НЛП | Словосочетания
Словосочетания - это два или более слов, которые часто встречаются вместе, например, Соединенные Штаты . Есть много других слов, которые могут идти после United, например United Kingdom и United Airlines. Как и во многих других аспектах обработки естественного языка, контекст очень важен. А для словосочетаний контекст - это все.
В случае словосочетаний контекстом будет документ в виде списка слов. Обнаружение словосочетаний в этом списке слов означает поиск общих фраз, которые часто встречаются по всему тексту.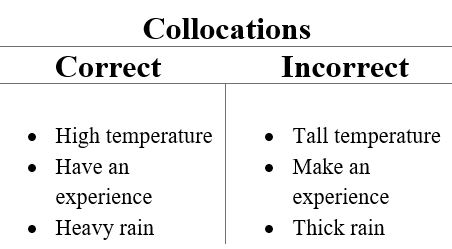
Ссылка на ДАННЫЕ - Монти Пайтон и скрипт Святого Грааля
Код # 1: загрузка библиотек
from nltk.corpus import webtext # use to find bigrams, which are pairs of wordsfrom nltk.collocations import BigramCollocationFinderfrom nltk.metrics import BigramAssocMeasures |
Код # 2: давайте найдем словосочетания
# Loading the datawords = [w.lower() for w in webtext.words( 'C:\Geeksforgeeks\python_and_grail.txt' )] biagram_collocation = BigramCollocationFinder.from_words(words)biagram_collocation.nbest(BigramAssocMeasures.likelihood_ratio, 15 ) |
Выход :
[("'",' s '),
('артур', ':'),
('#', '1'),
("'",' t '),
('крестьянин', '#'),
('#', '2'),
(']', '['),
('1', ':'),
('ой', ', '),
('черный рыцарь'),
('ха', 'ха'),
(':', 'ой'),
("'",' re '),
('галахад', ':'),
('хорошо', ', ')]
Как видно из приведенного выше кода, поиск размещения таким образом не очень полезен. Итак, приведенный ниже код представляет собой усовершенствованную версию, в которой добавлен фильтр слов для удаления знаков препинания и игнорируемых слов.
Код № 3:
from nltk.corpus import stopwords stopset = set (stopwords.words( 'english' ))filter_stops = lambda w: len (w) < 3 or w in stopset biagram_collocation.apply_word_filter(filter_stops)biagram_collocation.nbest(BigramAssocMeasures.likelihood_ratio, 15 ) |
Выход :
[('черный рыцарь'),
('clop', 'clop'),
('голова', 'рыцарь'),
('бормотать', 'бормотать'),
(писк, писк),
('пила', 'пила'),
('Святой Грааль'),
('убегать'),
('французский', 'охранник'),
('мультипликационный персонаж'),
('iesu', 'домина'),
('пирог', 'iesu'),
('круглый стол'),
('сэр', 'робин'),
('хлопать', 'хлопать')]
Как это работает в коде?
- BigramCollocationFinder строит два частотных распределения:
- по одному на каждое слово
- другой для биграмм.
- Частотное распределение - это, по сути, расширенный словарь Python, где ключи - это то, что подсчитывается, а значения - это счетчики.
- Любые функции фильтрации уменьшают размер, удаляя любые слова, не прошедшие фильтр.
- Использование функции фильтрации для удаления всех слов, состоящих из одного или двух символов, и всех запрещенных слов на английском языке, приводит к гораздо более чистому результату.
- После фильтрации средство поиска словосочетаний готово к поиску словосочетаний.
Код № 4: Работа с тройками вместо пар.
# Loading Librariesfrom nltk.collocations import TrigramCollocationFinderfrom nltk.metrics import TrigramAssocMeasures # Loading data - text filewords = [w.lower() for w in webtext.words( 'C:Geeksforgeeks\python_and_grail.txt' )] trigram_collocation = TrigramCollocationFinder.from_words(words)trigram_collocation.apply_word_filter(filter_stops)trigram_collocation.apply_freq_filter( 3 ) trigram_collocation.nbest(TrigramAssocMeasures.likelihood_ratio, 15 ) |
Выход :
[('clop', 'clop', 'clop'),
('бормотать', 'бормотать', 'бормотать'),
(«писк», «писк», «писк»),
('пила', 'пила', 'пила'),
('пирог', 'iesu', 'домина'),
('хлопать', 'хлопать', 'хлопать'),
('dona', 'eis', 'реквием'),
('храбрый', 'сэр', 'робин'),
('хе', 'хе', 'хе'),
('король', 'артур', 'музыка'),
('хи', 'хи', 'хи'),
('святая', 'рука', 'граната'),
('бум бум бум'),
('...', 'dona', 'eis'),
('уже', 'получил', 'один')]
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.