 3 варианта:
- если keep = 'first', то первое значение будет помечено как исходное, все значения, если они возникнут, будут удалены, так как они будут считаться повторяющимися.
- если keep = 'last', то последнее значение помечается как исходное, все вышеуказанные значения будут удалены, так как они считаются повторяющимися значениями.
- Если keep = 'false', все значения, встречающиеся более одного раза, будут удалены, так как все они будут считаться повторяющимися значениями.
Например, мероприятие организует университет. Для участия Студенты должны заполнить свои данные в онлайн-форме, чтобы они могли связаться с ними. Вполне возможно, что студент заполнит форму несколько раз. Если один студент заполнит несколько заявок, это может вызвать трудности у организатора мероприятия. Данные, которые получат организаторы, можно легко изменить, удалив повторяющиеся значения.
ПОДРОБНАЯ ИНФОРМАЦИЯ ОБ УЧАЩИХСЯХ, КОТОРЫЕ ХОТЯТ УЧАСТВОВАТЬ В МЕРОПРИЯТИИ:
Python3
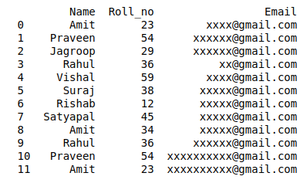
# Import moduleimport pandas as pd # Initializing Datastudent_data = { 'Name' : [ 'Amit' , 'Praveen' , 'Jagroop' , 'Rahul' , 'Vishal' , 'Suraj' , 'Rishab' , 'Satyapal' , 'Amit' , 'Rahul' , 'Praveen' , 'Amit' ], 'Roll_no' : [ 23 , 54 , 29 , 36 , 59 , 38 , 12 , 45 , 34 , 36 , 54 , 23 ], 'Email' : [ 'xxxx@gmail.com' , 'xxxxxx@gmail.com' , 'xxxxxx@gmail.com' , 'xx@gmail.com' , 'xxxx@gmail.com' , 'xxxxx@gmail.com' , 'xxxxx@gmail.com' , 'xxxxx@gmail.com' , 'xxxxx@gmail.com' , 'xxxxxx@gmail.com' , 'xxxxxxxxxx@gmail.com' , 'xxxxxxxxxx@gmail.com' ]} # Creating Dataframe of Datadf = pd.DataFrame(student_data) # Printing Dataframeprint (df) |
Выход:
ДАННЫЕ, ПЕРЕПАДАЕМЫЕ ПРИ УДАЛЕНИИ ДВОЙНЫХ ЗАПИСЕЙ:
Python3
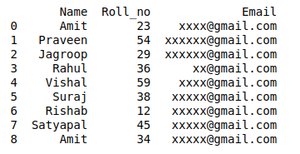
# import moduleimport pandas as pd # initializing Datastudent_data = { 'Name' : [ 'Amit' , 'Praveen' , 'Jagroop' , 'Rahul' , 'Vishal' , 'Suraj' , 'Rishab' , 'Satyapal' , 'Amit' , 'Rahul' , 'Praveen' , 'Amit' ], 'Roll_no' : [ 23 , 54 , 29 , 36 , 59 , 38 , 12 , 45 , 34 , 36 , 54 , 23 ], 'Email' : [ 'xxxx@gmail.com' , 'xxxxxx@gmail.com' , 'xxxxxx@gmail.com' , 'xx@gmail.com' , 'xxxx@gmail.com' , 'xxxxx@gmail.com' , 'xxxxx@gmail.com' , 'xxxxx@gmail.com' , 'xxxxx@gmail.com' , 'xxxxxx@gmail.com' , 'xxxxxxxxxx@gmail.com' , 'xxxxxxxxxx@gmail.com' ]} # creating dataframedf = pd.DataFrame(student_data) # Here df.duplicated() list duplicate Entries in ROllno.# So that ~(NOT) is placed in order to get non duplicate values.non_duplicate = df[~df.duplicated( 'Roll_no' )] # printing non-duplicate valuesprint (non_duplicate) |
Выход:
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.